上篇请访问这里做一个能对标阿里云的前端APM工具(上)
样本多样性问题
上一小节中的实施方案是微观的,即单次性的、具体的。但是从宏观上看,我需要保证性能测试是公允的,符合大众预期的。为了达到这种效果,最简单的方式就是保证测试的多样性,让足够多人访问产生足够多的样本来,但这对于一个为个人服务的工具网站来说是不现实的。
于是我打算借助机器的力量,在世界各地建造机器人程序来模拟访问。机器人程序原理非常简单,借助 headless chrome 来模拟用户的访问:
const url = 'https://www.site2share.com/folder/20020507';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
await page.waitForSelector('.single-folder-container');
await page.waitForTimeout(1000 * 30);
browser.close();
注意程序会等到 .single-folder-container 元素出现之后才进入关闭流程,在关闭前会等待30秒钟来保证有足够的时间将指标数据上传到 Application Insights。
为了达到重复访问的效果,我给机器人制定的执行策略非常简单,每五分钟执行一次。这种轻量级的定时任务应用非常适用于部署在 Azure Serverless 上,同时 Azure Serverless 也支持在部署时指定区域,这样就能达到模拟全球不同地区访问的效果
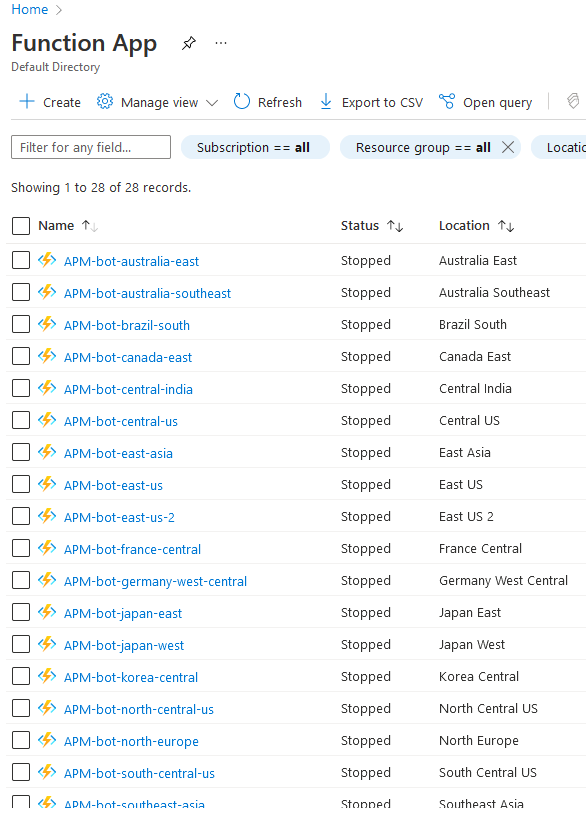
虽然每一个 Serverless Function 都能配置独立的执行间隔,但考虑到可维护性,比如将来希望将5分钟执行间隔提高到2分钟时不去修改27里的每一个 function,我决定将所有 function 交给 Azure Logic App 进行管理
Azure Logic App 在我看来是一款可视化低代码工具。它能够允许非编程人员以点击拖拽的形式创建工作流。初始化变量、分支判断、循环、响应或者发送网络请求,都可以仅用鼠标办到。
我们的场景总结下来就两句话:
- 距离上次进行性能测试是不是已达五分钟
- 如果是的话再次发送性能测试请求
那么我们可以依次创建一套工作流
- 工作流的触发器为一个定时任务,每十分钟执行一次
- 定时任务执行时连带执行所有的 Azure Function
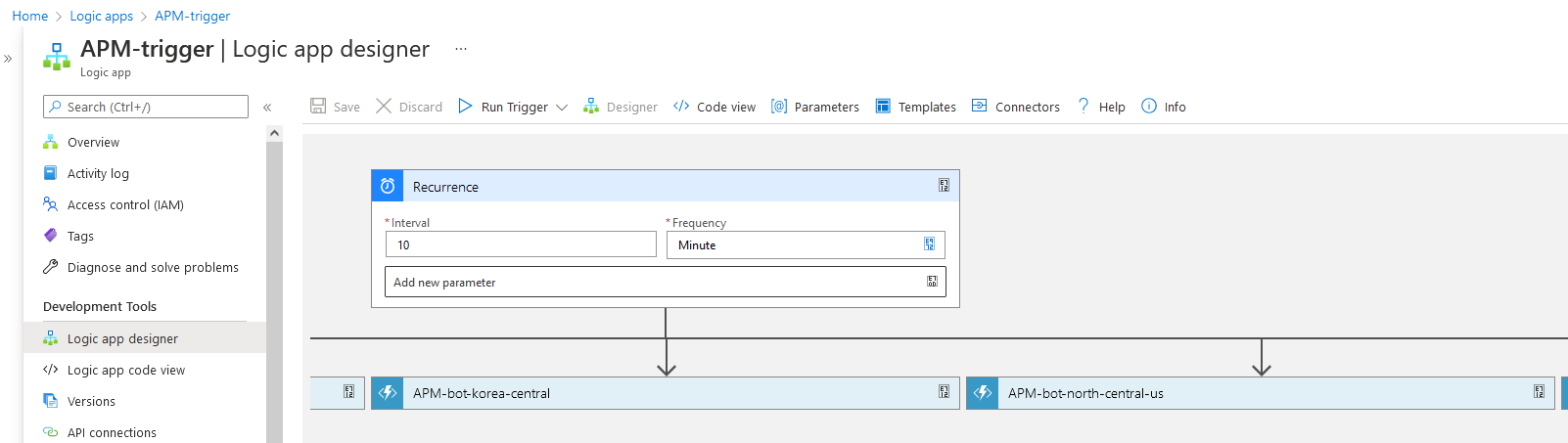
Azure Logic App 还会将每次的执行情况记录下来,甚至每个函数的输入和输出,某种意义上这也起到了监控执行的作用
审视数据,发现问题
工具开发完成之后不间断的运行了七天,这七天时间内共产生了 219613 条数据。看看我们能从这二十万数据钟能发现什么
