Based on DVC: An End-to-end Deep Video Compression Framework(CVPR 2019)
主要贡献:
- 压缩特征的残差而不是像素的残差
- 把像素级和特征级的残差塞在一个模型里来提高性能
- 一步步的训练,提高训练效率
Overall Framework和DVC差不多,下面是亿点细节:
- 运动估计: 用PWC-Net来做运动估计,当前帧(target frame) (x_1)和上一帧(reference frame) (x_0) 喂到网络里,输出运动信息(f)
- 运动压缩: 用Variational image compression with a scale hyperprior中的基于VAE和factorized-prior模型来运动压缩,并用残差模块代替GDN并且加了一个下采样层。说这是因为光流中的空间冗余比图像中的要高很多。通过运动压缩得到重建光流(hat{f})
- 运动补偿: 和DVC一样的运动补偿方法,reference frame (x_0) 和重建光流(hat{f})共同得到预测帧(overline{x}_1)
- 残差压缩: 像素级/特征级两种残差压缩方法,这个后面再聊
- 后处理:最后接Grdn: Grouped residual dense network for real image denoising and gan-based real-world noise modeling中的GRDN进行图像增强
Residual Compression Methods:
Pixel-level/Feature-level

Framework of residual compression in feature space
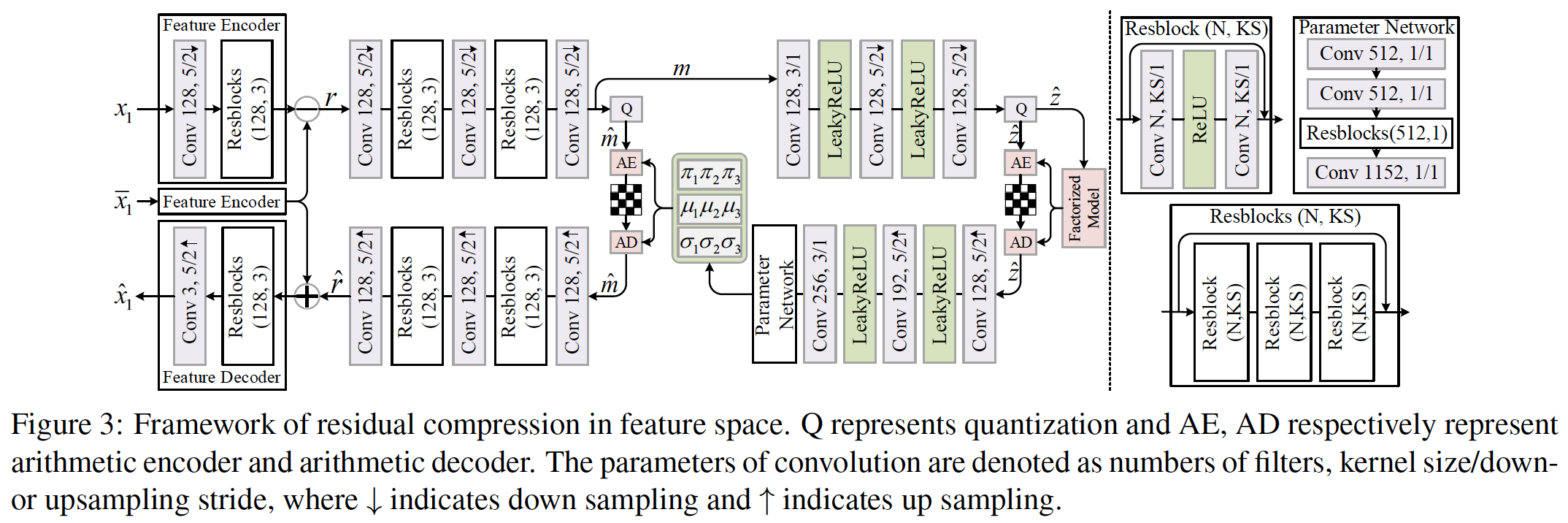
网络结构参考了Variational image compression with a scale hyperprior中图像压缩的结构
左边都没问题,右边那一坨是什么?
A non-parametric, fully factorized density model
用来估计超先验(hat{z})的分布
(hat{z})是啥玩意儿?
每个潜变量(hat{m}_i)的概率分布遵循下面这样一个单位均匀分布的高斯混合卷积(Gaussian Mixture convolved with a unit uniform distribution):
实验中(K=3)
DVC用了End-to-end optimized image compression中的方法, 在训练阶段加入均匀噪声代替数字化运算。这篇论文:那我+1
但是为什么会有Feature-level这个东西?是因为pixel-level的残差对运动补偿的error非常敏感。但如果我运动补偿没啥误差呢?要你何用?
论文先分别训练这两种方法,验证时先都压缩一下,再在给定目标比特率的前提下通过knapsack solver选一个更好的 (knapsack solver?背包求解器?怎么选的?)
损失函数: 同DVC, 过
Step-by-step Training:
训的时候一步一步来
- pre-train
pre-train的时候先训练运动压缩和运动补偿网络,然后把PWC-Net的参数固定(把它训好的copy过来),然后加入残差压缩网络,用一个很大的参数(lambda)来联合训练。后处理网络在学到的图像编解码器上预训练。
- finetune
用不同的(lambda)来jointly finetune所有的模块