python-并发编程
1,背景知识
顾名思义,进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。
进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。
所以想要真正了解进程,必须事先了解操作系统。
PS:即使可以利用的cpu只有一个(早期的计算机确实如此),也能保证支持(伪)并发的能力。将一个单独的cpu变成多个虚拟的cpu(多道技术:时间多路复用和空间多路复用+硬件上支持隔离),没有进程的抽象,现代计算机将不复存在
2, 多道技术:
1.产生背景:针对单核,实现并发
ps: 现在的主机一般是多核,那么每个核都会利用多道技术 有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个 cpu中的任意一个,具体由操作系统调度算法决定。
2.空间上的复用:如内存中同时有多道程序
3.时间上的复用:复用一个cpu的时间片 强调:遇到 io切换,占用cpu时间过长也切换,核心在于切换之前将进程的状态保存下来,这样 才能保证下次切换回来时,能基于上次切走的位置继续运行
2,多进程
1,何为进程
进程:正在进行的一个过程或者说一个任务。而负责执行任务则是cpu。
2,进程与程序的区别
程序仅仅只是一堆代码而已,而进程指的是程序的运行过程。


想象一位有一手好厨艺的计算机科学家老原正在为他的女儿宇飞烘制生日蛋糕。
他有做生日蛋糕的食谱,
厨房里有所需的原料:面粉、鸡蛋、韭菜,蒜泥等。
在这个比喻中:
做蛋糕的食谱就是程序(即用适当形式描述的算法)
计算机科学家就是处理器(cpu)
而做蛋糕的各种原料就是输入数据。
进程就是厨师阅读食谱、取来各种原料以及烘制蛋糕等一系列动作的总和。
现在假设计算机科学家老原的儿子伟峰哭着跑了进来,说:Hey, Dad, my head got stung by a bee.
科学家qiuma想了想,处理儿子伟峰蛰伤的任务比给女儿宇飞做蛋糕的任务更重要,于是
计算机科学家就记录下他照着食谱做到哪儿了(保存进程的当前状态),然后拿出一本急救手册,按照其中的指示处理蛰伤。这里,我们看到处理机从一个进程(做蛋糕)切换到另一个高优先级的进程(实施医疗救治),每个进程拥有各自的程序(食谱和急救手册)。当蜜蜂蛰伤处理完之后,这位计算机科学家又回来做蛋糕,从他离开时的那一步继续做下去
需要强调的是:同一个程序执行两次,那也是两个进程,比如打开暴风影音,虽然都是同一个软件,但是一个可以播放苍井空,一个可以播放饭岛爱。
3,并发与并行
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
1, 并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发
2,并行:同时运行,只有具备多个cpu才能实现并行
单核下,可以利用多道技术,多个核,每个核也都可以利用多道技术(多道技术是针对单核而言的)
有四个核,六个任务,这样同一时间有四个任务被执行,假设分别被分配给了cpu1,cpu2,cpu3,cpu4,
一旦任务1遇到I/O就被迫中断执行,此时任务5就拿到cpu1的时间片去执行,这就是单核下的多道技术
而一旦任务1的I/O结束了,操作系统会重新调用它(需知进程的调度、分配给哪个cpu运行,由操作系统说了算)
可能被分 配给四个cpu中的任意一个去执行
4,进程的创建(了解)
但凡是硬件,都需要有操作系统去管理,只要有操作系统,就有进程的概念,就需要有创建进程的方式,一些操作系统只为一个应用程序设计,比如微波炉中的控制器,一旦启动微波炉,所有的进程都已经存在。
而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为4种形式创建新的进程
-
系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印)
-
一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork,subprocess.Popen等)
-
用户的交互式请求,而创建一个新进程(如用户双击暴风影音)
-
一个批处理作业的初始化(只在大型机的批处理系统中应用)
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的:
-
在UNIX中该系统调用是:fork,fork会创建一个与父进程一模一样的副本,二者有相同的存储映像、同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程)
-
在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
关于创建的子进程,UNIX和windows
1.相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程的在其地址空间中的修改都不会影响到另外一个进程。
2.不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本,提示:子进程和父进程是可以有只读的共享内存区的。但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
5,进程的终止(了解)
1,正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
2,出错退出(自愿,python a.py中a.py不存在)
3,严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
4,被其他进程杀死(非自愿,如kill -9)
6,进程的层次结构
无论UNIX还是windows,进程只有一个父进程,不同的是:
-
在UNIX中所有的进程,都是以init进程为根,组成树形结构。父子进程共同组成一个进程组,这样,当从键盘发出一个信号时,该信号被送给当前与键盘相关的进程组中的所有成员。
-
在windows中,没有进程层次的概念,所有的进程都是地位相同的,唯一类似于进程层次的暗示,是在创建进程时,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程,但是父进程有权把该句柄传给其他子进程,这样就没有层次了。
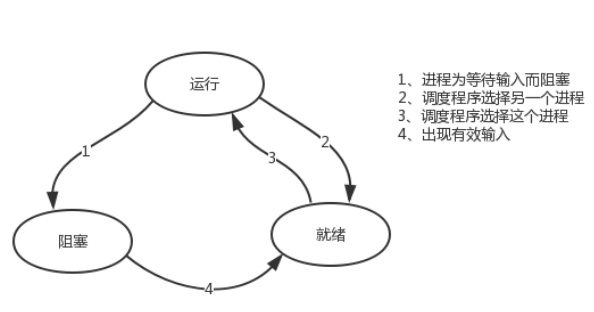
7,进程的状态
tail -f access.log |grep '404'
执行程序tail,开启一个子进程,执行程序grep,开启另外一个子进程,两个进程之间基于管道'|'通讯,将tail的结果作为grep的输入。
进程grep在等待输入(即I/O)时的状态称为阻塞,此时grep命令都无法运行
其实在两种情况下会导致一个进程在逻辑上不能运行,
-
进程挂起是自身原因,遇到I/O阻塞,便要让出CPU让其他进程去执行,这样保证CPU一直在工作
-
与进程无关,是操作系统层面,可能会因为一个进程占用时间过多,或者优先级等原因,而调用其他的进程去使用CPU。
因而一个进程由三种状态
8,进程并发的实现(了解)
进程并发的实现在于,硬件中断一个正在运行的进程,把此时进程运行的所有状态保存下来,为此,操作系统维护一张表格,即进程表(process table),每个进程占用一个进程表项(这些表项也称为进程控制块)

该表存放了进程状态的重要信息:程序计数器、堆栈指针、内存分配状况、所有打开文件的状态、帐号和调度信息,以及其他在进程由运行态转为就绪态或阻塞态时,必须保存的信息,从而保证该进程在再次启动时,就像从未被中断过一样。
3,开启子进程的两种方式
1,multiprocessing模块
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程。Python提供了multiprocessing。
multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。
multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
需要再次强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
2,Process类的介绍
创建进程的类:
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
group参数未使用,值始终为None
target表示调用对象,即子进程要执行的任务
args表示调用对象的位置参数元组,args=(1,2,'egon',)
kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
name为子进程的名称
方法介绍:
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
属性介绍:
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
3,Process类的使用
注意:在windows中Process()必须放到# if __name__ == '__main__':下
Since Windows has no fork, the multiprocessing module starts a new Python process and imports the calling module. If Process() gets called upon import, then this sets off an infinite succession of new processes (or until your machine runs out of resources). This is the reason for hiding calls to Process() inside if __name__ == "__main__" since statements inside this if-statement will not get called upon import. 由于Windows没有fork,多处理模块启动一个新的Python进程并导入调用模块。 如果在导入时调用Process(),那么这将启动无限继承的新进程(或直到机器耗尽资源)。 这是隐藏对Process()内部调用的原,使用if __name__ == “__main __”,这个if语句中的语句将不会在导入时被调用。