首先我们要看一个最重要的指标:关键元素的出现时机
customMetrics
| where timestamp between (datetime(2022-02-01) .. datetime(2022-02-06))
| where name has 'folder-detail:visible'
| extend location =strcat(client_City, ":", client_StateOrProvince, ":", client_CountryOrRegion)
| summarize metric_count=count(), avg_duration=round(avg(valueMax)) by location
| where metric_count > 100
| order by avg_duration asc
指标数据我按照国家地区排序,在我看来地区会是影响速度的关键因素,最终结果如下。抱歉我使用的名称是 avg_duration 这个有误导的名称,实际上这个指标应该是一个 startTime,即从浏览器开始加载页面的开始为起点,到看到元素的时间。下面的 first-contentful-paint 同理
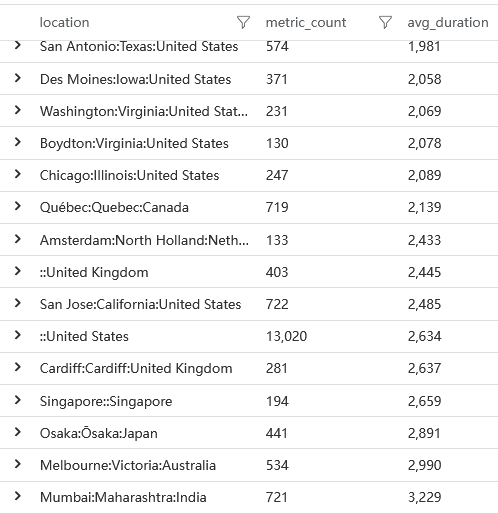
