前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于青灯编程 ,作者:清风
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542基本开发环境
- Python 3.6
- Pycharm
相关模块的使用
import time
import os
import re
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options目标网页分析
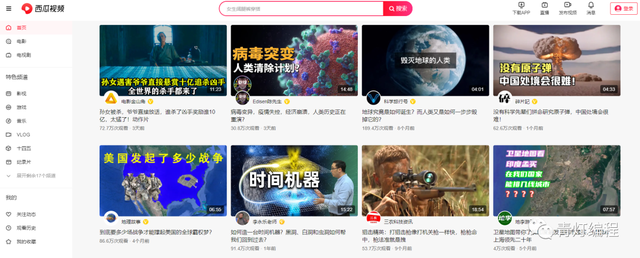
如何获取视频地址
西瓜视频有两种:
1、有水印视频
2、无水印视频
有水印视频
在网页源代码中
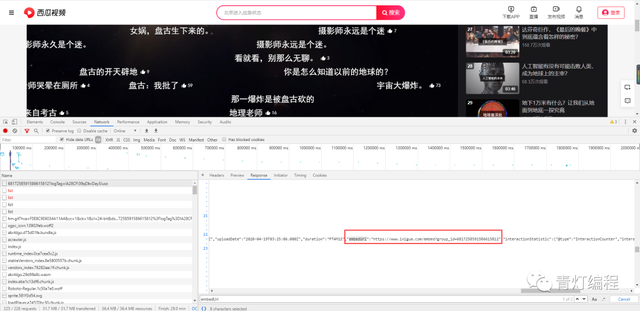
https://www.ixigua.com/embed?group_id=6817258591586615812这个链接点击进去是视频播放地址。
前端页面中已有视频真实地址
//v9-xg-web-s.ixigua.com/ac99e1bf75dd0faa6854d9e5367fac3f/5fe894d7/video/tos/cn/tos-cn-ve-4/626cf09c0830417da4b70982950cedd9/?a=1768&br=3891&bt=1297&cd=0%7C0%7C0&cr=0&cs=0&cv=1&dr=0&ds=3&er=0&l=20201227210214010204050203275E2F92&lr=default&mime_type=video_mp4&qs=0&rc=anQ3aWdzNjd2dDMzZjczM0ApPDQ2NjU8aGU3NzplMzZoNWdfMWguMmA0NWFfLS02LS9zczIwXjBfY2A2MmIvXjMyLjI6Yw%3D%3D&vl=&vr=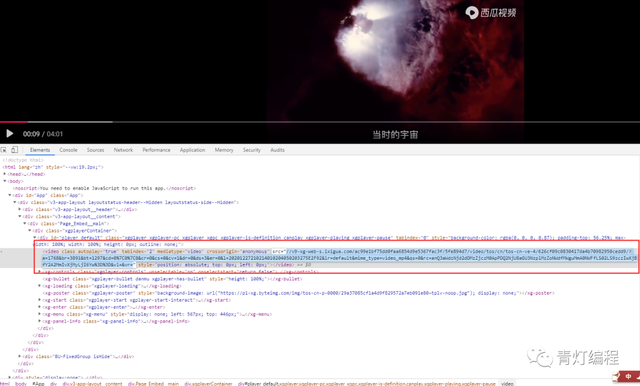