创建并开启子进程的两种方式
方式一
1 # 方式一: 2 from multiprocessing import Process # 可以开启发起子进程调用 3 import time 4 5 6 def task(name): 7 print('%s is running' % name) 8 time.sleep(1) 9 print('%s is done' % name) 10 11 12 if __name__ == '__main__': 13 # Process(target=task,kwargs={'name':'子进程1'}) # kwargs可以按照字典的方式传参数,args按照位置的方式传参数 14 p = Process(target=task, args=('子进程1',)) # task后不加括号,加括号立马就会执行。args括号里面必须加逗号,组成一个元组 15 p.start() # 仅仅只是给操作系统发送了一个信号,由操作系统将父进程地址空间中的数据拷贝给子进程,作为子进程运行的初始状态,开启后再运行task 16 17 print('主') 18 19 # 执行结果因为执行进程会有一段时间,所以先做打印操作
import time import random from multiprocessing import Process def piao(name): print('%s piaoing' %name) time.sleep(random.randrange(1,5)) print('%s piao end' %name) if __name__ == '__main__': #实例化得到四个对象 p1=Process(target=piao,args=('egon',)) #必须加,号 p2=Process(target=piao,args=('alex',)) p3=Process(target=piao,args=('wupeqi',)) p4=Process(target=piao,args=('yuanhao',)) #调用对象下的方法,开启四个进程 p1.start() p2.start() p3.start() p4.start() print('主')
方式二
1 # 方式二 2 from multiprocessing import Process 3 import time 4 class MyProcess(Process): 5 def __init__(self, name): 6 super().__init__() # 将父类的功能进行重用 7 self.name = name 8 9 def run(self): # 这里一定要用run,下面start将调用这个run 10 print('%s is running' % self.name) 11 time.sleep(3) 12 print('%s is done' % self.name) 13 14 if __name__ == '__main__': 15 p = MyProcess('子进程1') 16 p.start() # 触发上面的run方法 17 print('主')
import time import random from multiprocessing import Process class Piao(Process): def __init__(self,name): super().__init__() self.name=name def run(self): print('%s piaoing' %self.name) time.sleep(random.randrange(1,5)) print('%s piao end' %self.name) if __name__ == '__main__': #实例化得到四个对象 p1=Piao('egon') p2=Piao('alex') p3=Piao('wupeiqi') p4=Piao('yuanhao') #调用对象下的方法,开启四个进程 p1.start() #start会自动调用run p2.start() p3.start() p4.start() print('主')
4,查看进程的pid与ppid
使用pid和ppid可以分别查看子进程和父进程
1 from multiprocessing import Process 2 import time, os 3 4 def task(): 5 print('%s is running,parent id is <%s>' % (os.getpid(), os.getppid())) # 查看子进程和父进程 6 time.sleep(3) 7 print('%s is done,parent id is <%s>' % (os.getpid(), os.getppid())) 8 9 if __name__ == '__main__': 10 p = Process(target=task,) 11 p.start() 12 13 print('主', os.getpid(), os.getppid()) # 查看子进程和父进程,此时父进程为pycharm 14 15 ### 16 主 7032 8916 17 14468 is running,parent id is <7032> 18 14468 is done,parent id is <7032>
5,Process对象的其他属性
join方法
在主进程运行过程中如果想并发地执行其他的任务,我们可以开启子进程,此时主进程的任务与子进程的任务分两种情况
情况一:在主进程的任务与子进程的任务彼此独立的情况下,主进程的任务先执行完毕后,主进程还需要等待子进程执行完毕,然后统一回收资源。
情况二:如果主进程的任务在执行到某一个阶段时,需要等待子进程执行完毕后才能继续执行,就需要有一种机制能够让主进程检测子进程是否运行完毕,在子进程执行完毕后才继续执行,否则一直在原地阻塞,这就是join方法的作用
1 # join方法 2 from multiprocessing import Process 3 import time,os 4 5 def task(): 6 print('%s is running,parent id is <%s>' % (os.getpid(), os.getppid())) 7 time.sleep(3) 8 print('%s is done,parent id is <%s>' % (os.getpid(), os.getppid())) 9 10 if __name__ == '__main__': 11 p = Process(target=task,) 12 p.start() 13 14 p.join() # 加入join方法后一定会等到子进程结束以后才会执行主进程 15 print('主', os.getpid(), os.getppid()) 16 print(p.pid) # 验证了存在僵尸进程 17 18 ### 19 5064 is running,parent id is <5796> 20 5064 is done,parent id is <5796> 21 主 5796 8916 22 5064
join并发
from multiprocessing import Process import time,os def task(name,n): print('%s is running' % name) time.sleep(n) if __name__ == '__main__': start = time.time() p1 = Process(target=task, args=('子进程1', 3)) # args根据位置传参 p2 = Process(target=task, args=('子进程2', 1)) p3 = Process(target=task, args=('子进程3', 2)) p_l = [p1, p2, p3] p1.start() p2.start() p3.start() p1.join() # 这三个仍然是并发执行,只是等待最长的程序执行完才结束 p2.join() p3.join() print('主', (time.time()-start)) ### 子进程1 is running 子进程2 is running 子进程3 is running 主 3.125457525253296
join串行
from multiprocessing import Process import time,os def task(name,n): print('%s is running' % name) time.sleep(n) if __name__ == '__main__': start = time.time() p1 = Process(target=task, args=('子进程1', 3)) # args根据位置传参 p2 = Process(target=task, args=('子进程2', 1)) p3 = Process(target=task, args=('子进程3', 2)) p_l = [p1, p2, p3] from multiprocessing import Process import time,os def task(name,n): print('%s is running' % name) time.sleep(n) if __name__ == '__main__': start = time.time() p1 = Process(target=task, args=('子进程1', 3)) # args根据位置传参 p2 = Process(target=task, args=('子进程2', 1)) p3 = Process(target=task, args=('子进程3', 2)) p_l = [p1, p2, p3] p1.start() # 每个都是执行完以后再进行下一步 p1.join() p2.start() p2.join() p3.start() p3.join() print('主', (time.time()-start)) ### 子进程1 is running 子进程2 is running 子进程3 is running 主 6.322813510894775
