MapReduce 社交好友推荐算法
实验目的
1.了解笛卡尔积
2.学习MapReduce 社交好友推荐算法
实验原理
如果A和B具有好友关系,B和C具有好友关系,而A和C却不是好友关系,那么我们称A和C这样的关系为:二度好友关系。
在生活中,二度好友推荐的运用非常广泛,比如某些主流社交产品中都会有“可能认识的人”这样的功能,一般来说可能认识的人就是通过二度好友关系搜索得到的,在传统的关系型数据库中,可以通过图的广度优先遍历算法实现,而且深度限定为2,然而在海量的数据中,这样的遍历成本太大,所以有必要利用MapReduce编程模型来并行化。
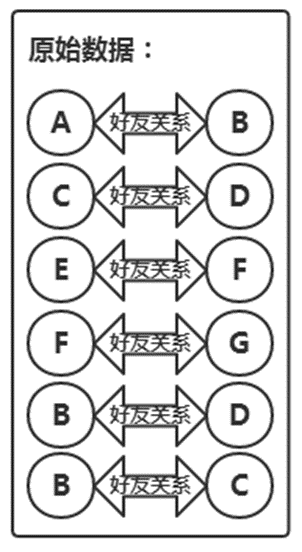
初始数据如下:
A B
C D
E F
F G
B D
B C
map阶段得到的结果为:
Key:A Value:B
Key:B Value:A C D
Key:C Value:B D
Key:E Value:F
Key:F Value:E G
Key:G Value:F
Reduce阶段再将Value进行笛卡尔积运算就可以得到二度好友关系了
(笛卡尔积公式:A×B={(x,y)|x∈A∧y∈B}
例如,A={a,b}, B={0,1,2},则
A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)})
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
Hadoop 2.6.0-cdh5.4.5
实验内容
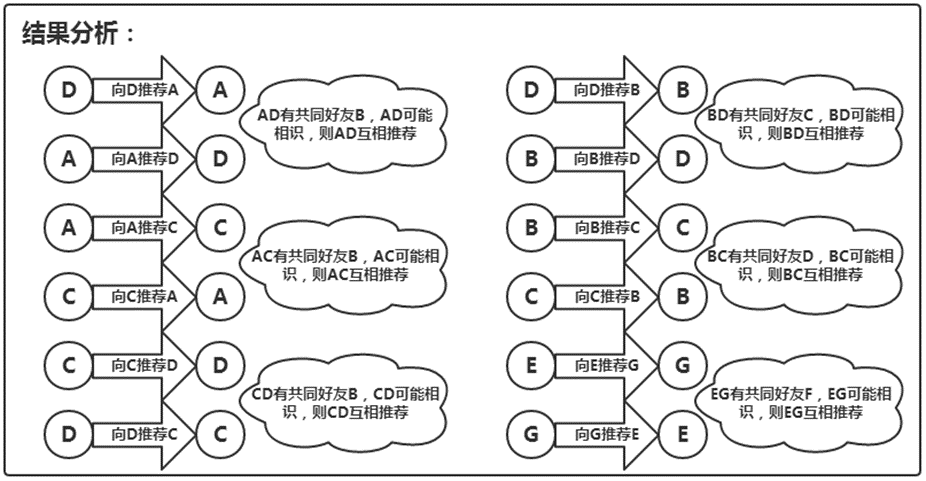
通过初始数据,假设有A、B、C、D、E、F、G七位同学,其中A与B是好友关系,C与D是好友关系,E与F是好友关系,F与G是好友关系,B与D是好友关系,B与C是好友关系,通过分析A与B是好友,且B与C也是好友,我们就认为A与C互为可能认识的人,向A与C互相推荐对方。
实验步骤
1.首先,来准备实验需要用到的数据,切换到/data/mydata目录下,使用vim编辑一个friend_data.txt文件。
- cd /data/mydata
- vim friend_data.txt
2.将如下初始数据写入其中(注意数据之间以空格分割)
- A B
- C D
- E F
- F G
- B D
- B C
3.切换到/apps/hadoop/sbin目录下,开启Hadoop相关进程
- cd /apps/hadoop/sbin
- ./start-all.sh
4.输入JPS查看一下相关进程是否已经启动。
- jps
5.在HDFS的根下创建一个friend目录,并将friend_data.txt文件上传到HDFS上的friend文件夹下。
- hadoop fs -mkdir /friend
- hadoop fs -put /data/mydata/friend_data.txt /friend
6.打开Eclipse,创建一个Map/Reduce项目。
7.设置项目名为mr_sf并点击Finish。
8.创建一个包,名为mr_friend。
9.创建一个类,名为Find_Friend。
10.下面开始编写Find_Friend类的代码。
完整代码为:
- package mr_friend;
- import java.io.IOException;
- import java.net.URI;
- import java.net.URISyntaxException;
- import java.util.HashSet;
- import java.util.Iterator;
- import java.util.Set;
- import org.apache.hadoop.conf.Configuration;
10. import org.apache.hadoop.fs.FileSystem;
11. import org.apache.hadoop.fs.Path;
12. import org.apache.hadoop.io.LongWritable;
13. import org.apache.hadoop.io.Text;
14. import org.apache.hadoop.mapreduce.Job;
15. import org.apache.hadoop.mapreduce.Mapper;
16. import org.apache.hadoop.mapreduce.Reducer;
17. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
18. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- 19.
20. public class Find_Friend {
21. /*
22. map结果:
23. A B
24. B A
25. C D
26. D C
27. E F
28. F E
29. F G
30. G F
31. B D
32. D B
33. B C
34. C B
35. */
- 36.
- 37. public static class FindFriendsMapper extends Mapper<LongWritable, Text, Text, Text> {
- 38. @Override
- 39. protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
- 40. throws IOException, InterruptedException {
- 41. String line = value.toString();
- 42. String array[] = line.split("\\s+");
- 43. context.write(new Text(array[0]), new Text(array[1]));
- 44. context.write(new Text(array[1]), new Text(array[0]));
- 45. }
- 46. }
- 47.
48. /*
49. map之后,Shuffling将相同key的整理在一起,结果如下:
50. shuffling结果(将结果输出到reduce):
51. A B
- 52.
53. B A
54. B D
55. B C
- 56.
57. C D
58. C B
- 59.
60. E F
- 61.
62. F E
63. F G
- 64.
65. G F
66. */
67. //reduce将上面的数据进行笛卡尔积计算
- 68. public static class FindFriendsReduce extends Reducer<Text, Text, Text, Text> {
- 69. @Override
- 70. protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
- 71. throws IOException, InterruptedException {
- 72. //将重复数据去重
- 73. Set<String> set = new HashSet<String>();
- 74. for (Text v : values) {
- 75. set.add(v.toString());
- 76. }
- 77.
- 78. if (set.size() > 1) {
- 79. for (Iterator<String> i = set.iterator(); i.hasNext();) {
- 80. String qqName = i.next();
- 81. for (Iterator<String> j = set.iterator(); j.hasNext();) {
- 82. String otherQqName = j.next();
- 83. if (!qqName.equals(otherQqName)) {
- 84. context.write(new Text(qqName), new Text(otherQqName));
- 85. }
- 86. }
- 87. }
- 88. }
- 89. }
- 90. }
- 91.
- 92. public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
- 93. final String INPUT_PATH = "hdfs://127.0.0.1:9000/friend/friend_data.txt";
- 94. final String OUTPUT_PATH = "hdfs://127.0.0.1:9000/friend/output";
- 95.
- 96. Configuration conf = new Configuration();
- 97. //Configuration:map/reduce的配置类,向hadoop框架描述map-reduce执行的工作
- 98.