只要请求这个网址即可下载保存视频。
无水印视频
无水印的视频下载比较麻烦,首先它是音频和视频画面分离的

水印是没有水印,但是视频是没有声音的。

如何找音频和视频地址呢?
使用开发者工具,在XHR里面是有相对对应链接的
音频地址:
https://v9-xg-web-s.ixigua.com/79457295a8a89bf86bdcd157eb848175/5fe895f4/video/tos/cn/tos-cn-vd-0026/43771a1a38ea473d9cb5b8e7c0f651f3/media-audio-und-mp4a/?a=1768&br=0&bt=0&cd=0%7C0%7C0&cr=0&cs=0&cv=1&dr=0&ds=&er=0&l=20201227210659010028033025224FC377&lr=default&mime_type=video_mp4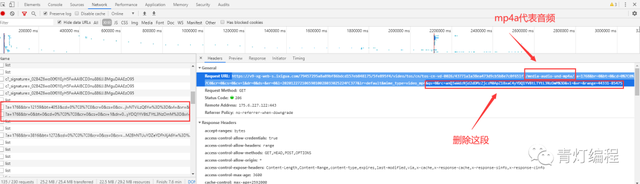
视频画面地址:
https://v9-xg-web-s.ixigua.com/9b4e18f3b29244557c83b8e88f13dd1b/5fe895f4/video/tos/cn/tos-cn-vd-0026/86a41ef8ebd3496585db455ae56b3ff3/media-video-avc1/?a=1768&br=12159&bt=4053&cd=0%7C0%7C0&cr=0&cs=0&cv=1&dr=0&ds=4&er=0&l=20201227210659010028033025224FC377&lr=default&mime_type=video_mp4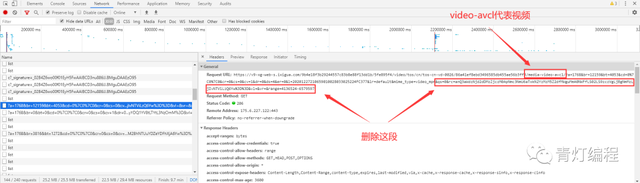
所以如果想要爬取西瓜视频无水印版本的话,不仅要下载视频,还要下载音频,然后再合成视频和音频两个文件,和之前的爬取B视频有相似之处。
西瓜视频水印版本下载
1、获取源代码提取视频播放地址以及标题
def main(html_url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
play_url = re.findall('"embedUrl":"(.*?)"', response.text)[0]
title = re.findall('<title data-react-helmet="true">(.*?)</title>', response.text)[0].replace(' - 西瓜视频', '')2、获取视频真实下载地址
这里使用selenium主要是因为,链接的变化规律问题。每次请求网页的参数都不一样,比较难以分析,但是前端网页中是有显示真实的视频地址,所以可以使用selenium直接提取。
def get_video_url(html_url):
"""传入播放地址,获取视频下载地址"""
chrome_options = Options()
chrome_options.add_argument('--headless')
os.system("taskkill /f /im chromedriver.exe")
driver = webdriver.Chrome(executable_path='chromedriver.exe', options=chrome_options)
driver.get(html_url)
driver.implicitly_wait(10)
video_url = driver.find_element_by_css_selector('#player_default video').get_attribute('src')
driver.close()
return video_url3、视频下载保存
方式一:正常保存方式
def save(video_url, video_title):
filename = 'video\' + video_title + '.mp4'
video_headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
video_response = requests.get(url=video_url, headers=video_headers).content
with open(filename, mode='wb') as f:
f.write(video_response)
print('正在下载保存:', video_title)运行效果:
方式二:实现下载进度条
def progressbar(video_url, video_title):
start = time.time() # 下载开始时间
response = requests.get(video_url, stream=True) # stream=True必须写上
size = 0 # 初始化已下载大小
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 下载文件总大小
try:
if response.status_code == 200: # 判断是否响应成功
print('Start download,[File size]:{size:.2f} MB'.format(
size=content_size / chunk_size / 1024)) # 开始下载,显示下载文件大小
filepath = 'video\' + video_title + '.mp4' # 设置图片name,注:必须加上扩展名
with open(filepath, 'wb') as file: # 显示进度条
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
print('[下载进度]:%s%.2f%%' % ('▇' * int(size * 50 / content_size), float(size / content_size * 100)),
end='
')
end = time.time() # 下载结束时间
print('Download completed!,times: %.2f秒' % (end - start)) # 输出下载用时时间
print(f'视频【 {video_title} 】已经保存完毕')
except:
print('Error')运行效果:
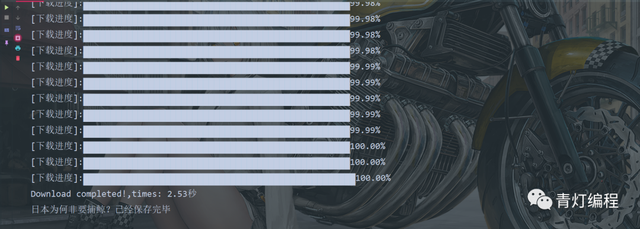
只要输入视频的ID即可下载视频,之后也可以做一个简单GUI桌面应用软件,之前文章都是有写过类似的。
完整代码
import time
import os
import re
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def get_video_url(html_url):
"""传入播放地址,获取视频下载地址"""
chrome_options = Options()
chrome_options.add_argument('--headless')
os.system("taskkill /f /im chromedriver.exe")
driver = webdriver.Chrome(executable_path='chromedriver.exe', options=chrome_options)
driver.get(html_url)
driver.implicitly_wait(10)
video_url = driver.find_element_by_css_selector('#player_default video').get_attribute('src')
driver.close()
return video_url
# def save(video_url, video_title):
# filename = 'video\' + video_title + '.mp4'
# video_headers = {
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
# }
# video_response = requests.get(url=video_url, headers=video_headers).content
# with open(filename, mode='wb') as f:
# f.write(video_response)
# print('正在下载保存:', video_title)
def progressbar(video_url, video_title):
start = time.time() # 下载开始时间
response = requests.get(video_url, stream=True) # stream=True必须写上
size = 0 # 初始化已下载大小
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 下载文件总大小
try:
if response.status_code == 200: # 判断是否响应成功
print('Start download,[File size]:{size:.2f} MB'.format(
size=content_size / chunk_size / 1024)) # 开始下载,显示下载文件大小
filepath = 'video\' + video_title + '.mp4' # 设置图片name,注:必须加上扩展名
with open(filepath, 'wb') as file: # 显示进度条
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
print('[下载进度]:%s%.2f%%' % ('▇' * int(size * 50 / content_size), float(size / content_size * 100)),
end='
')
end = time.time() # 下载结束时间
print('Download completed!,times: %.2f秒' % (end - start)) # 输出下载用时时间
print(f'视频【 {video_title} 】已经保存完毕')
except:
print('Error')
def main(html_url):
headers = {
'cookie': '输入你自己的cookie',
'referer': 'https://www.ixigua.com/?wid_try=1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
play_url = re.findall('"embedUrl":"(.*?)"', response.text)[0]
title = re.findall('<title data-react-helmet="true">(.*?)</title>', response.text)[0].replace(' - 西瓜视频', '')
video_url = get_video_url(play_url)
progressbar(video_url, title)
if __name__ == '__main__':
video_id = input('请输入你要下载的视频ID:')
url = f'https://www.ixigua.com/{video_id}'
main(url)