查看子进程存活状态alive及取名name
from multiprocessing import Process import time, os def task(): print('%s is running,parent id is <%s>' % (os.getpid(), os.getppid())) time.sleep(3) print('%s is done,parent id is <%s>' % (os.getpid(), os.getppid())) if __name__ == '__main__': p = Process(target=task,) p.start() # print(p.is_alive()) # True p.join() print('主', os.getpid(), os.getppid()) print(p.pid) # print(p.is_alive()) # Flase p = Process(target=task,name='sub——Precsss') p.start() p.terminate() # 这里仅仅是给系统发要求让p死掉,但是是需要时间的,所以立即执行is_alive则进程还是活的 time.sleep(3) print(p.is_alive()) print('主') print(p.name) # 如果没有,则默认位p取名,这里已经取名为sub——Precsss ### 7600 is running,parent id is <16108> 7600 is done,parent id is <16108> 主 16108 11268 7600 False 主 sub——Precsss
进程之间的内存空间是隔离的
from multiprocessing import Process n = 100 # 在windows系统中应该把全局变量定义在if __name__ == '__main__'之上就可以了 def work(): global n n = 0 print('子进程内: ', n) if __name__ == '__main__': p = Process(target=work) p.start() print('主进程内: ', n) ### 主进程内: 100 子进程内: 0 进程之间的内存空间是隔离的
6,守护进程
主进程创建子进程,然后将该进程设置成守护自己的进程,守护进程就好比崇祯皇帝身边的老太监,崇祯皇帝已死老太监就跟着殉葬了。
关于守护进程需要强调两点:
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
如果我们有两个任务需要并发执行,那么开一个主进程和一个子进程分别去执行就ok了,如果子进程的任务在主进程任务结束后就没有存在的必要了,那么该子进程应该在开启前就被设置成守护进程。主进程代码运行结束,守护进程随即终止
1 from multiprocessing import Process 2 import time 3 4 def task(name): 5 print('%s is running' %name) 6 time.sleep(2) 7 # p = Process(target=time.sleep,args=(3,)) # 子进程不允许开启子进程,否则报错 8 # p.start() 9 10 11 if __name__ == '__main__': 12 p = Process(target=task, args=('子进程1',)) 13 p.daemon = True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 14 p.start() 15 # p.join() # 此处如果没有join,则还没等子进程开启,就随着主进程的结束而结束了 16 print('主') #只要终端打印出这一行内容,那么守护进程p也就跟着结束掉了 17 18 ### 19 主
主进程结束,只会让守护进程跟着结束,但是其他子进程还是会继续运行
from multiprocessing import Process import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") if __name__ == '__main__': p1 = Process(target=foo) p2 = Process(target=bar) p1.daemon = True p1.start() p2.start() print("main-------") ### main------- end456 example
7,互斥锁
保证数据输出不会错乱
未加互斥锁
1 from multiprocessing import Process 2 import time 3 4 5 def task(name): 6 print('%s 1' % name) 7 time.sleep(1) 8 print('%s 2' % name) 9 time.sleep(1) 10 print('%s 3' % name) 11 12 13 if __name__ == '__main__': 14 for i in range(3): 15 p = Process(target=task, args=('进程%s' % i,)) 16 p.start() 17 18 ###由于大家争相抢输出这个资源,导致数据输出错乱,但是却输出很快,效率高 19 进程0 1 20 进程1 1 21 进程2 1 22 进程0 2 23 进程1 2 24 进程2 2 25 进程0 3 26 进程1 3 27 进程2 3
添加互斥锁
from multiprocessing import Process, Lock import time def task(name, mutex): mutex.acquire() print('%s 1' % name) time.sleep(1) print('%s 2' % name) time.sleep(1) print('%s 3' % name) mutex.release() if __name__ == '__main__': mutex = Lock() for i in range(3): p = Process(target=task, args=('进程%s' % i, mutex)) # 在这添加互斥锁,使得子进程使用的是父进程传承下来的那把锁,而不是copy过来的 p.start() ### 此时加上了互斥锁,虽然执行效率没有之前那么高,但是却确保了执行顺序 进程0 1 进程0 2 进程0 3 进程1 1 进程1 2 进程1 3 进程2 1 进程2 2 进程2 3
模拟抢票过程
模拟抢票过程,需要通过互斥锁Lock达到串行执行,确保只能有一个人才能购票成功,保证了数据安全
1 from multiprocessing import Process, Lock 2 import json 3 import time 4 5 6 def search(name): 7 time.sleep(1) 8 dic = json.load(open('db.txt', 'r', encoding='utf-8')) 9 print('<%s> 查看到剩余票数【%s】' % (name, dic['count'])) 10 11 12 def get(name): 13 time.sleep(1) 14 dic = json.load(open('db.txt', 'r', encoding='utf-8')) 15 if dic['count'] > 0: 16 dic['count'] -= 1 17 time.sleep(3) 18 json.dump(dic, open('db.txt', 'w', encoding='utf-8')) 19 print('<%s> 购票成功' % name) 20 21 22 def task(name, mutex): 23 search(name) # 查票操作每个人都可以执行,并且是并发执行的 24 mutex.acquire() # 在这里可以添加互斥锁,达到串行执行,使得只能有一个人购票成功 25 get(name) 26 mutex.release() 27 28 29 if __name__ == '__main__': 30 mutex = Lock() 31 for i in range(10): 32 p = Process(target=task,args=('路人%s' % i, mutex)) 33 p.start() 34 35 ### 此时db.txt数据为{"count": 2} 36 <路人0> 查看到剩余票数【2】 37 <路人4> 查看到剩余票数【2】 38 <路人3> 查看到剩余票数【2】 39 <路人1> 查看到剩余票数【2】 40 <路人2> 查看到剩余票数【2】 41 <路人6> 查看到剩余票数【2】 42 <路人5> 查看到剩余票数【2】 43 <路人7> 查看到剩余票数【2】 44 <路人9> 查看到剩余票数【2】 45 <路人8> 查看到剩余票数【2】 46 <路人0> 购票成功 47 <路人4> 购票成功
8,互斥锁与join
利用互斥锁,可以通过添加互斥锁的位置,实现部分程序执行达到串行的效果,其他程序仍然可以并行执行,而添加了join只能执行完了之后才能执行下一个,若作为每项都添加一个join,则都要串行执行。从而大大降低了效率。
1 from multiprocessing import Process, Lock 2 import json 3 import time 4 5 6 def search(name): 7 time.sleep(1) 8 dic = json.load(open('db.txt', 'r', encoding='utf-8')) 9 print('<%s> 查看到剩余票数【%s】' % (name, dic['count'])) 10 11 12 def get(name): 13 time.sleep(1) 14 dic = json.load(open('db.txt', 'r', encoding='utf-8')) 15 if dic['count'] > 0: 16 dic['count'] -= 1 17 time.sleep(3) 18 json.dump(dic, open('db.txt', 'w', encoding='utf-8')) 19 print('<%s> 购票成功' % name) 20 else: 21 print('<%s> 购票失败' % name) 22 23 24 def task(name,): 25 search(name) 26 # mutex.acquire() 27 get(name) 28 # mutex.release() 29 30 31 if __name__ == '__main__': 32 # mutex=Lock() 33 for i in range(10): 34 p = Process(target=task, args=('路人%s' % i,)) 35 p.start() 36 p.join()
