MapReduce实战PageRank算法
实验目的
1.了解PageRank
2.学习MapReduce PageRank算法
实验原理
PageRank:网页排名,右脚网页级别。是以Google 公司创始人Larry Page 之姓来命名。PageRank 计算每一个网页的PageRank值,并根据PageRank值的大小对网页的重要性进行排序。
PageRank的基本思想:
1.如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高
2.如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。
PageRank的算法原理:
PageRank算法总的来说就是预先给每个网页一个PR值,由于PR值物理意义上为一个网页被访问概率,所以一般是1/N,其中N为网页总数。另外,一般情况下,所有网页的PR值的总和为1。如果不为1的话也不是不行,最后算出来的不同网页之间PR值的大小关系仍然是正确的,只是不能直接地反映概率了。
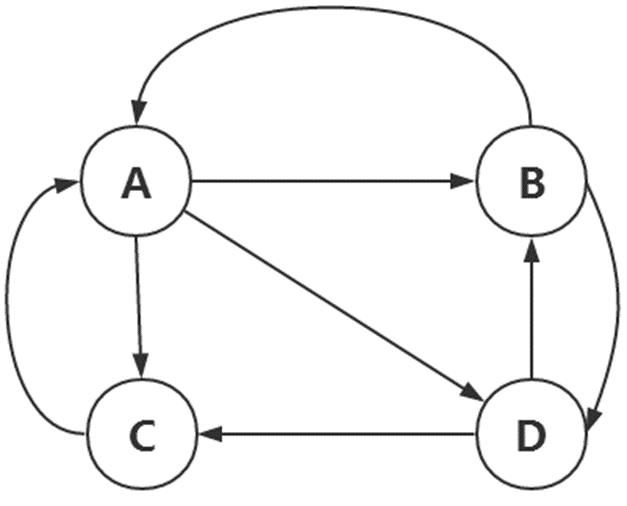
如图,假设现在有四张网页,对于页面A来说,它链接到页面B,C,D,即A有3个出链,则它跳转到每个出链B,C,D的概率均为1/3.。如果A有k个出链,跳转到每个出链的概率为1/k。同理B到A,C,D的概率为1/2,0,1/2。C到A,B,D的概率为1,0,0。D到A,B,C的概率为0,1/2,1/2。
转化为矩阵为:
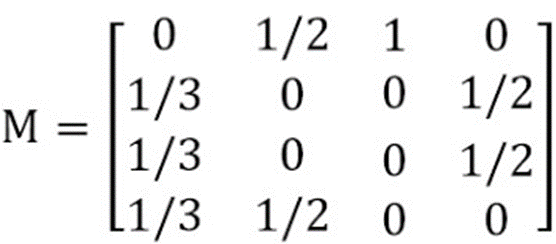
在上图中,第一列为页面A对各个页面转移的概率,第一行为各个页面对页面A转移的概率。初始时,每一个页面的PageRank值都是均等的,为1/N,这里也即是1/4。然后对于页面A来说,根据每一个页面的PageRank值和每个页面对页面A的转移概率,可以算出新一轮页面A的PageRank值。这里,只有页面B转移了自己的1/2给A。页面C转移了自己的全部给A,所以新一轮A的PageRank值为1/4*1/2+1/4*1=9/24。
为了计算方便,我们设置各页面初始的PageRank值为一个列向量V0。然后再基于转移矩阵,我们可以直接求出新一轮各个页面的PageRank值。即 V1 = MV0

现在得到了各页面新的PageRank值V1, 继续用M 去乘以V1 ,就会得到更新的PageRank值。一直迭代这个过程,可以证明出V最终会收敛。此时停止迭代。这时的V就是各个页面的PageRank值。
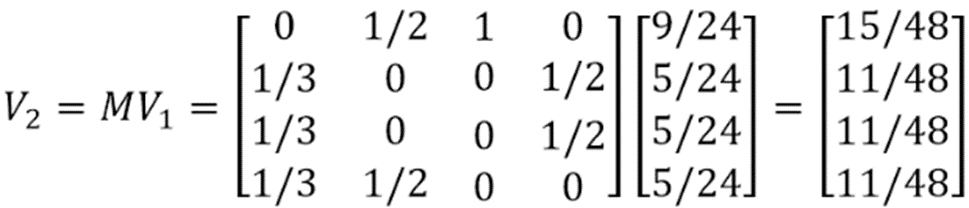

