索引的分类
如下:
| 物理分类 | 逻辑分类 |
| 分区或非分区索引 | 单列或组合索引 |
| B树索引(标准索引) | 唯一或非唯一索引 |
| 正常或反向键索引 | 基于函数索引 |
| 位图索引 |
B树索引
b树索引通常也称为标准索引,索引的顶部为根,其中包含指向索引中下一级的项,下一级为分支块,分支块又指向索引中下一级的块.最低级为叶节点
,其中包含指向表行的索引项.叶块为双向链接,有助于按关键字值的升序和降序扫描索引
要深入了解B树索引可以去这里:https://blog.csdn.net/kennyrose/article/details/7532032
创建普通索引的语法如下
CREATE [UNIQUE] INDEX inde_name ON table_name(column_list)
[tablespace. _name];
在语法中
- UNIQUE:用于指定唯一索引, 默认情况下为非唯一索引。
- index_ name : 指所创建索引的名称。
- table_ name:表示为之创建索引的表名。
- column list:在其上创建索引的列名的列表,可以基于多列创建索引
- tablespace. _name;为索引指定表空间。2.唯一索引和非唯一索引
- 唯一索引:定义索引的列中任何两行都没有重复值。唯一索引中的索引关键字只能指向表中的一行。在创建主键约束和创建唯一约束时都会创建一个与之对应的唯一索引。
- 非唯一索引: 单个关键字可以有多个与其关联的行。
在薪水级别(salgrade) 表中,为级别编号(grade) 列创建唯一索引, 代码如下。
CREATE INDEX idx_emp_department ON emp(deptno);
反向键索引
与常规B树索引相反,反向键索引在保持列顺序的同时反转索引列的字节。反向键索引通过反
分散在多专索引键的数据值来实现。其优点是对于连续增长的索引列,反转索引列可以将索引数据力个索引块间,减少1/0瓶颈的发生。
反向键索引通常建立在一些值连续增长的列上, 如系统生成的员工编号, 但不能执行范围投。
反向索引代码如下
CREATE UNIQUE INDEX idx_empno ON emp(empno) REVERSE;
位图索引
位图索引的优点在于,它最适于低基数列(即该列的值是有限的,理论,上不会是无穷大)。例如,员工表中的工种(job) 列,即便是几百万
条员工记录,工种也是可计算的。工种列可以作为位图索31.类似的还有图书表中的图书类别列等。
| 值/行 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 产品经理 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 项目经理 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 程序员 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
原理如上 :有7条数据,和3种类型,满足条件的就是1否则为0,如要查询是否是项目经理时只需找出为1的即可
创建位图SQL语句如下
CREATE BITMAP INDEX idx_emp_job ON emp(job);
位图索引具有下列优点。
- 对于大批即时查询,可以减少响应时间。
- 相比其他索引技术,占用空间明显减少。
- 即使在配置很低的终端硬件上.也能获得显著的性能。
位图索引不应当用在频繁发生INSERT UPDATE DLE操作的表上,这些DML操作在性能方面的代价很高。 位图索引最适合于数据仓库和决策支持系统。
其他索引
- 组合索引:在表内多列上创建。索引中的列不必与表中的列顺序一致, 也不必相互邻接,类似于SQL Server 中的复合索引,如员工表中部门和职务列上的索引。组合索引最多包含32列。
- 基于函数的索引:若使用的函数或表达式涉及正在建立索引的表中的一-列或多列,则创建基于函数的索引。可以将基于函数的索引创建为8树或位图索引。
--创建组合索引 CREATE INDEX idx_emp_name ON emp(last_name,first_name);
索引创建规则
创建索引时需遵循的原则如下:
- 频繁搜索的列可以作为索引。
- 经常排序、分组的列可作为索引。
- 经常用作连接的列(主键/外键)可作为索引。
- 将索引放在一个单独的表空间中.不要放在有回退段、临时段和表的表空间中
- 对大型索引而言,考虑使用NOLOGGING子句创建大型索引。
- 根据业务数据发生的频率,定期重新生成或重新组织索引,并进行碎片整理。
- 仅包含几个不同值的列不可以创建为B树索引,可根据需要创建位图索引。
- 不要在仅包含几行的表中创建索引。
删除索引
--删除索引 drop index idx_empno;
何时应删除索引
- 应用程序不再需要索引。
- 执行批量加载前。大量加载数据前删除索引.加载后再重建索引有以下好处,①提高加战性能:②更有效地使用索引空间。
- 索引已损坏。
重建索引
--重建索引 把反向改为B树索引 alter index idx_empno rebuild noreverse
何时应重建索引
- 用户表被移动到新的表空间后,表上的索引不是自动转移,此时需将索引移到指定表空间。
- ALTER INDEX index_ name REBUILD TABLESPACE tablespace name;
- 索引中包含很多已删除的项。对表进行频繁删除,造成索引空间浪费,可以重建索引。
- 需将现有的正常索引转换成反向键索引。
所有的索引无非就是一个目的提高查询效率,那么oracle中如何来看呢

运行后选中查询语句按下F5
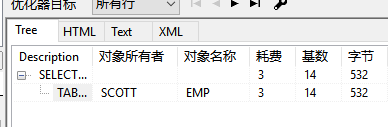
耗费消耗的越少效率越高
分区表
oracle可以把表中的数据分为几个部分存储在不同的位置,被分区的表叫做分区表
对于包含大量数据的表来说分区很有用,有以下优点
- 改善查询性能,分区后SQL查询时可以只访问表中特定的区域
- 更容易管理,按分区加载和删除比在表中更容易
- 便于备份和恢复,可以独立备份和恢复每个分区
- 提高数据安全性,将不同的分区分布在不同的磁盘,减小分区数据同时损坏的风险
oracle提供分区的方法有以下几种
- 范围分区
- 列表分区
- 散列分区
- 复合分区
- 间隔分区
- 虚拟分区
简单了解下范围和间隔分区
范围分区
该分区以列的值范围作为分区划分的条件降级了存放到列值所在的范围分区中.
/* =========================================================== || 创建范围分区表 =========================================================== */ CREATE TABLE sales_range1 (sales_id NUMBER NOT NULL, product_id VARCHAR2(5), sales_date DATE, sales_cost NUMBER(10), areacode VARCHAR2(5) ) partition by range(sales_date) (partition part1 values less than (to_date('2011/01/01','yyyy/mm/dd')) TABLESPACE tp_orders, partition part2 values less than (to_date('2012/01/01','yyyy/mm/dd')), partition part3 values less than (to_date('2013/01/01','yyyy/mm/dd')), partition part4 values less than (to_date('2014/01/01','yyyy/mm/dd')) ); --查询分区情况 SELECT table_name,partition_name FROM user_tab_partitions WHERE table_name=UPPER('sales_range1'); --插入数据 insert into sales_range1 values (1000,'p1',to_date('2011-01-01','yyyy-mm-dd'),1000,'A1'); --查询数据 select * from sales_range1 PARTITION (part2);
间隔分区
该分区是范围分区的一种增强功能,可以实现范围分区的自动化,优点在于不需要创建表时就将所要分区划分清楚.间隔分区随着数据增长会划分更多
分区,并自动创建新的分区
/* =========================================================== | 间隔分区表 ============================================================ */ CREATE TABLE sales_interval1 (sales_id NUMBER NOT NULL, product_id VARCHAR2(5), sales_date DATE, sales_cost NUMBER(10), areacode VARCHAR2(5) ) PARTITION BY RANGE(sales_date) INTERVAL(NUMTOYMINTERVAL(1,'YEAR')) (PARTITION part1 VALUES LESS THAN (to_date('2011/01/01','yyyy/mm/dd'))) --查询分区情况 SELECT table_name,partition_name,tablespace_name FROM user_tab_partitions WHERE table_name=UPPER('sales_interval1'); INSERT INTO sales_interval1 VALUES (1000,'p1',SYSDATE,2000,'A2'); SELECT * FROM sales_interval1 PARTITION (SYS_P142); --现有表创建新表 CREATE TABLE sales_interval2 PARTITION BY RANGE(sales_date) INTERVAL(NUMTOYMINTERVAL(1,'YEAR')) (PARTITION part1 VALUES LESS THAN (to_date('2011/01/01','yyyy/mm/dd'))) AS SELECT * FROM sales;