作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
1.将爬虫大作业产生的csv文件上传到LINUX
首先把收集到的数据所生成的csv文件gzcc.csv上传到装有MySQL、Hive以及Hadooplinux系
2.对CSV文件进行预处理生成无标题文本文件
利用sed命令删除标题

3.把hdfs中的文本文件最终导入到数据仓库Hive中

4.在Hive中查看并分析数据
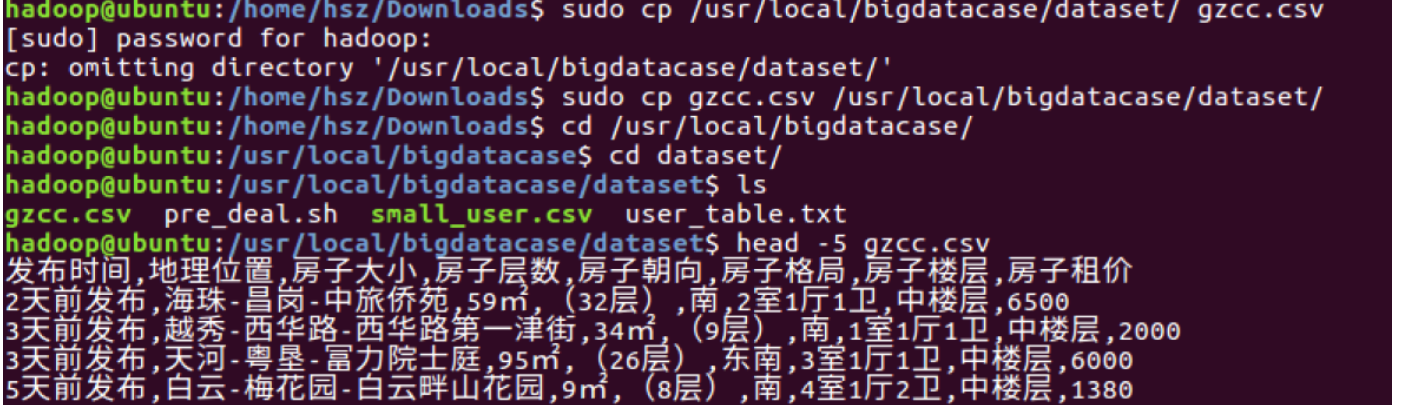
- 查询发布时间,并排序,sql命令如下:

根据这张图可以知道平均每天发布的租房量大概为70左右,而且一个月前发布的房量非常的多可能存在非常多的劣质的房源。
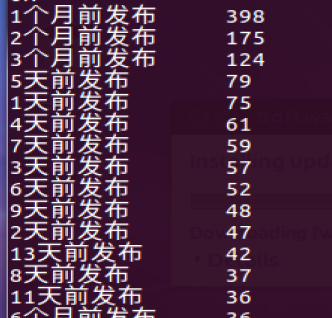
- 查询发布价格,并排序,sql命令如下

看的出价格处在2500的是最高的,其中2000的价格排名第二,而且1500、3000以及35000跟随其后,证明广州市的房租一般都在1500-3500左右
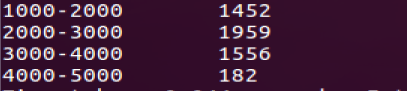
- 查询2000-3000房租的个数,sql命令如下

有513个

- 创建新表进行特殊的存储,例如各个段位的房租费


- 查询个楼层的个数

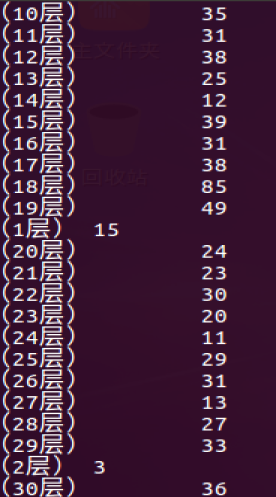
- 查询每个楼层的租费其中1层最便宜

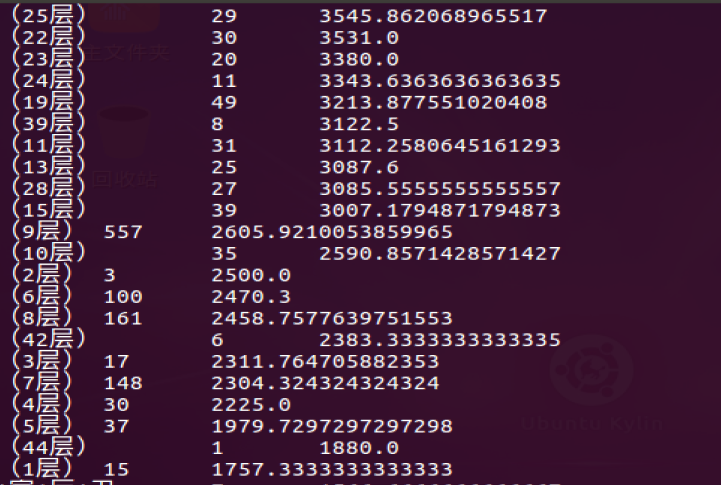
- 查询朝向与平均房租的关系


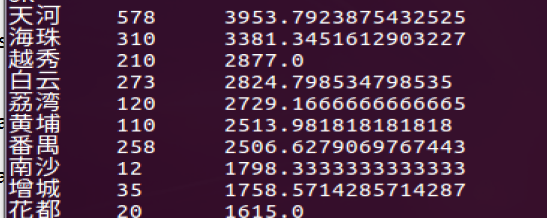
- 查询在哪个区的租房最多,可以知道天河的租房量最大


- 查询每个区的平均的房租为多少其中天河最多,而且房价也是最贵的

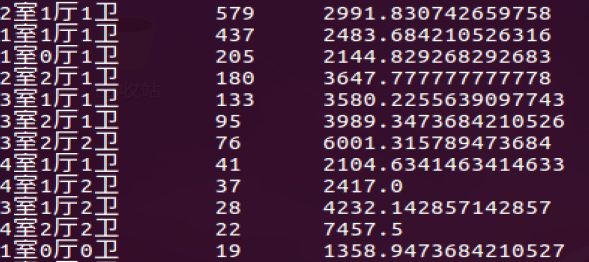
- 查询格局对房租的影响,其中两房一厅一卫是最多的

由此我们可以看得出在广州其实有很多的房源,而其中的房租也非常的贵,几乎集中在1500-3500这个范围,其中以天河区的租房数量为首其房租的金额也比较大。