处理Dead Ends(终止点):
上面的PageRank计算方法要求整个Web是强联通的。而实际上真实的Web并不是强联通的,有一类页面,它们不存在任何外链,对其他网页没有PR值的贡献,称之为Dead Ends(终止点)。如下图:
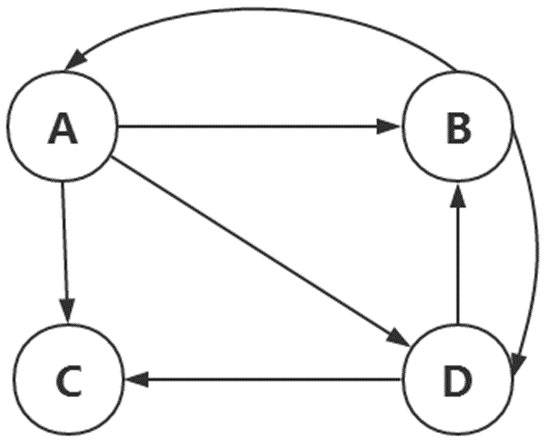
这里页面C即是一个终止点。而上面的算法之所以能够成功收敛,很大因素上基于转移矩阵每一列的和为1(每一个页面都至少有一个出链)。当页面C没有出链时,转移矩阵M如下所示:

基于这个转移矩阵和初始的PageRank列向量,每一次迭代过的PageRank列向量如下:
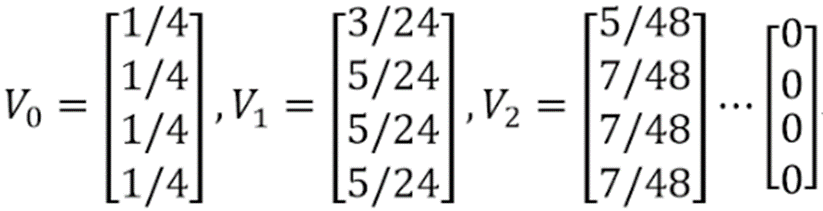
解决该问题的一种方法是:迭代拿掉图中的Dead Ends点以及相关的边,之所以是迭代拿掉,是因为当拿掉最初的Dead Ends之后,又可能产生新的Dead Ends点。直到图中没有Dead Ends点为止。然后对剩余的所有节点,计算它们的PageRank ,然后以拿掉Dead Ends的逆序反推各个Dead Ends的PageRank值。
比如在上图中,首先拿掉页面C,发现没有产生新的Dead Ends。然后对A,B,D 计算他们的PageRank,他们初始PageRank值均为1/3,且A有两个出链,B有两个出链,D有一个出链,那么由上面的方法可以算出各页面最终的PageRank值。假设算出A的PageRank 为x,B的PageRank 为y,D的PageRank 为z,那么C的PageRank值为1/3*x + 1/2*z 。
处理Spider Traps(蜘蛛陷阱):
真实的Web链接关系若是转换成转移矩阵,那必将是一个稀疏的矩阵。而稀疏的矩阵迭代相乘会使得中间产生的PageRank向量变得不平滑(一小部分值很大,大部分值很小或接近于0)。而一种Spider Traps节点会加剧这个不平滑的效果,也即是蜘蛛陷阱。它是指某一些页面虽然有外链,但是它只链向自己。如下图所示:

如果对这个图按照上面的方法进行迭代计算PageRank , 计算后会发现所有页面的PageRank值都会逐步转移到页面C上来,而其他页面都趋近于零。
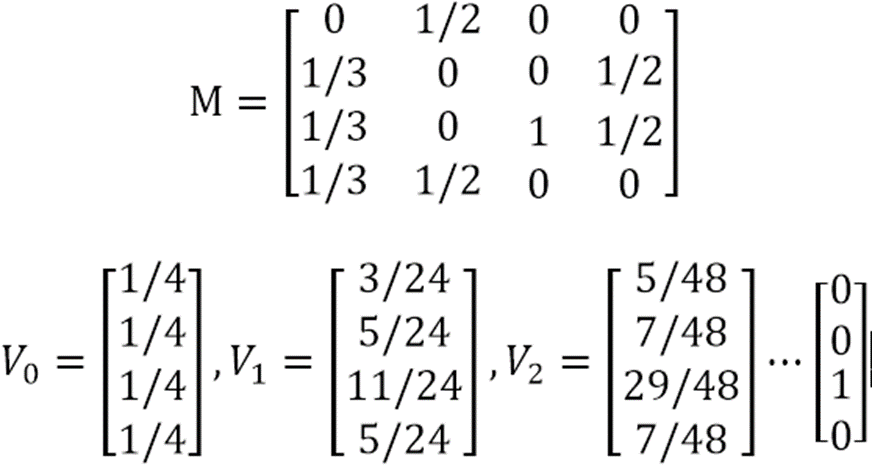
为了解决这个问题,我们需要对PageRank 计算方法进行一个平滑处理–加入teleporting(跳转因子)。也就是说,用户在访问Web页面时,除了按照Web页面的链接关系进行选择以外,他也可能直接在地址栏上输入一个地址进行访问。这样就避免了用户只在一个页面只能进行自身访问,或者进入一个页面无法出来的情况。
加入跳转因子之后,PageRank向量的计算公式修正为:
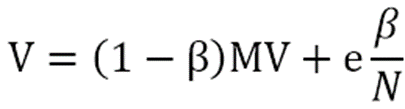
其中,β 通常设置为一个很小的数(0.2或者0.15),e为单位向量,N是所有页面的个数,乘以1/N是因为随机跳转到一个页面的概率是1/N。这样,每次计算PageRank值,既依赖于转移矩阵,同时依赖于小概率的随机跳转。
以上图为例,改进后的PageRank值计算如下:
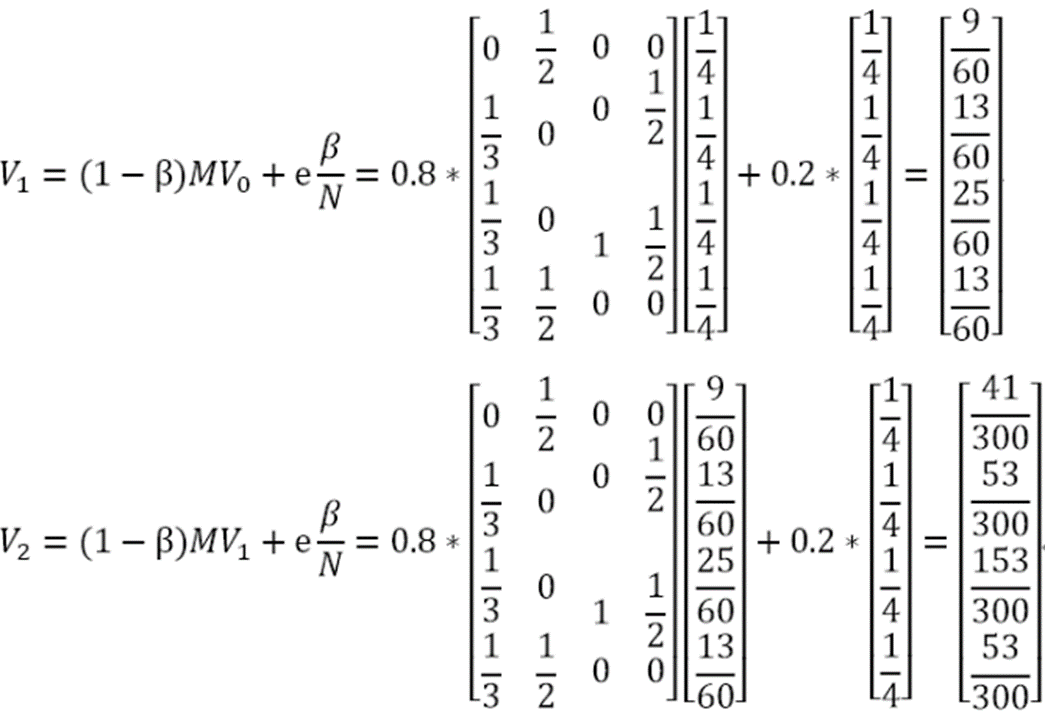
按照这个计算公式迭代下去,会发现spider traps 效应被抑制了,使得各个页面得到一个合理的PageRank值。
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
Hadoop 2.6.0-cdh5.4.5
实验内容
基于MapReduce 的PageRank 设计思路:
假设目前需要排名Dev网页有如下四个:
其中每一行中第一列为网页,第二列为该网页的pagerank值,之后的列均为该网页链接的其他网页。
Baidu存在三个外链接。
Google存在两个外链接。
Sina存在一个外链接。
Hao123存在两个外链接。
由数据可以看出:指向Baidu的链接有一个,指向Google的链接有两个,指向Sina的链接有三个,指向Hao123的链接有两个,所以Sina的PR应该最高,其次是Google和Hao123相等,最后是Baidu。
因为我们要迭代的计算PageRank值,那么每次MapReduce 的输出要和输入的格式是一样的,这样才能使得Mapreduce 的输出用来作为下一轮MapReduce 的输入。
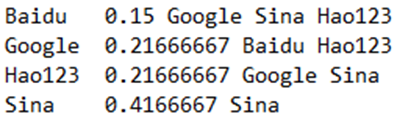
我们每次得到的输出如下:
Map过程的设计:
1.对每一行文本进行解析,获得当前网页、当前网页的PageRank值、当前网页要链接到的其他网页
2.计算出要链接到的其他网页的个数,然后求出当前网页对其他网页的贡献值。
输出设计时,要输出两种:
第一种输出的< key ,value>中的key 表示其他网页,value 表示当前网页对其他网页的贡献值。
第二种输出的< key ,value>中的key 表示当前网页,value 表示所有其他网页。
为了区别这两种输出,第一种输出的value里加入“@”,第二种输出的value里加入“&”
经过Map后的结果为:

Map结果输出之后,经过Shuffle过程排序并合并,结果如下:

由shuffle结果可知,shuffle过程的输出key表示一个网页,输出value表示一个列表,里面有两类:一类是从其他网页获得的贡献值,一类是该网页的所有出链网页
Reduce过程的设计:
1.shuffle的输出也即是reduce的输入。
2.reduce输入的key直接作为输出的key
对reduce输入的value进行解析,它是一个列表:
若列表里的值里包含“@”,就把该值“@”后面的字符串转化成float型加起来
若列表里的值里包含“&”,就把该值“&”后面的字符串提取出来
把所有贡献值的加和,和提取的字符串进行连接,作为reduce的输出value
最终输出如下:

实验步骤
1.首先,我们来准备实验需要用到的数据,切换到/data/mydata目录下,使用vim编辑一个pr_data.txt文件
- cd /data/mydata
- vim pr_data.txt
2.将如下数据写入其中
- Baidu 0.25 Google Sina Hao123
- Google 0.25 Baidu Hao123
- Sina 0.25 Sina
- Hao123 0.25 Google Sina
3.切换到/apps/hadoop/sbin目录下,开启Hadoop相关进程
- cd /apps/hadoop/sbin
- ./start-all.sh
4.输入JPS查看一下相关进程是否已经启动。
- jps

5.在HDFS的根下创建一个/pagerank/input目录,并将pr_data.txt文件上传到HDFS上的/pagerank/input文件夹下
- hadoop fs -mkdir /pagerank
- hadoop fs -mkdir /pagerank/input
- hadoop fs -put /data/mydata/pr_data.txt /pagerank/input
6.查看一下pr_data.txt文件是否上传成功
- hadoop fs -ls /pagerank/input

7.打开Eclipse,创建一个Map/Reduce项
8.项目名为:mr_sf
9.右键单击mr_sf项目,创建一个名为:mr_pagerank的包
10.创建一个名为PageRank的类。
11.下面编写代码,实现功能为:使用MR实现PageRank,计算出Baidu、Google、Sina、Hao123四个网站的PR值排名。
完整代码为:
- package mr_pagerank;
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- public class PageRank {
- /*map过程*/
- public static class mapper extends Mapper<Object,Text,Text,Text>{
- private String id;
- private float pr;
- private int count;
- private float average_pr;
- public void map(Object key,Text value,Context context)
- throws IOException,InterruptedException{
- StringTokenizer str = new StringTokenizer(value.toString());//对value进行解析
- id =str.nextToken();//id为解析的第一个词,代表当前网页
- pr = Float.parseFloat(str.nextToken());//pr为解析的第二个词,转换为float类型,代表PageRank值
- count = str.countTokens();//count为剩余词的个数,代表当前网页的出链网页个数
- average_pr = pr/count;//求出当前网页对出链网页的贡献值
- String linkids ="&";//下面是输出的两类,分别有'@'和'&'区分
- while(str.hasMoreTokens()){
- String linkid = str.nextToken();
- context.write(new Text(linkid),new Text("@"+average_pr));//输出的是<出链网页,获得的贡献值>
- linkids +=" "+ linkid;
- }
- context.write(new Text(id), new Text(linkids));//输出的是<当前网页,所有出链网页>
- }
- }
- /*reduce过程*/
- public static class reduce extends Reducer<Text,Text,Text,Text>{
- public void reduce(Text key,Iterable<Text> values,Context context)
- throws IOException,InterruptedException{
- String link = "";
- float pr = 0;
- /*对values中的每一个value进行分析,通过其第一个字符是'@'还是'&'进行判断
- 通过这个循环,可以求出当前网页获得的贡献值之和,也即是新的PageRank值;同时求出当前
- 网页的所有出链网页 */
- for(Text val:values){
- if(val.toString().substring(0,1).equals("@")){
- pr += Float.parseFloat(val.toString().substring(1));
- }
- else if(val.toString().substring(0,1).equals("&")){
- link += val.toString().substring(1);
- }
- }
- pr = 0.8f*pr + 0.2f*0.25f;//加入跳转因子,进行平滑处理
- String result = pr+link;
- context.write(key, new Text(result));
- }
- }
- public static void main(String[] args) throws Exception{
- Configuration conf = new Configuration();
- conf.set("mapred.job.tracker", "hdfs://127.0.0.1:9000");
- //设置数据输入路径
- String pathIn ="hdfs://127.0.0.1:9000/pagerank/input";
- //设置数据输出路径
- String pathOut="hdfs://127.0.0.1:9000/pagerank/output/pr";
- for(int i=1;i<100;i++){ //加入for循环,最大循环100次
- Job job = new Job(conf,"page rank");
- job.setJarByClass(PageRank.class);
- job.setMapperClass(mapper.class);
- job.setReducerClass(reduce.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- FileInputFormat.addInputPath(job, new Path(pathIn));
- FileOutputFormat.setOutputPath(job, new Path(pathOut));
- pathIn = pathOut;//把输出的地址改成下一次迭代的输入地址
- pathOut = pathOut+'-'+i;//把下一次的输出设置成一个新地址。
- System.out.println("正在执行第"+i+"次");
- job.waitForCompletion(true);//把System.exit()去掉
- //由于PageRank通常迭代30~40次,就可以收敛,这里我们设置循环35次
- if(i == 35){
- System.out.println("总共执行了"+i+"次之后收敛");
- break;
- }
- }
- }
- }
12.右键依次点击Run As=>Run on Hadoop,执行PageRank类
可以在Console界面看到程序正在运行
13.当程序运行完以后可以到HDFS上的/pagerank/output目录下查看运行结果
- hadoop fs -ls /pagerank/output
14.我们查看最后一次迭代的结果
- hadoop fs -cat /pagerank/output/pr-1-2-3-4-5-6-7-8-9-10-11-12-13-14-15-16-17-18-19-20-21-22-23-24-25-26-27-28-29-30-31-32-33-34/*

通过结果我们可以看到,Sina的PR值最高,排名第一。Google和Hao123的PR值并列第二,Baidu的PR值最低。