从肉眼上我们可以感知到,大部分用户会在3秒左右才会看到实质性内容。接下来我们要做的就是探索3秒钟的时间去哪了。
顺便也可以查询一下浏览器提供的 first-contentful-paint 数据如何。上面的查询语句在之后会频繁被用到,所以我们可以提取一个函数出来
let queryMetricByName = (inputName: string) {
customMetrics
| where timestamp between (datetime(2022-02-01) .. datetime(2022-02-06))
| where name has inputName
| extend location =strcat(client_City, ":", client_StateOrProvince, ":", client_CountryOrRegion)
| summarize metric_count=count(), avg_duration=round(avg(valueMax)) by location
| where metric_count > 100
| order by avg_duration asc
};
接着用这个函数查询 first-contentful-paint 指标
queryMetricByName('browser:first-contentful-paint')
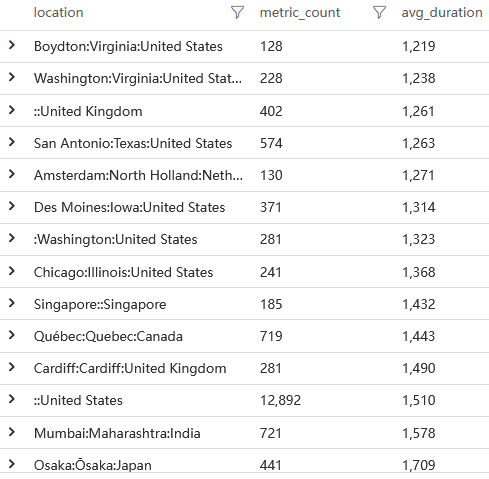
浏览器认为用户在 1.5 秒左右就看到了一些有用的内容了,但是从我们刚刚查询到的关键元素出现时机看来并非如此
我们先看看脚本的资源加载情况,以 runtime 脚本为例,我们看看它的平均加载时间
queryMetricByName('resource:script:https://www.site2share.com/runtime-es2015.ffba78f539fb511f7b4b.js')
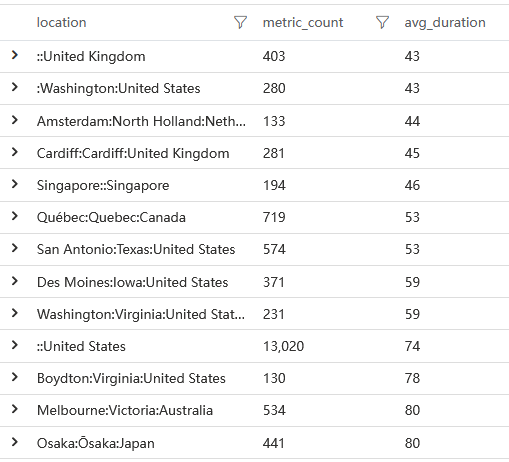
平均时间不过 100ms
而 http 请求指标数据呢
queryMetricByName('resource:xmlhttprequest')
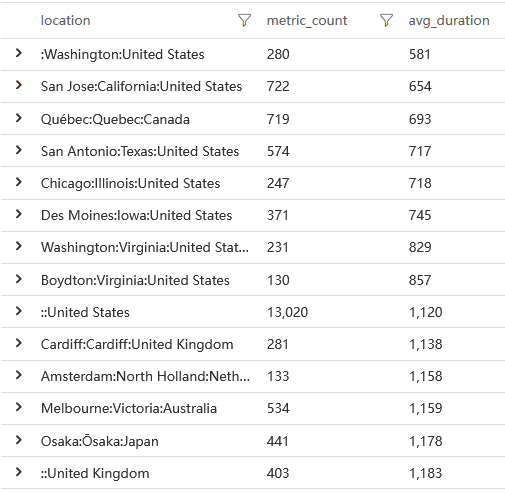
相比资源加载而言,平均1s的请求时长已经是资源加载时长的好几倍了,它有很大的嫌疑。接着我们继续看后端 SQL 查询数据性能
queryMetricByName('APM:GET_SINGLE_FOLDER:FIND_BY_ID')

首先要理解一下为什么这里只有一类地理位置的数据,因为之前所有的前端数据都又不同地区的机器人感知产生。因为我的后端服务器只有一台。虽然机器人从世界各地访问,但是查询总发生在这一台服务器上