<路人0> 查看到剩余票数【3】 <路人0> 购票成功 <路人1> 查看到剩余票数【2】 <路人1> 购票成功 <路人2> 查看到剩余票数【1】 <路人2> 购票成功 <路人3> 查看到剩余票数【0】 <路人3> 购票失败 <路人4> 查看到剩余票数【0】 <路人4> 购票失败 <路人5> 查看到剩余票数【0】 <路人5> 购票失败 <路人6> 查看到剩余票数【0】 <路人6> 购票失败 <路人7> 查看到剩余票数【0】 <路人7> 购票失败 <路人8> 查看到剩余票数【0】 <路人8> 购票失败 <路人9> 查看到剩余票数【0】 <路人9> 购票失败
9,队列的使用
解决大家共享硬盘文件,效率低以及使用内存解决加锁这个繁杂的步骤
multiprocessing模块提供了IPC(internet process communicate)进程之间的通信,队列以及管道,这两种方式都是使用消息传递的,队列就是管道加锁的实现
创建队列的类(底层就是以管道和锁定的方式实现):
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
参数介绍:
maxsize是队列中允许最大项数,可以放置任意类型的数据,省略则无大小限制。
但需要明确:
1、队列内存放的是消息而非大数据
2、队列占用的是内存空间,因而maxsize即便是无大小限制也受限于内存大小
主要方法介绍:
q.put方法用以插入数据到队列中。数据不宜过大。
q.get方法可以从队列读取并且删除一个元素。
队列的使用
1 from multiprocessing import Process,Queue 2 3 q=Queue(3) 4 5 #put ,get ,put_nowait,get_nowait,full,empty 6 q.put(1) 7 q.put(2) 8 q.put(3) 9 print(q.full()) # 判断是否满了 10 # q.put(4) #再放就阻塞住了 11 12 print(q.get()) 13 print(q.get()) 14 print(q.get()) 15 print(q.empty()) # 判断是否空了 16 # print(q.get()) #再取就阻塞住了
10,生产者消费者模型
1,两者的介绍
为什么要使用生产者消费者模型
生产者指的是生产数据的任务,消费者指的是处理数据的任务,在并发编程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者和消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这个阻塞队列就是用来给生产者和消费者解耦的
2,两者的实现
1 from multiprocessing import Process, Queue 2 import time 3 4 def producer(q, name): 5 for i in range(3): 6 res = '包子%s' % i 7 time.sleep(0.5) 8 print('%s 生产了%s' % (name, res)) 9 10 q.put(res) 11 12 def consumer(q, name): 13 while True: 14 res = q.get() 15 if res is None: break 16 time.sleep(1) 17 print('%s 吃了%s' % (name, res)) 18 19 20 if __name__ == '__main__': 21 # 容器 22 q = Queue() 23 24 # 生产者们 25 p1 = Process(target=producer, args=(q, '生产者1')) 26 p2 = Process(target=producer, args=(q, '生产者2')) 27 p3 = Process(target=producer, args=(q, '生产者3')) 28 29 # 消费者们 30 c1 = Process(target=consumer, args=(q, '消费者1')) 31 c2 = Process(target=consumer, args=(q, '消费者2')) 32 33 p1.start() 34 p2.start() 35 p3.start() 36 c1.start() 37 c2.start() 38 39 p1.join() 40 p2.join() 41 p3.join() 42 q.put(None) 43 q.put(None) 44 print('主')
### 生产者1 生产了包子0 生产者2 生产了包子0 生产者3 生产了包子0 生产者1 生产了包子1 生产者2 生产了包子1 生产者3 生产了包子1 生产者1 生产了包子2 消费者1 吃了包子0 生产者2 生产了包子2 消费者2 吃了包子0 生产者3 生产了包子2 主 消费者1 吃了包子0 消费者2 吃了包子1 消费者1 吃了包子1 消费者2 吃了包子1 消费者1 吃了包子2 消费者2 吃了包子2 消费者1 吃了包子2
3,消费者生产者总结
1、程序中有两类角色
一类负责生产数据(生产者)
一类负责处理数据(消费者)
2、引入生产者消费者模型为了解决的问题是
平衡生产者与消费者之间的速度差
程序解开耦合
3、如何实现生产者消费者模型
生产者<--->队列<--->消费者
3,JoinableQueue 的使用
这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
参数介绍
maxsize是队列中允许最大项数,省略则无大小限制。
方法介绍
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
基于JoinableQueue实现生产者消费者模型
1 from multiprocessing import Process, JoinableQueue 2 import time 3 4 5 def producer(q): 6 for i in range(2): 7 res = '包子%s' % i 8 time.sleep(0.5) 9 print('生产者生产了%s' % res) 10 11 q.put(res) 12 q.join() 13 14 15 def consumer(q): 16 while True: 17 res = q.get() 18 if res is None: break 19 time.sleep(1) 20 print('消费者吃了%s' % res) 21 q.task_done() # 发出信号项目已处理完成,省去了后面需另外添加的q.put(None) 22 23 24 if __name__ == '__main__': 25 # 容器 26 q = JoinableQueue() 27 28 # 生产者们 29 p1 = Process(target=producer, args=(q,)) 30 p2 = Process(target=producer, args=(q,)) 31 p3 = Process(target=producer, args=(q,)) 32 33 # 消费者们 34 c1 = Process(target=consumer, args=(q,)) 35 c2 = Process(target=consumer, args=(q,)) 36 c1.daemon = True # 若不添加守护进程,则会卡在消费者 37 c2.daemon = True 38 39 p1.start() 40 p2.start() 41 p3.start() 42 c1.start() 43 c2.start() 44 45 p1.join() 46 p2.join() 47 p3.join() 48 print('主')
生产者生产了包子0
生产者生产了包子0
生产者生产了包子0
生产者生产了包子1
生产者生产了包子1
生产者生产了包子1
消费者吃了包子0
消费者吃了包子0
消费者吃了包子0
消费者吃了包子1
消费者吃了包子1
消费者吃了包子1
主
4,多线程
1,什么是线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于cpu),而一条流水线必须属于一个车间,一个车间的工作过程是一个进程,车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一条流水线。
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个线程,多个线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
2,开启线程的两种方式
方式一:
1 import time 2 import random 3 from threading import Thread 4 5 6 def piao(name): 7 print('%s running' % name) 8 time.sleep(random.randrange(1, 3)) 9 print('%s run end' % name) 10 11 12 if __name__ == '__main__': 13 t1 = Thread(target=piao, args=('xiong',)) 14 t1.start() 15 print('主线程')
方式二:
1 import time 2 import random 3 from threading import Thread 4 5 6 class MyThread(Thread): 7 def __init__(self, name): 8 super().__init__() 9 self.name = name 10 11 def run(self): 12 print('%s running' % self.name) 13 14 time.sleep(random.randrange(1, 3)) 15 print('%s run end' % self.name) 16 17 18 if __name__ == '__main__': 19 t1 = MyThread('xiong') 20 t1.start() 21 print('主线程')
3,多线程与多进程的区别
①开启速度
在主进程下开启线程
1 import time 2 from threading import Thread 3 from multiprocessing import Process 4 5 6 def run(name): 7 print('%s running' % name) 8 time.sleep(2) 9 print('%s run end' % name) 10 11 12 if __name__ == '__main__': 13 t1 = Thread(target=run, args=('xiong',)) 14 t1.start() 15 print('主线程')
执行结果表明,几乎是t.start ()的同时就将线程开启了,然后先打印出了xiong running,证明线程的创建开销极小
xiong running
主线程
xiong run end
在主进程下开启子进程
1 import time 2 from threading import Thread 3 from multiprocessing import Process 4 5 6 def piao(name): 7 print('%s running' % name) 8 time.sleep(1) 9 print('%s run end' % name) 10 11 12 if __name__ == '__main__': 13 p1 = Process(target=piao, args=('xiong',)) 14 p1.start() 15 16 # t1 = Thread(target=piao, args=('xiong',)) 17 # t1.start() 18 print('主进程')
执行结果表明p.start ()将开启进程的信号发给操作系统后,操作系统要申请内存空间,让好拷贝父进程地址空间到子进程,开销远大于线程
1 主进程 2 xiong running 3 xiong run end
②pid的不同
1、在主进程下开启多个线程,每个线程都跟主进程的pid一样【pid(process id:进程的id号)】
1 from threading import Thread 2 import os 3 4 5 def task(): # 此处一定为task 6 print('子线程:%s' % (os.getpid())) # 一个进程内多个线程是平级的 7 8 9 if __name__ == '__main__': 10 t1 = Thread(target=task,) 11 t2 = Thread(target=task,) 12 t1.start() 13 t2.start() 14 15 print('主进程:', os.getpid()) 16 17 # 执行结果,主线程和子线程id都是一个值
执行结果
1 子线程:14912 2 子线程:14912 3 主线程:14912
2,开多个进程,每个进程都有不同的pid
1 from threading import Thread 2 from multiprocessing import Process 3 import os 4 5 6 def task(): 7 print('子进程PID:%s 父进程的PID:%s' % (os.getpid(), os.getppid())) # 查看父进程和子进程的id 8 9 10 if __name__ == '__main__': 11 p1 = Process(target=task,) 12 p1.start() 13 14 print('主进程', os.getpid())
执行结果
1 主进程 13580 2 子进程PID:3084 父进程的PID:13580
3,同一进程内的多个线程共享该进程的地址空间,父进程与子进程不共享地址空间
进程之间的地址空间是隔离的
1 from threading import Thread 2 from multiprocessing import Process 3 4 n = 100 5 def task(): 6 global n 7 n = 0 8 9 10 if __name__ == '__main__': 11 p1 = Process(target=task,) 12 p1.start() 13 p1.join() 14 15 print('主进程', n) 16 17 ### 18 主进程 100
根据执行结果,毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100
同一进程内开启的多个线程是共享该进程地址空间的
1 from threading import Thread 2 from multiprocessing import Process 3 4 n = 100 5 def task(): 6 global n 7 n = 0 8 9 10 if __name__ == '__main__': 11 t1 = Thread(target=task,) 12 t1.start() 13 t1.join() 14 15 print('主线程', n) 16 17 ### 18 主线程 0 19 根据执行结果,查看结果为0,因为同一进程内的线程之间共享进程内的数据
③总结两者的区别
1,启动线程的速度要比启动进程的速度快很多,启动进程的开销更大
2,在主进程下面开启的多个线程,每个线程都和主进程的pid(进程的id)一致
3,在主进程下开启多个子进程,每个进程都有不一样的pid
4,同一进程内的多个线程共享该进程的地址空间
5,父进程与子进程不共享地址空间,表明进程之间的地址空间是隔离的
4,Thread对象的其他属性
Thread实例对象的方法
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
threading模块提供的一些方法:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
1 from threading import Thread, currentThread, active_count, enumerate 2 import time 3 4 5 def task(): 6 print('%s is ruuning' % currentThread().getName()) # 获取当前线程的名字 7 time.sleep(2) 8 print('%s is done' % currentThread().getName()) 9 10 11 if __name__ == '__main__': 12 t = Thread(target=task, name='子线程1') 13 t.start() 14 t.setName('儿子线程1') # 改子线程名字 15 t.join() 16 print(t.getName()) # 获取子线程名字 17 currentThread().setName('主线程') # 修改主线程名字 18 print(t.isAlive()) # 查看线程是否存活 19 20 21 print('主线程',currentThread().getName()) # 查看主线程名字 22 23 t.join() 24 print(active_count()) # 查看活跃的线程数 25 print(enumerate()) # 将当前活跃的线程显示出来 26 27 ### 28 子线程1 is ruuning 29 儿子线程1 is done 30 儿子线程1 31 False 32 主线程 主线程 33 1 34 [<_MainThread(主线程, started 14480)>]
5,守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
需要强调的是:运行完毕并非终止运行
1、对主进程来说,运行完毕指的是主进程代码运行完毕
2、对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
详细解释
1、主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,
2、主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
验证一:当主线程结束的时候,守护线程也跟着结束了
1 from threading import Thread 2 import time 3 4 5 def sayhi(name): 6 time.sleep(2) 7 print('%s say hello' % name) # 因为主进程结束以后,主线程也跟着结束,然后守护线程还没有打印,也跟着死了 8 9 10 if __name__ == '__main__': 11 t = Thread(target=sayhi, args=('xiong',)) 12 # t.setDaemon(True) #必须在t.start()之前设置 13 t.daemon = True # 这种方式和上面代码方式设置守护线程效果一样 14 t.start() 15 16 print('主线程') 17 print(t.is_alive()) 18 19 ###结果不会打印say hello字样 20 主线程 21 True
验证二:只要是有其他非守护线程还没有运行完毕,守护线程就不会被回收,进程只有当非守护线程都运行完毕才会结束
