最近组里要对用户数据做一个数据分析系统,然后组里让先研究下大数据技术了,所以呢也是带着一脸懵的就开始google大数据的东西,结果出来了一堆,感觉大数据的知识体系有点庞大,看了一堆就决定先从flink入手了,因为公司有的组主要在开发这个。
本文是最简单的入门demo,单机搭建,目的是自己先跑起来,知道这东西大概有个什么用处。
步骤一 安装
安装flink之前需要先安装jvm,这个可以自行百度。
下载flink,地址为https://archive.apache.org/dist/flink/ ,这个地址下载速度有点慢,也可以选择腾讯镜像地址 https://mirrors.cloud.tencent.com/apache/flink/ 。我是下载的是,linux下应该也是可以直接使用wget下载的
如果没有linux环境也可以下载1.8版本及以前的,这样的话可以直接在windows版本下启动

在安装包的同级目录下执行解压命令
[root@localhost bin]# tar -xvf flink-1.10.3-bin-scala_2.11.tgz
然后进入bin目录执行安装启动脚本,不出意外可以启动成功(记得默认8081端口不能占用)
[root@localhost package]# cd flink-1.10.3/bin/ [root@localhost bin]# ./start-cluster.sh
如果是windows环境启动则1.8及以前的版本解压后在bin目录下启动start-cluster.bat启动
然后记得关闭linux防火墙,浏览器访问8081(默认)端口,出现以下界面就算安装成功了
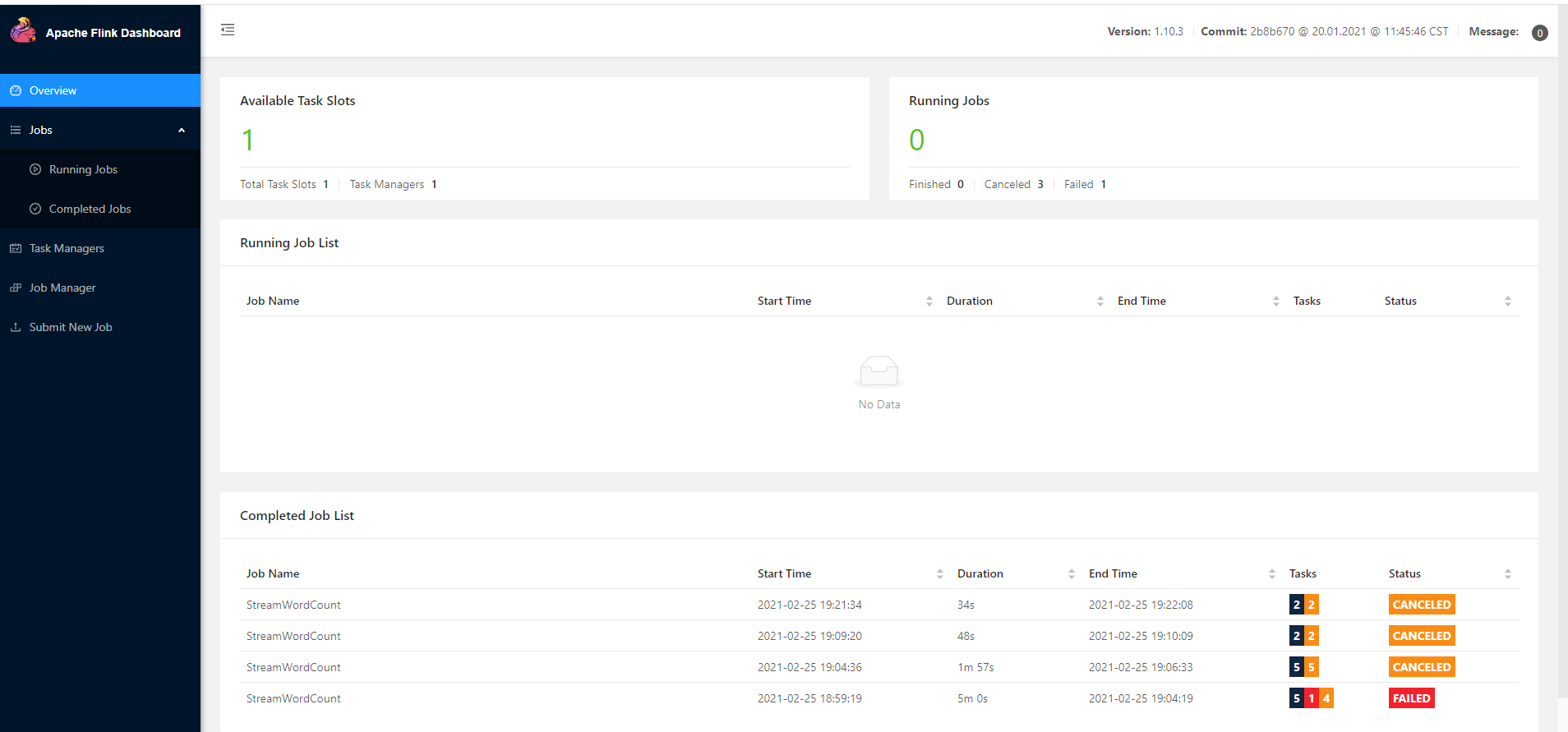
步骤二 编写flink job
此处先大概了解下,一个job的目的是为了接收数据→处理数据→输出数据,这个入门级的demo参考官方的例子了。大概就是的获取tcp服务端的信息(服务端会发送单词),统计单词出现的数量,最后将数据以hash的形式写入redis。
本例子是java编写的maven项目
首先是pom.xml (注意<mainClass>com.flink.starter.FlinkStarter</mainClass> 这项中的类要换成自己的启动类)
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.bigdata</groupId> <artifactId>flink-starter</artifactId> <version>1.0-SNAPSHOT</version> <properties> <flink.version>1.8.1</flink.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-wikiedits_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.8.0</version> </dependency> </dependencies> <repositories> <repository> <id>aliyun</id> <name>aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </repository> </repositories> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.flink.starter.FlinkStarter</mainClass> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>reference.conf</resource> </transformer> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <configuration> <skip>true</skip> </configuration> </plugin> </plugins> </build> </project>
第一个是创建一个redis数据结构的处理器,也就是定义key和value
public class SinkRedisMapper implements RedisMapper<Tuple2<String,Integer>> { @Override public RedisCommandDescription getCommandDescription() { //hset return new RedisCommandDescription(RedisCommand.HSET,"flink"); } @Override public String getKeyFromData(Tuple2<String, Integer> stringIntegerTuple2) { return stringIntegerTuple2.f0; } @Override public String getValueFromData(Tuple2<String, Integer> stringIntegerTuple2) { return stringIntegerTuple2.f1.toString(); } }
然后创建一个信息处理器,标识以空格分隔字符串
package com.flink.handler; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; /** * @author zm1204760 * @version Id: LineSplitter, v 0.1 2021/2/25 18:01 zm1204760 Exp $ */ public class LineSplitter implements FlatMapFunction<String, Tuple2<String,Integer>> { public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] tokens = s.toLowerCase().split("\W+"); for(String token : tokens){ if(token.length() > 0){ collector.collect(new Tuple2<String,Integer>(token,1)); } } } }
最后创建job运行类 注意192.168.75.128 6379是redis的连接信息,这儿根据实际情况连接 ,没有redis也可以将sumed.addSink注释掉,放出sumed.print(),这样数据会打印到控制台
public class FlinkStarter { public static void main(String[] args) throws Exception { ParameterTool parameterTool = ParameterTool.fromArgs(args); String address = parameterTool.get("d"); int port = parameterTool.getInt("p"); //1.创建一个 flink steam 程序的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.使用StreamExecutionEnvironment创建DataStream //Source(可以有多个Source) //Socket 监听本地端口8888(亦可监听linux环境下的某一台机器) DataStreamSource<String> lines = env.socketTextStream(address, port); //Transformation(s)对数据进行处理操作 SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { //切分 String[] words = line.split("\W+"); //循环, for (String word : words) { //将每个单词与 1 组合,形成一个元组 Tuple2<String, Integer> tp = Tuple2.of(word, 1); //将组成的Tuple放入到 Collector 集合,并输出 out.collect(tp); } } }); //进行分组聚合(keyBy:将key相同的分到一个组中) SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception { return stringIntegerTuple2.f0; } }).sum(1); //Transformation 结束 //3.调用Sink (Sink必须调用) //sumed.print(); //sumed.print(); FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("192.168.75.128").setPort(6379).build(); sumed.addSink(new RedisSink<>(conf,new SinkRedisMapper())); //启动(这个异常不建议try...catch... 捕获,因为它会抛给上层flink,flink根据异常来做相应的重启策略等处理) env.execute("StreamWordCount"); } }
本地就可以运行调试了。记住这儿监听的输入源需要提前开启,否则会启动失败,本案例将地址和端口以参数的形式的传入,所以启动命令如下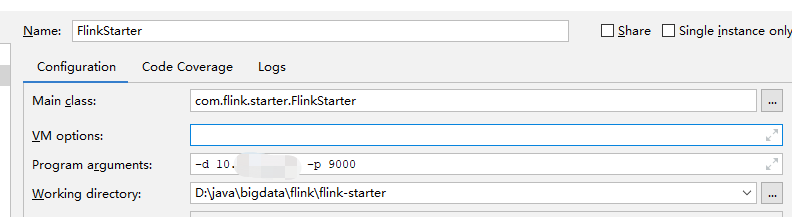
记住运行前需要提前开启数据源,这儿以netassist举例,本地开启server模式后运行job,可以看到已经连接的信息
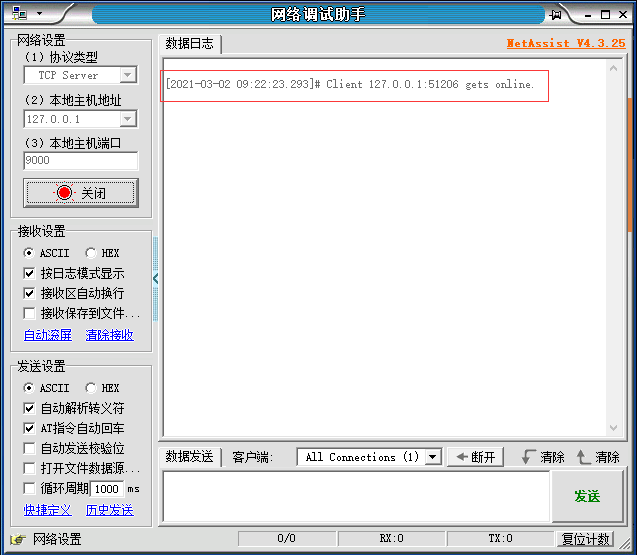
然后我们发一些单词,就可以在控制台看到打印信息


如果设置了redis的输出源,那么这些信息也会输出到redis里面
步骤三 发布job
任务调试成功后,就可以打包发布了
第一步 打包 本案例使用maven
mvn clean package -Dmaven.test.skip=true
打包好后最好本地测试下,确认包没问题再进行下一步
第二步上传
此时浏览器打开步骤一中启动的flink界面,然后进入submit new job菜单,然后add new job 找到刚打包好的jar包上传,不同版本界面可能有些细微变化,但是功能应该是差不多的。记得设置启动类和启动参数
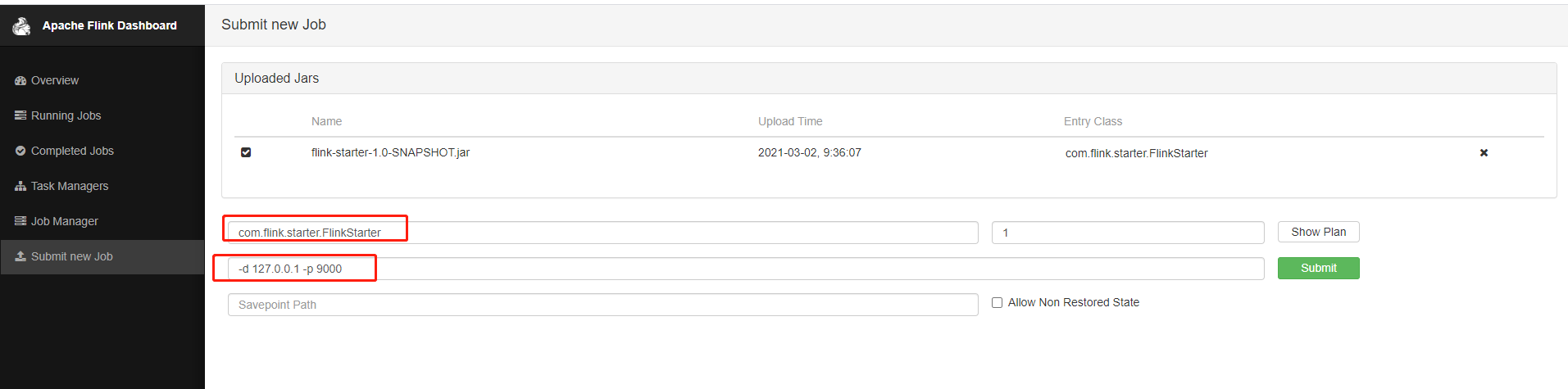
最后点击submit则代表提交任务,如果提交成功则可以在Running jobs里面找到刚刚的任务
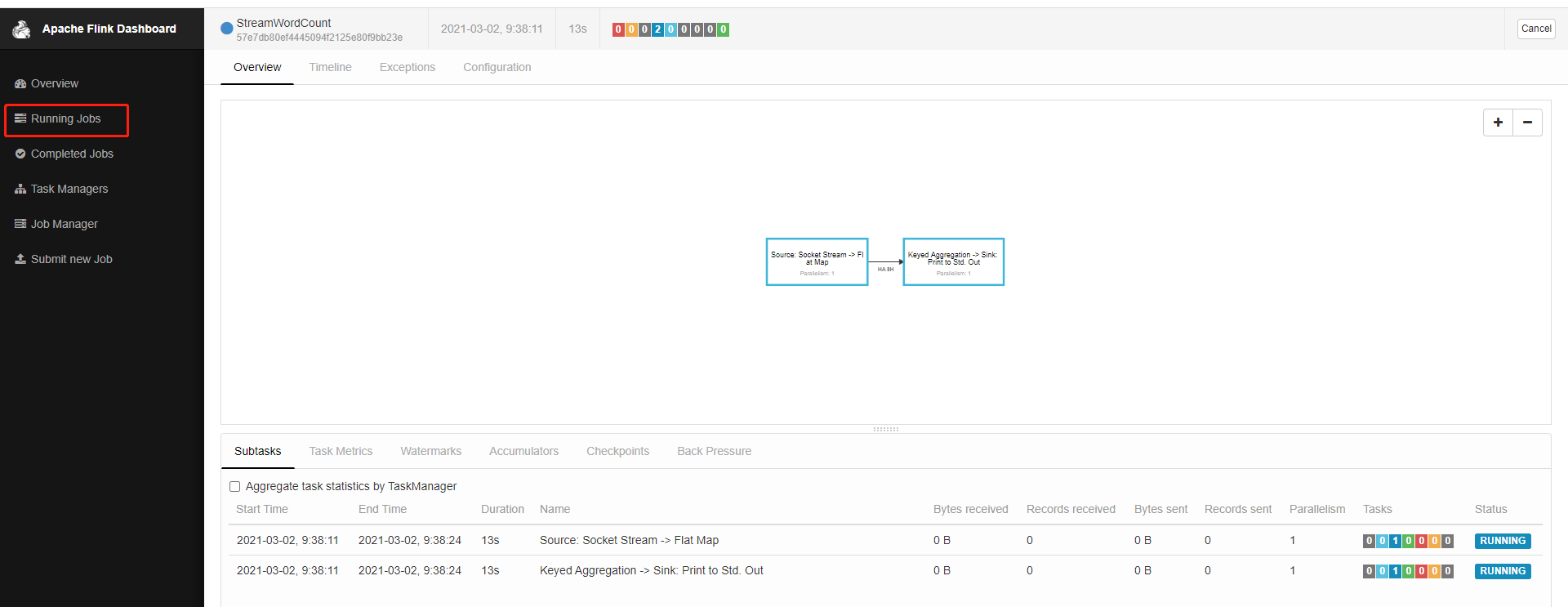
最后我们用之前的netassist助手接着发送一些数据,在这儿就可以看到接收和输出的记录。到此最简单的一个flink demo就完成了
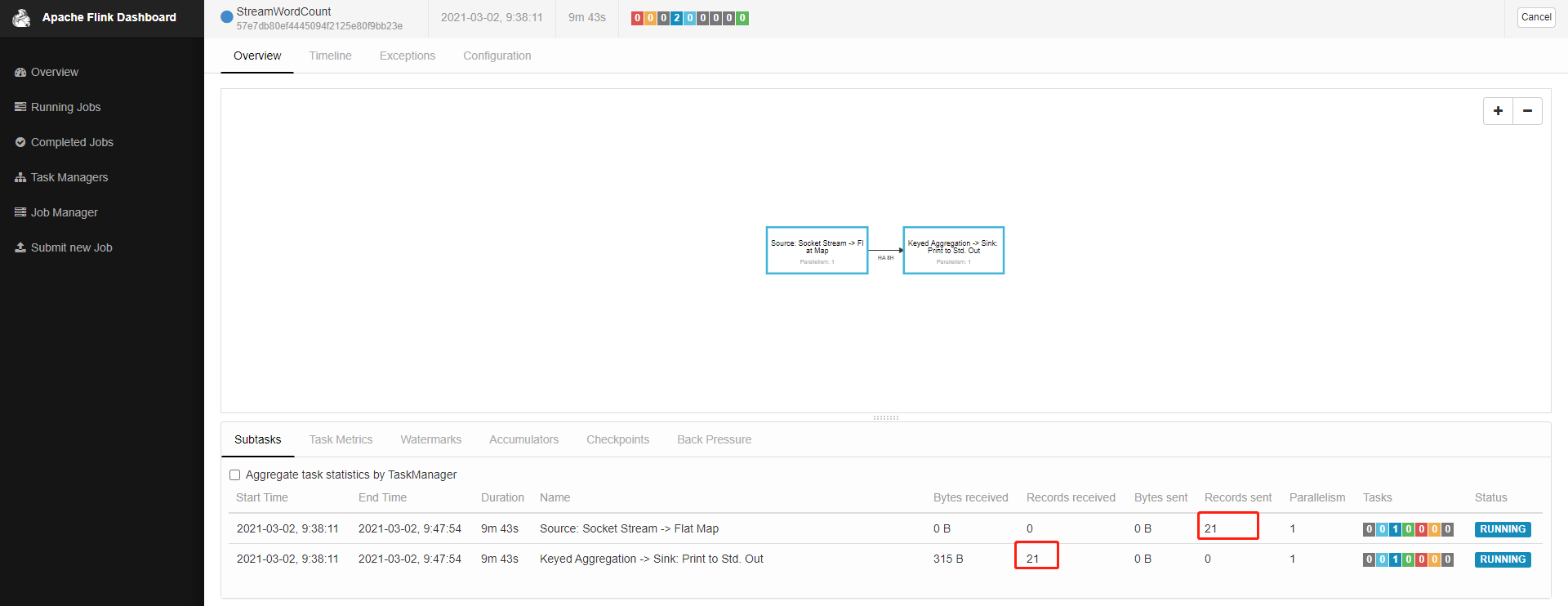
控制台也能看到打印信息