这里就很有意思了。也就是说平均请求时间我们需要花上一秒钟,但是实际的 SQL 查询时间只需要100毫秒
为了还原犯罪事实,我们不妨从选取一次具体的请求,看看从后端到前端的时间线是怎么样的。这个时候 Application Insights 的 Telementry Correlation 的功能就体现出来了,我们只需要指定一个 operation_id 即可
(requests | union dependencies | union pageViews | union customMetrics)
| where timestamp > ago(90d)
| where operation_Id == "57b7b55cda794cedb9e016cec430449e"
| extend fetchStart = customDimensions.fetchStart
| project timestamp, itemType, name, valueSum, fetchStart, id, operation_ParentId, operation_Id, customDimensions
| order by timestamp asc
我们于是得到了所有的结果
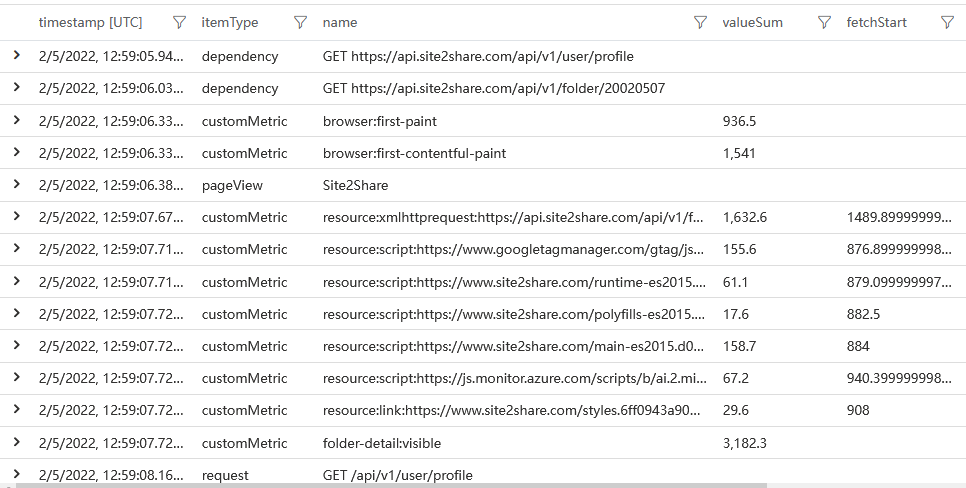