from threading import Thread import time def foo(): print(123) time.sleep(0.5) print("end123") def bar(): print(456) time.sleep(1) print("end456") if __name__ == '__main__': t1 = Thread(target=foo) t2 = Thread(target=bar) t1.daemon = True t1.start() t2.start() print("main-------") ### 123 456 main------- end123 end456
6,互斥锁
对于进程的互斥锁来说,将并行变为了串行,牺牲了效率,保证了安全
对于线程来说,一个进程内的多个线程是共享彼此的地址空间的,因此彼此之间数据也是共享的,由此代来的竞争可能将数据改乱。
1 from threading import Thread, Lock 2 import time 3 4 n = 100 5 6 7 def task(): 8 global n 9 mutex.acquire() # 开始加锁 10 temp = n 11 time.sleep(0.1) # 未加锁之前,100个线程都停留在这并且temp都等于100 12 n = temp-1 13 mutex.release() # 解锁 14 15 16 if __name__ == '__main__': 17 mutex = Lock() 18 t_l = [] 19 for i in range(100): 20 t = Thread(target=task) 21 t_l.append(t) 22 t.start() 23 24 for t in t_l: 25 t.join() 26 27 print('主', n) 28 29 ### 30 主 0
7,GIL全局解释器锁
GIL(Global Interpreter Lock)在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。>有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
1,GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
首先确定一点:每次执行python程序,都会产生一个独立的进程。
验证python test.py只会产生一个进程
1 #test.py内容 2 import os,time 3 print(os.getpid()) 4 time.sleep(1000) 5 6 #打开终端执行 7 python3 test.py 8 9 #在windows下查看 10 tasklist |findstr python 11 12 #在linux下下查看 13 ps aux |grep python
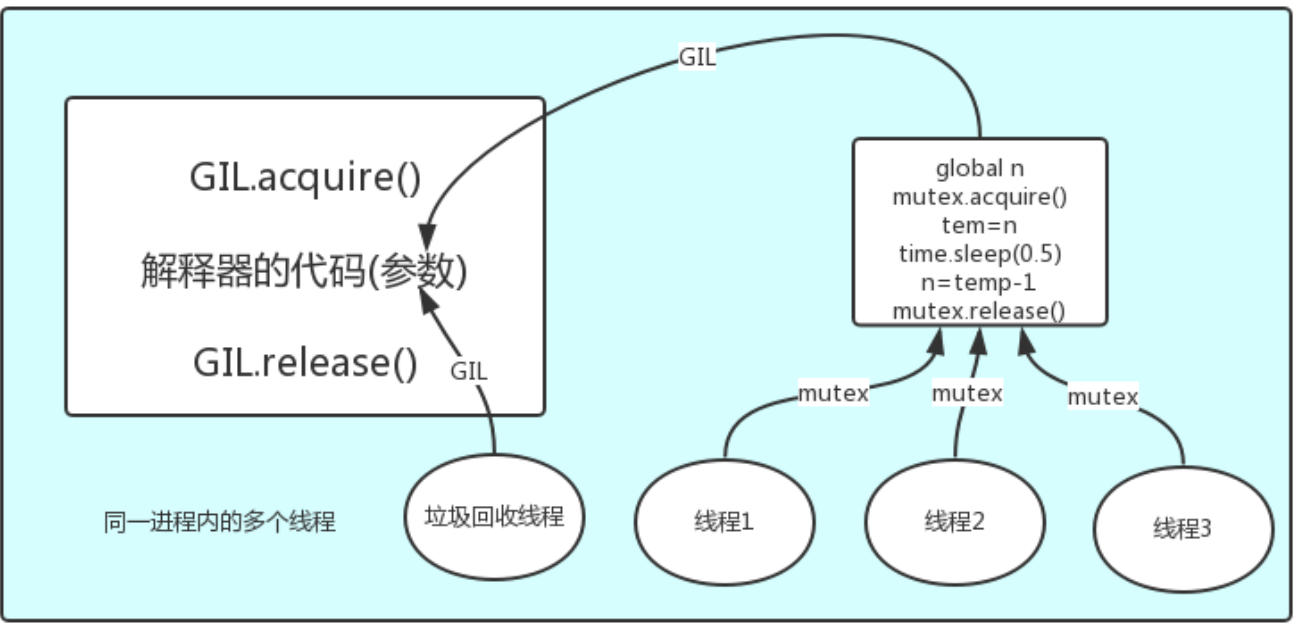
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问
1、所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码) 例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
2、所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
综上:
如果多个线程的target=work,那么执行流程是
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
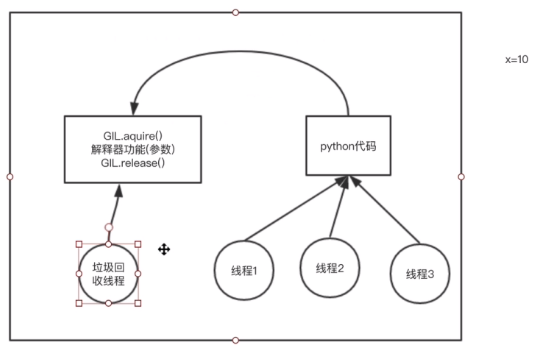
在Cpython解释器当中要利用多核优势,只能是开多进程,每个进程开一个线程去执行
2,GIL与Lock
锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock,如下图

总结:GIL保证一个进程内的多个线程同一时间只能有一个执行,从而保证了python垃圾回收的线程安全,多个线程只能有一个运行。不同的数据,应该加上不同的锁,解释器级别的GIL 锁只能保护解释器级别的数据,用户自己开发的应用程序的数据需要自己加上另外一把锁来去保护。工作流程是线程们首先抢的不是mutex锁,而是GIL锁,将GIL当成是一种执行权限。
3,GIL与多线程
有了GIL的存在,同一时刻同一进程中只有一个线程被执行,进程可以利用多核,但是开销大,而python的多线程开销小,但却无法利用多核优势。
那么如何解决这个问题呢?
首先: 1、cpu到底是用来做计算的,还是用来做I/O的?cpu是用来做计算的
2、多cpu,意味着可以有多个核并行完成计算,所以多核提升的是计算性能
3、每个cpu一旦遇到I/O阻塞,仍然需要等待,所以多核对I/O操作没什么用处
1、对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用
2、当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地
现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
4,多线程性能测试
如果并发的多个任务是计算密集型:多进程效率高
1 from multiprocessing import Process 2 from threading import Thread 3 import os,time 4 def work(): 5 res=0 6 for i in range(100000000): 7 res*=i 8 9 10 if __name__ == '__main__': 11 l=[] 12 print(os.cpu_count()) # 打印本机的核心数 13 start=time.time() 14 for i in range(4): 15 # p=Process(target=work) #耗时5s多 # 显示多进程程序的执行时间 16 p=Thread(target=work) #耗时18s多 # 显示多线程程序执行的时间 17 l.append(p) 18 p.start() 19 for p in l: 20 p.join() 21 stop=time.time() 22 print('run time is %s' %(stop-start))
如果并发的多个任务是I/O密集型:多线程效率高
1 from multiprocessing import Process 2 from threading import Thread 3 import threading 4 import os,time 5 def work(): 6 time.sleep(2) 7 print('===>') 8 9 if __name__ == '__main__': 10 l=[] 11 print(os.cpu_count()) #本机为4核 12 start=time.time() 13 for i in range(400): 14 # p=Process(target=work) #耗时12s多,大部分时间耗费在创建进程上 15 p=Thread(target=work) #耗时2s多 16 l.append(p) 17 p.start() 18 for p in l: 19 p.join() 20 stop=time.time() 21 print('run time is %s' %(stop-start))
应用:
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
5,死锁与递归锁
1,死锁现象
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁:
1 # 死锁 2 from threading import Thread, Lock 3 import time 4 5 mutexA = Lock() 6 mutexB = Lock() 7 8 9 class MyThread(Thread): 10 def run(self): 11 self.f1() 12 self.f2() 13 14 def f1(self): 15 mutexA.acquire() 16 print('%s 拿到了A锁' % self.name) 17 18 mutexB.acquire() 19 print('%s 拿到了B锁' % self.name) 20 mutexB.release() 21 22 mutexA.release() 23 24 25 def f2(self): 26 mutexB.acquire() 27 print('%s 拿到了B锁' % self.name) 28 time.sleep(0.1) 29 30 mutexA.acquire() 31 print('%s 拿到了A锁' % self.name) 32 mutexA.release() 33 34 mutexB.release() 35 36 37 if __name__ == '__main__': 38 for i in range(10): 39 t = MyThread() 40 t.start() 41 42 ### 43 Thread-1 拿到了A锁 44 Thread-1 拿到了B锁 45 Thread-1 拿到了B锁 46 Thread-2 拿到了A锁<br># 出现了死锁,整个程序阻塞住
由于线程的开启消耗非常小,所以启动速度很快,这时线程一无竞争者,拿到了A锁,紧接着拿到了B锁,当两个锁释放以后,线程一继续拿到了A锁,这时其他进程还在抢f1中的A锁,而进程一已经进入f2中拿到了B锁,就在此时,经过休息0.1s的时候,线程二在f1中拿到了A锁,需要继续拿B锁的时候,此时B锁却在f2中被线程一拿着,刚好线程一此时又需要A锁,就这样,线程一拿到了B锁,需要A锁,线程二拿着A锁,需要B锁,然后程序就在这里卡住不能执行下去了
2,解决死锁,递归锁
递归锁出现的问题就是,不同进程或者线程因争夺资源会出现相互等待的现象。
而递归锁可以解决此类问题,这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁,二者的区别是:递归锁可以连续acquire多次,而互斥锁只能acquire一次
1 # 递归锁:可以连续acquire多次,每acquire一次计数器+1,只有计数为0时,才能被抢到acquire 2 from threading import Thread, RLock 3 import time 4 5 mutexB = mutexA = RLock() 6 7 class MyThread(Thread): 8 def run(self): 9 self.f1() 10 self.f2() 11 12 def f1(self): 13 mutexA.acquire() 14 print('%s 拿到了A锁' % self.name) 15 16 mutexB.acquire() 17 print('%s 拿到了B锁' % self.name) 18 mutexB.release() 19 20 mutexA.release() 21 22 23 def f2(self): 24 mutexB.acquire() 25 print('%s 拿到了B锁' % self.name) 26 time.sleep(0.1) 27 28 mutexA.acquire() 29 print('%s 拿到了A锁' % self.name) 30 mutexA.release() 31 32 mutexB.release() 33 34 if __name__ == '__main__': 35 for i in range(10): 36 t = MyThread() 37 t.start()
1 Thread-1 拿到了A锁 2 Thread-1 拿到了B锁 3 Thread-1 拿到了B锁 4 Thread-1 拿到了A锁 5 Thread-2 拿到了A锁 6 Thread-2 拿到了B锁 7 Thread-2 拿到了B锁 8 Thread-2 拿到了A锁 9 Thread-4 拿到了A锁 10 Thread-4 拿到了B锁 11 Thread-4 拿到了B锁 12 Thread-4 拿到了A锁 13 Thread-6 拿到了A锁 14 Thread-6 拿到了B锁 15 Thread-6 拿到了B锁 16 Thread-6 拿到了A锁 17 Thread-8 拿到了A锁 18 Thread-8 拿到了B锁 19 Thread-8 拿到了B锁 20 Thread-8 拿到了A锁 21 Thread-10 拿到了A锁 22 Thread-10 拿到了B锁 23 Thread-10 拿到了B锁 24 Thread-10 拿到了A锁 25 Thread-5 拿到了A锁 26 Thread-5 拿到了B锁 27 Thread-5 拿到了B锁 28 Thread-5 拿到了A锁 29 Thread-9 拿到了A锁 30 Thread-9 拿到了B锁 31 Thread-9 拿到了B锁 32 Thread-9 拿到了A锁 33 Thread-7 拿到了A锁 34 Thread-7 拿到了B锁 35 Thread-7 拿到了B锁 36 Thread-7 拿到了A锁 37 Thread-3 拿到了A锁 38 Thread-3 拿到了B锁 39 Thread-3 拿到了B锁 40 Thread-3 拿到了A锁
8,信号量,Event,定时器
1,信号量
信号量也是一把锁,可以指定信号量为5,对比互斥锁同一时间只能有一个任务抢到锁去执行,信号量同一时间可以有5个任务拿到锁去执行,如果说互斥锁是合租房屋的人去抢一个厕所,那么信号量就相当于一群路人争抢公共厕所,公共厕所有多个坑位,这意味着同一时间可以有多个人上公共厕所,但公共厕所容纳的人数是一定的,这便是信号量的大小
1 from threading import Thread, Semaphore, currentThread 2 import time, random 3 4 sm = Semaphore(3) # 信号量大小 5 6 7 def task(): 8 # sm.acquire() 9 # print('%s in' %currentThread().getName()) 10 # sm.release() 11 with sm: # 上面注释代码可简写成下列代码 12 print('%s in' % currentThread().getName()) 13 time.sleep(random.randint(1, 2)) 14 15 16 if __name__ == '__main__': 17 for i in range(10): 18 t = Thread(target=task) 19 t.start()
Semaphore管理一个内置的计数器, 每当调用acquire()时内置计数器-1; 调用release() 时内置计数器+1; 计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
2,Event
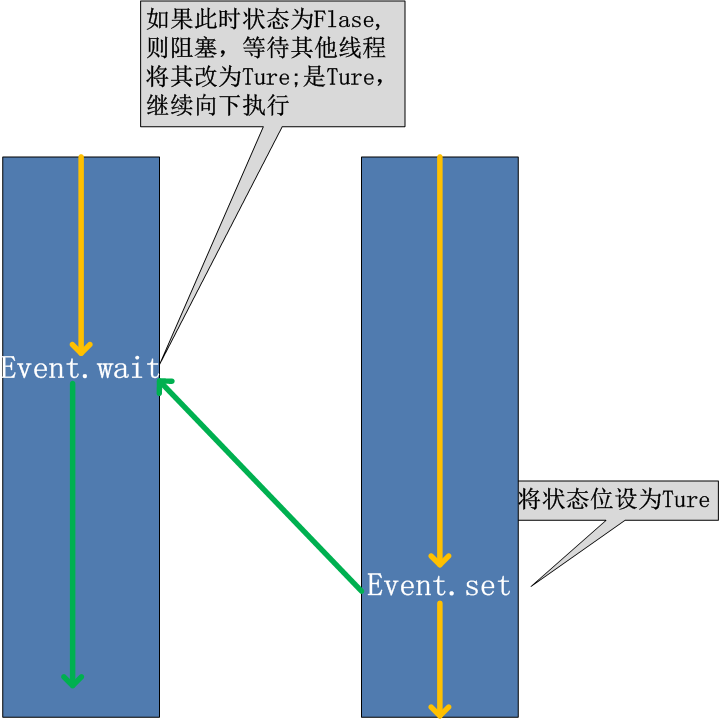
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
from threading import Event event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
1 from threading import Thread,Event 2 import time 3 4 event = Event() 5 # event.wait() # 开启等待 6 # event.set() # 结束等待 7 8 9 def student(name): 10 print('学生%s 正在听课' % name) 11 event.wait(2) 12 print('学生%s 课间活动' % name) 13 14 15 def teacher(name): 16 print('老师%s 正在授课' % name) 17 time.sleep(7) 18 event.set() 19 20 21 if __name__ == '__main__': 22 stu1 = Thread(target=student,args=('alex',)) 23 stu2 = Thread(target=student,args=('wxx',)) 24 stu3 = Thread(target=student,args=('yxx',)) 25 t1 = Thread(target=teacher,args=('egon',)) 26 27 stu1.start() 28 stu2.start() 29 stu3.start() 30 t1.start() 31 32 ### 33 学生wash 正在听课 34 学生wxx 正在听课 35 学生yxx 正在听课 36 老师qiuma 正在授课 37 学生yxx 课间活动 38 学生wash 课间活动 39 学生wxx 课间活动 40 41 Event模拟高中上课过程
wait和set都可以自行设置时间,wait可以等待自己设置的时间
例如,有多个工作线程尝试链接MySQL,我们想要在链接前确保MySQL服务正常才让那些工作线程去连接MySQL服务器,如果连接不成功,都会去尝试重新连接。那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作
1 from threading import Thread,Event,currentThread 2 import time 3 4 event = Event() 5 6 def conn(): 7 n = 0 8 while not event.is_set(): # is_set检查是否被设置 9 if n == 3: 10 print('%s try too many times' % currentThread().getName()) 11 return 12 print('%s try %s' % (currentThread().getName(), n)) 13 event.wait(0.5) # 可以设置等待时间 14 n += 1 15 16 print('%s is connected' % currentThread().getName()) 17 18 19 def check(): 20 print('%s is checking' % currentThread().getName()) 21 time.sleep(2) # 若检查在等待0.5秒之后还未结束,则回返回conn函数中的检测信息 22 event.set() 23 24 25 if __name__ == '__main__': 26 for i in range(3): 27 t = Thread(target=conn) 28 t.start() 29 t = Thread(target=check) 30 t.start()
执行结果
### Thread-1 try 0 Thread-2 try 0 Thread-3 try 0 Thread-4 is checking Thread-2 try 1 Thread-3 try 1 Thread-1 try 1 Thread-2 try 2 Thread-1 try 2 Thread-3 try 2 Thread-2 try too many times Thread-3 try too many times Thread-1 try too many times 执行结果
3,定时器
定时器,指定n秒后执行某操作
1 from threading import Timer 2 3 def hello(): 4 print("hello, world") 5 6 t = Timer(1, hello) 7 t.start() # after 1 seconds, "hello, world" will be printed
实例:验证码的实现
