本节内容:
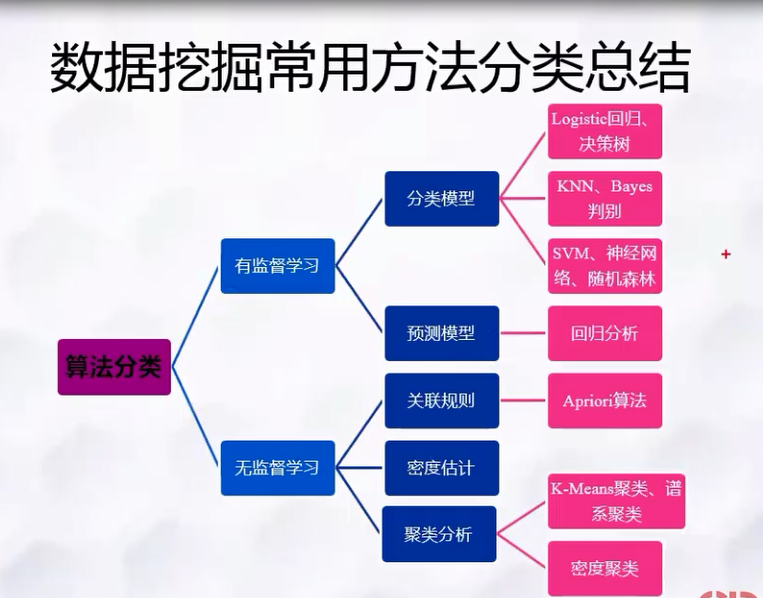
0:数据挖掘的常用方法
1:什么是聚类----聚类是无监督学习
2:聚合和分类的区别---事先定义的类型标记
3:聚类结果的影响有哪些---量纲、行为准则、距离
4:聚类分析的分类--根据x或特征值
5:聚类分析的一般步骤
6:聚类分析的案例
7:聚类的原理--距离和相似度才划分聚类
0:数据挖掘的常用方法
一、什么是聚类
- 聚类也称为聚类分析(某些应用中也称数据分割),指将样本分到不同的组中使得同一组中的样本差异尽可能的小,而不同组中的样本差异尽可能的大。
- 聚类得到的不同的组称为簇(cluster)
- 早在孩提时代,人就通过不断改进下意识的聚类模式才学会如何区分猫和狗、动物和植物
"物以类聚,人以群分"。对事务进行分类,是人们认识事务的出发点,也是人们认识世界的一种重要手段。
无监督学习也称聚类分析,无监督学习源于许多研究领域,受到很多应用的推动。如:
在复杂网络分析中,人们希望发现具有内在紧密联系的社团 在图像分析中,人们希望将图像分割成具有类似性质的区域 在文本处理中,人们希望发现具有相同主题的文本子集 ..... 这些情况都可以在适当的条件下归为聚类分析。
二、聚类和分类的区别
无监督学习和分类不同,没有事先定义的类型标记。
--聚类所说的类不是事先给定的,而是根据数据的相似度和距离来划分
--聚类的数目和结构都没有事先假定
聚类分析的用途:
- 可作单独的数据分析工具
- 可作为其他方法的预处理手段
聚类方法的目的是寻找数据中
【1】潜在的自然分组结构 a structure of "natural" grouping
【2】感兴趣的关系 relationsship
三、聚类结果的影响有哪些
1:量纲(一般我们需要对数据进行标准化)
2:聚类的行为准则
3:距离测度



四、聚类分析的分类
根据样本的的X进行分类,或者是根据对X的n个特征值进行分类


五、聚类分析的一般步骤

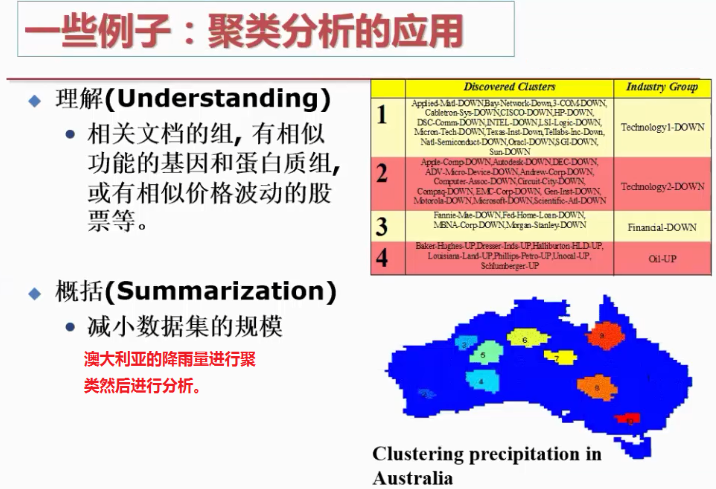
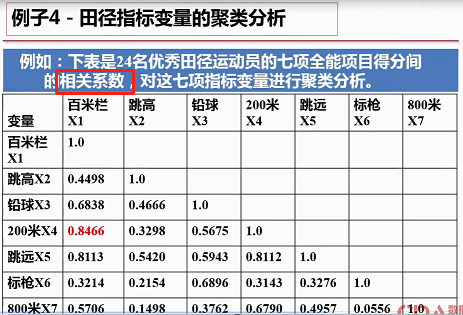
六、聚类分析的案例

七、聚类的原理
原理:距离、相似度进行聚类
明视距离:
- 欧式距离
- 曼哈段距离
相似度:
- 二元相似度
- 向量相似度