我们只需要 fetchStart 和 valueSum (也就是 duration) 就可以把整个流程图画出来
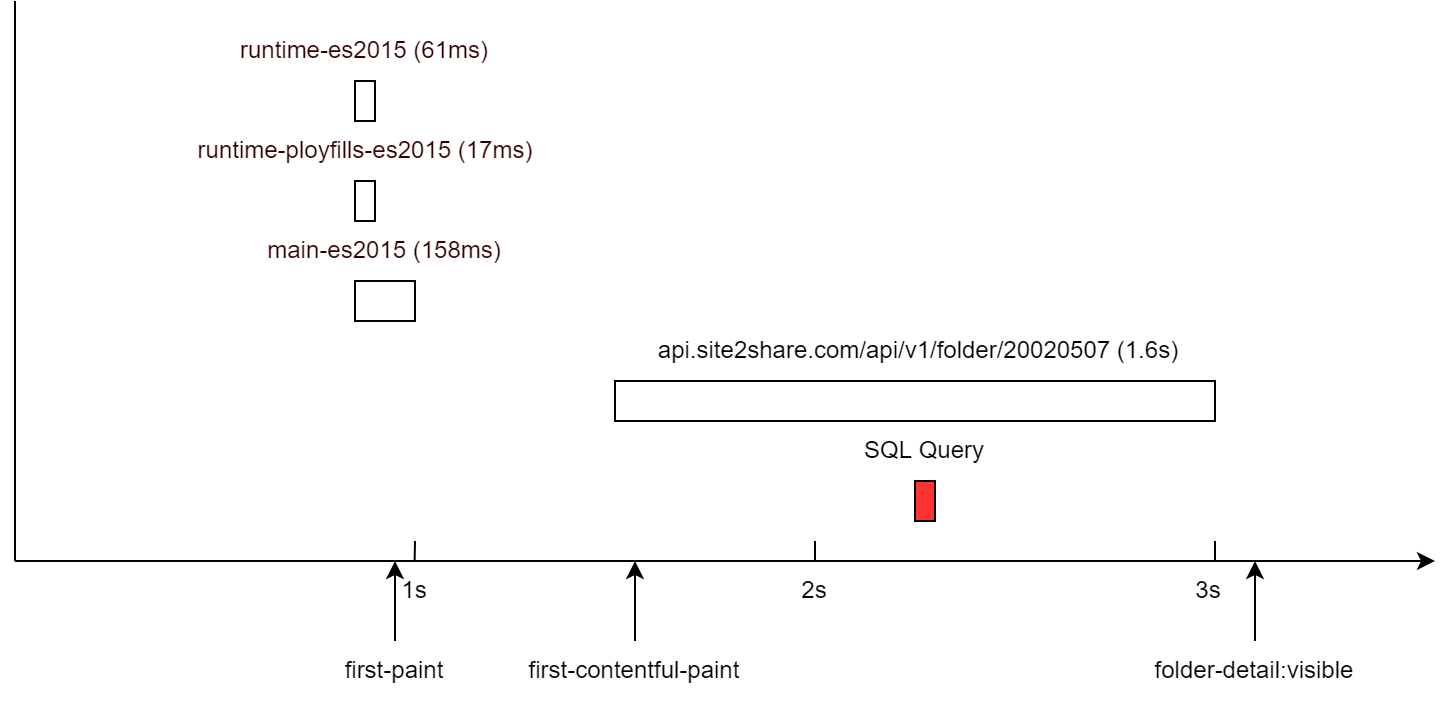
脚本资源在1s钟之内就加载完毕了。很明显,瓶颈在于接口的 RTT(Round-Trip Time)太长。抱歉没钱在世界各地部署后端节点。
总结
我自己写到这里觉得这篇文章有炫技或者是多此一举的嫌疑。因为即使没有这套工具。凭借工程师的经验,你也应该大致能猜到问题出在哪。
首先肯定不会是前端资源,一方面在多次访问的场景中浏览器的缓存机制不会让资源加载成为瓶颈;其次前端我使用的是 Azure Static Web App 服务,在 Azure CDN 的加持下即使是首次访问静态资源也不会是问题
至于 SQL 性能,你一定要相信商用的 MySQL 性能绝对比你本地开发环境的 MySQL 性能还要好。对这种体量的应用和查询来说,你的代码想把查询性能变得很差都很难。
所以问题只可能出现在接口的 RTT 上。
但我不认为这个方案无价值可言,对于我个人来说一个切实可行且能够落地的代码会比所谓摘抄自教科书上所谓的业界方案更重要;另一方面我在这个方案上看到了很多种可能性,比如它可以支持更多种类的指标采集,又比如利用 Headless Chrome 自带的开发者工具我们可以洞见更多网站潜在的性能问题,也许者几十万条数据还能够帮助我们预测某时某刻的性能状况。
对比阿里