1 from threading import Timer 2 import random 3 4 class Code: 5 def __init__(self): 6 self.make_cache() 7 8 def make_cache(self, interval=60): # interval 设置默认等待时间为5秒钟 9 self.cache=self.make_code() 10 print(self.cache) 11 self.t = Timer(interval, self.make_cache) 12 self.t.start() 13 14 def make_code(self, n=4): 15 res = '' 16 for i in range(n): 17 s1 = str(random.randint(0, 9)) # 随机取出ASCII表里面数字,并转为字符,方便后面拼接 18 s2 = chr(random.randint(65, 90)) # 随机取出ASCII表中大小写字母 19 res += random.choice([s1, s2]) 20 return res 21 22 def check(self): 23 while True: 24 code = input('请输入你的验证码>>: ').strip() 25 if code.upper() == self.cache: 26 print('验证码输入正确') 27 self.t.cancel() 28 break 29 30 31 obj = Code() 32 obj.check()
9,线程queue
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
有三种不同的用法
①class queue.Queue(maxsize=0) #队列:先进先出
1 import queue 2 3 q = queue.Queue(3) # 先进先出->队列 4 5 q.put('first') 6 q.put(2) 7 q.put('third') 8 # q.put(4) 9 # q.put(4,block=False) #q.put_nowait(4) 10 # q.put(4,block=True,timeout=3) # block = True时,阻塞,timeout=3,等待三秒后如果还没有从里面取出数据,则阻塞 11 12 13 print(q.get()) 14 print(q.get()) 15 print(q.get()) 16 # print(q.get(block=False)) # block=False相等于q.get_nowait() 17 # print(q.get_nowait()) 18 19 # print(q.get(block=True,timeout=3)) 20 21 ### 后果先进先出 22 first 23 2 24 third
②class queue.LifoQueue(maxsize=0) #堆栈:last in fisrt out
1 q=queue.LifoQueue(3) #后进先出->堆栈(list in First out Queue) 2 q.put('first') 3 q.put(2) 4 q.put('third') 5 6 print(q.get()) 7 print(q.get()) 8 print(q.get()) 9 10 ###结果 先进后出 11 third 12 2 13 first
③class queue.PriorityQueue(maxsize=0) #优先级队列:存储数据时可设置优先级的队列
1 q=queue.PriorityQueue(3) # 优先级队列 2 3 q.put((10,'one')) 4 q.put((40,'two')) 5 q.put((30,'three')) 6 7 print(q.get()) 8 print(q.get()) 9 print(q.get()) 10 11 ### 结果根据优先级打印出 12 10 13 40 14 30
10,进程池与线程池
基于多进程或多线程实现并发的套接字通信会使服务的开启的进程数或线程数都会随着并发的客户端数目地增多而增多最后可能因不堪重负而瘫痪,而进程池或线程池的用途就是对服务端开启的进程数或线程数加以控制,让机器在一个自己可以承受的范围内运行,例如进程池,就是用来存放进程的池子,本质还是基于多进程,只不过是对开启进程的数目加上了限制
官网:https://docs.python.org/dev/library/concurrent.futures.html concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 ProcessPoolExecutor: 进程池,提供异步调用 Both implement the same interface, which is defined by the abstract Executor class.
基本方法:
1、submit(fn, *args, **kwargs) 异步提交任务 2、map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作 3、shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 4、result(timeout=None) 取得结果 5、add_done_callback(fn) 回调函数
两者用法
分别导入concurrent.futures下面的ProcessPoolExecutor 进程模块以及ThreadPoolExecutor线程模块
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os, time, random 3 4 5 def task(name): 6 print('name:%s pid:%s run' % (name, os.getpid())) 7 time.sleep(random.randint(1, 3)) 8 9 10 if __name__ == '__main__': 11 pool = ProcessPoolExecutor(4) # 设置最大同时运行的进程数 12 # pool = ThreadPoolExecutor(5) # 设置最大同时运行的线程数 13 14 for i in range(10): 15 pool.submit(task, 'xiong %s' % i) # 异步提交任务,提交后不用管进程是否执行 16 17 pool.shutdown(wait=True) # 将进程池的入口关闭,等待任务提交结束后才执行后面的任务 18 # 默认wait=True 19 print('主') 20 21 ###进程池运行结果 22 name:xiong 0 pid:15028 run 23 name:xiong 1 pid:5524 run 24 name:xiong 2 pid:16012 run 25 name:xiong 3 pid:8032 run 26 name:xiong 4 pid:15028 run 27 name:xiong 5 pid:15028 run 28 name:xiong 6 pid:5524 run 29 name:xiong 7 pid:8032 run 30 name:xiong 8 pid:16012 run 31 name:xiong 9 pid:8032 run 32 主
11,异步调用与回调机制
异步调用与回调机制是提交任务的两种方式,
# 提交任务的两种方式 # 1、同步调用:提交完任务后,就在原地等待任务执行完毕,拿到结果,再执行下一行代码,导致程序是串行执行,同步是提交任务的一种方式,不是阻塞的结果 from concurrent.futures import ThreadPoolExecutor import time import random def la(name): print('%s is laing' % name) time.sleep(random.randint(3, 5)) res = random.randint(7, 13)*'#' # 模拟随机长度的字符串,代表每个人拉的量不一样 return {'name': name, 'res': res} def weigh(shit): name = shit['name'] size = len(shit['res']) print('%s 拉了 《%s》kg' % (name, size)) if __name__ == '__main__': pool = ThreadPoolExecutor(13) shit1 = pool.submit(la, 'alex').result() weigh(shit1) shit2 = pool.submit(la, 'wupeiqi').result() # result取得结果 weigh(shit2) shit3 = pool.submit(la, 'yuanhao').result() weigh(shit3) print("#############################") # 2、异步调用:提交完任务后,不地等待任务执行完毕, from concurrent.futures import ThreadPoolExecutor import time import random def la(name): print('%s is laing' % name) time.sleep(random.randint(3, 5)) res = random.randint(7, 13)*'#' return {'name': name, 'res': res} def weigh(shit): shit = shit.result() name = shit['name'] size = len(shit['res']) print('%s 拉了 %skg' % (name, size)) if __name__ == '__main__': pool = ThreadPoolExecutor(13) pool.submit(la, 'alex').add_done_callback(weigh) pool.submit(la, 'wupeiqi').add_done_callback(weigh) pool.submit(la, 'yuanhao').add_done_callback(weigh) # 自动触发weigh这个功能就叫回调函数,前面调用了la函数,后面会自动触发weigh这个功能 ### alex is laing alex 拉了 《11》kg wupeiqi is laing wupeiqi 拉了 《9》kg yuanhao is laing yuanhao 拉了 《13》kg ############################# alex is laing wupeiqi is laing yuanhao is laing alex 拉了 9kg yuanhao 拉了 10kg wupeiqi 拉了 7kg