- 99. final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
- if(fileSystem.exists(new Path(OUTPUT_PATH))) {
- fileSystem.delete(new Path(OUTPUT_PATH), true);
- }
- Job job = Job.getInstance(conf, "Find_Friend");//设置一个用户定义的job名称
- job.setJarByClass(Find_Friend.class);
- job.setMapperClass(FindFriendsMapper.class); //为job设置Mapper类
- job.setReducerClass(FindFriendsReduce.class); //为job设置Reducer类
- job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
- job.setOutputValueClass(Text.class); //为job输出设置value类
- FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
- FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
- System.exit(job.waitForCompletion(true) ?0 : 1); //运行job
- }
- }
11.下面在Find_Friend类下,单击右键,选择Run As=>Run on Hadoop,运行程序,查看执行结果。
12.程序执行完以后,查看HDFS上的/friend/output目录中的计算结果。
- hadoop fs -ls -R /friend
- hadoop fs -cat /friend/output/part-r-00000
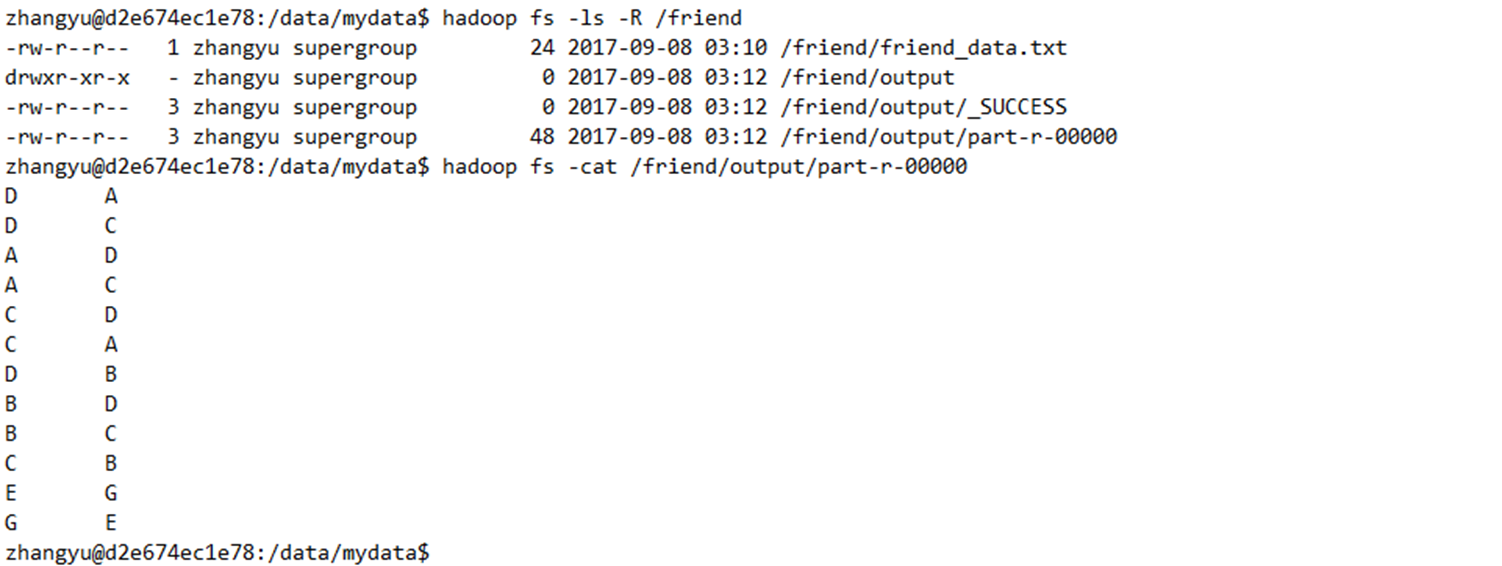
通过分析结果,就得出了各位同学的可能认识的人的列表了。
至此,实验就已经结束了。