阿里云有两个工具我们可以拿来对比,一个是阿里云的前端前端性能监控工具
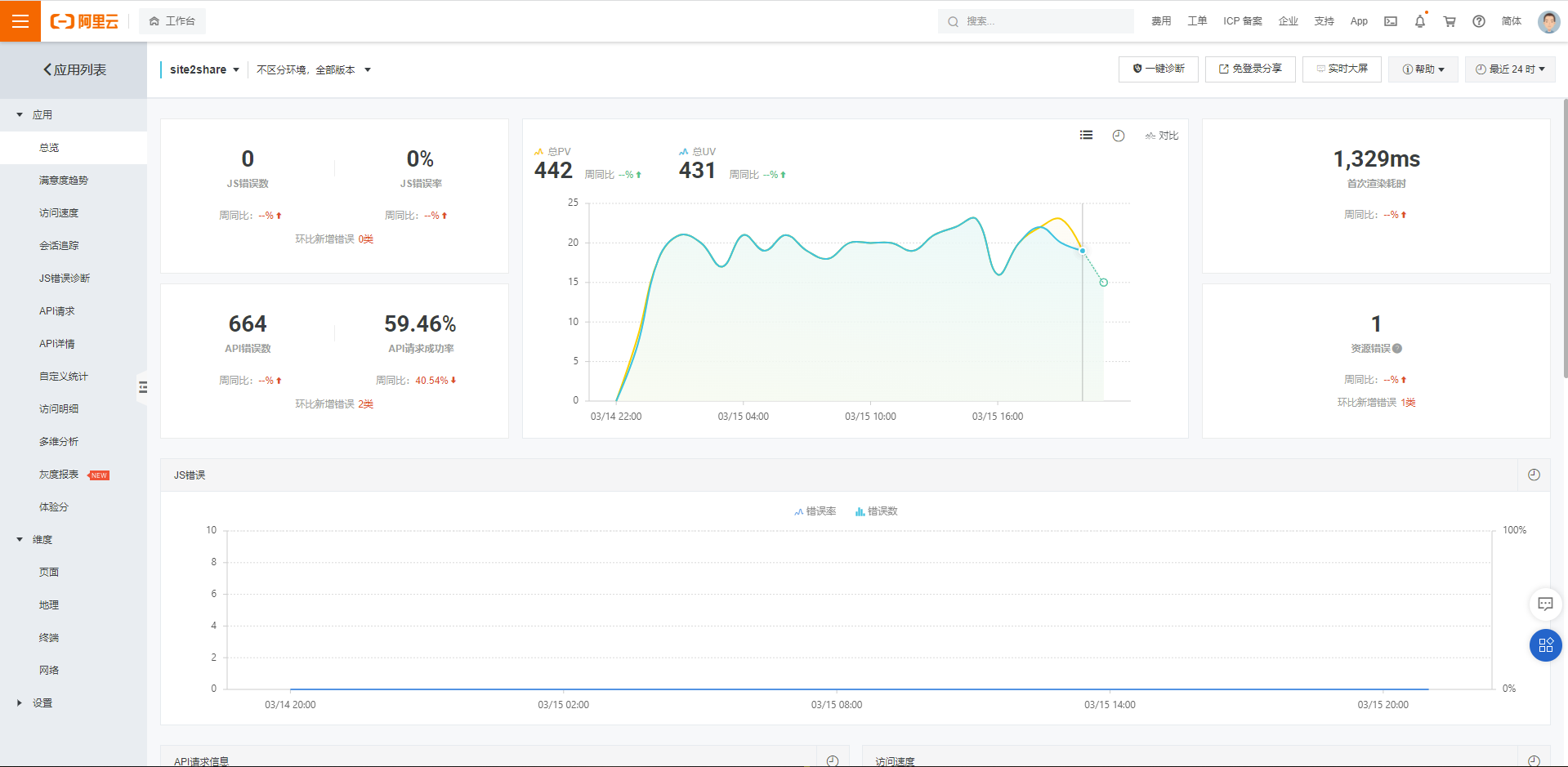
我没法将整个页面截图给你,但是总体看来,统计的信息有
• JS错误信息
• API请求信息
• PV/UV
• 页面性能(首次渲染耗时,完全加载时间)
• 访问的各个维度(地理位置、网络、终端分布)
从上图的左侧子菜单可以看出,对每一类信息它都已经给出了预订制的报告详情。你可以把它理解为对于 Application Insights 数据进行加工后显得对人类更友好的产品。因为 Application Insights 是非常底层存储于表中的数据,你需要自己编写查询语句然后生成报表
另一个和我们功能很像的工具是云拨测,在这个工具内你可以选择测试发起的城市,来看看不同人群对于你网站的性能体验如何。比如我选择了美国和北京
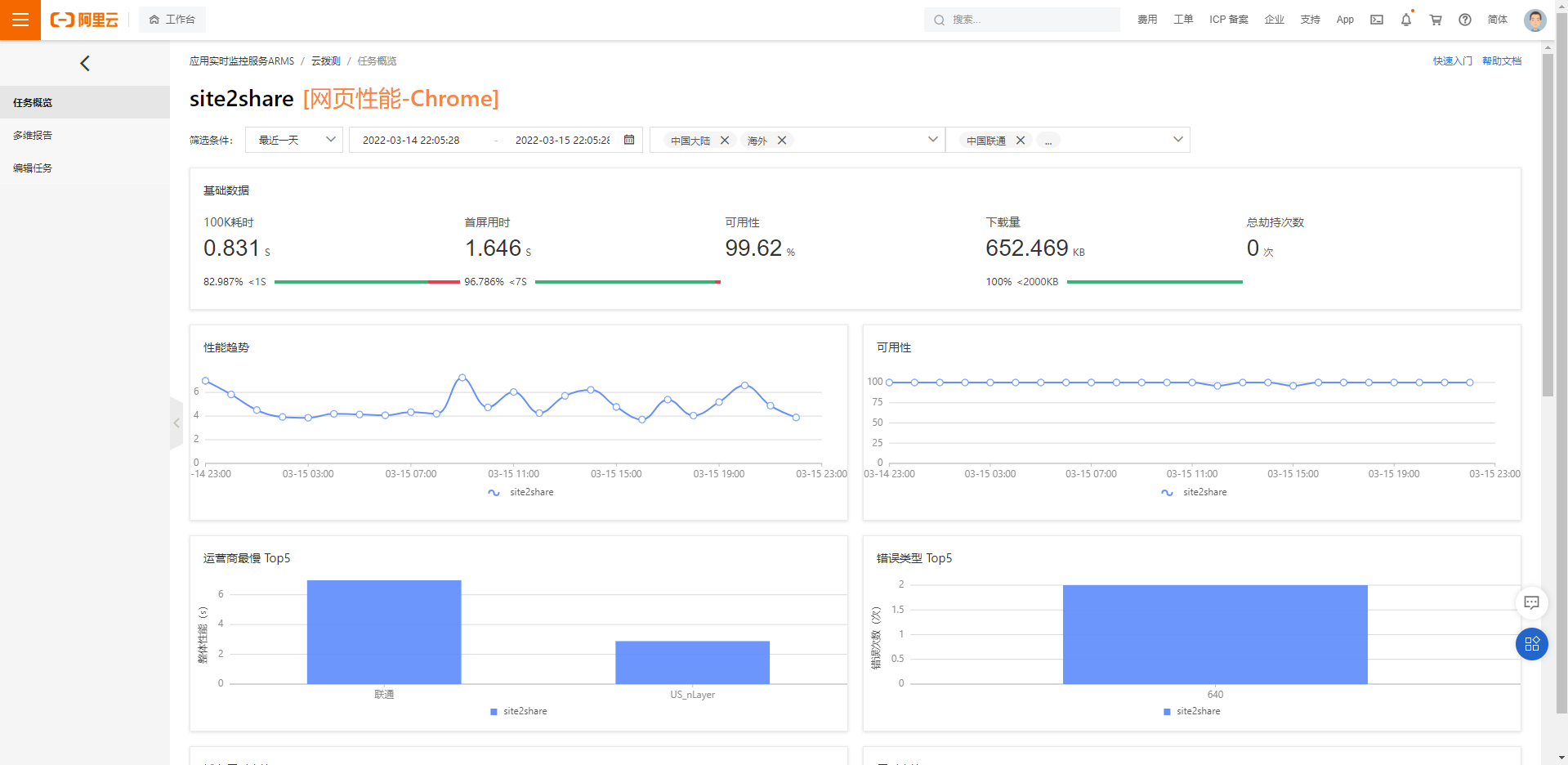
甚至对于每一次访问,我们都能看到它的详细数据,甚至包括我们之前说的 DNS 的情况
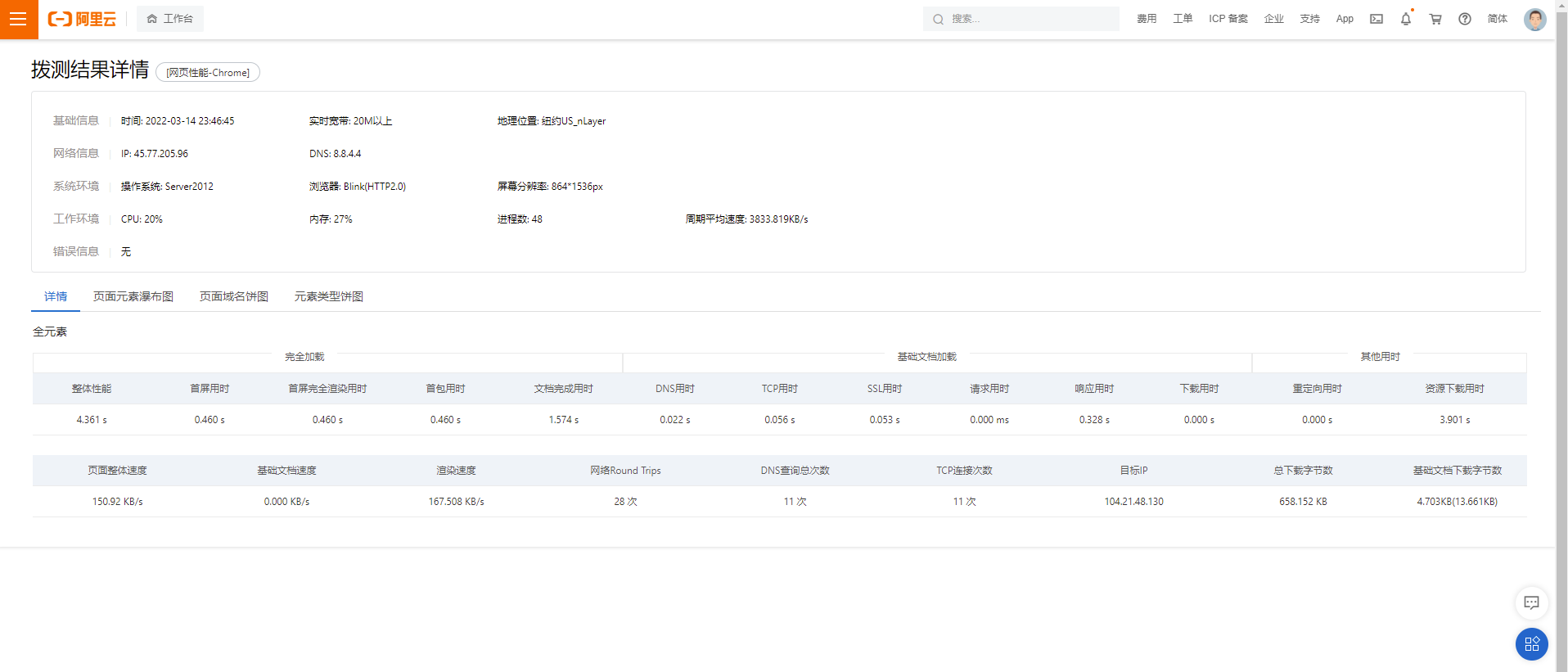
如此强大的功能不是我个人开发出的工具能够匹敌的。
但是面对这些无所不能的工具,假设它们能把成千上百个指标准确的呈现在你面前,我想问的是,你真的需要它们吗?或者说,你关心的究竟是什么?
你可能会喜欢: