
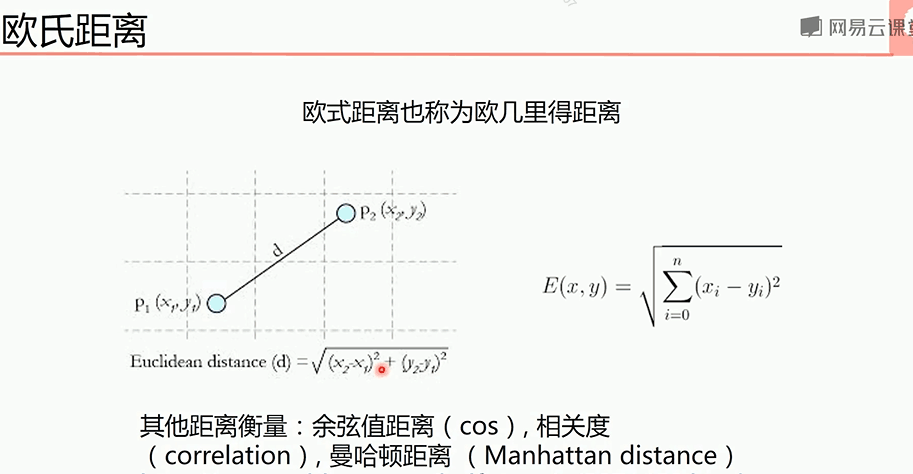
KNN要用到欧氏距离
KNN下面的缺点很容易使分类出错(比如下面黑色的点)

下面是KNN算法的三个例子demo,
第一个例子是根据算法原理实现
import matplotlib.pyplot as plt import numpy as np import operator # 已知分类的数据 x1 = np.array([3,2,1]) y1 = np.array([104,100,81]) x2 = np.array([101,99,98]) y2 = np.array([10,5,2]) scatter1 = plt.scatter(x1,y1,c='r') scatter2 = plt.scatter(x2,y2,c='b') # 未知数据 x = np.array([18]) y = np.array([90]) scatter3 = plt.scatter(x,y,c='k') #画图例 plt.legend(handles=[scatter1,scatter2,scatter3],labels=['labelA','labelB','X'],loc='best') plt.show() # 已知分类的数据 x_data = np.array([[3,104], [2,100], [1,81], [101,10], [99,5], [81,2]]) y_data = np.array(['A','A','A','B','B','B']) x_test = np.array([18,90]) # 计算样本数量 x_data_size = x_data.shape[0] print(x_data_size) # 复制x_test print(np.tile(x_test, (x_data_size,1))) # 计算x_test与每一个样本的差值 diffMat = np.tile(x_test, (x_data_size,1)) - x_data diffMat # 计算差值的平方 sqDiffMat = diffMat**2 sqDiffMat # 求和 sqDistances = sqDiffMat.sum(axis=1) sqDistances # 开方 distances = sqDistances**0.5 print(distances) # 从小到大排序 sortedDistances = distances.argsort()#返回distances里的数据从小到大的下标数组 print(sortedDistances) classCount = {} # 设置k k = 5 for i in range(k): # 获取标签 votelabel = y_data[sortedDistances[i]] # 统计标签数量 classCount[votelabel] = classCount.get(votelabel,0) + 1#)0表示没有该字典里没有该值时默认为0 classCount # 根据operator.itemgetter(1)-第1个值对classCount排序,然后再取倒序 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1), reverse=True) print(sortedClassCount) # 获取数量最多的标签 knnclass = sortedClassCount[0][0]#第一个0表示取第一个键值对('A', 3),第二个0表示取('A', 3)的‘A’ print(knnclass)
1 import numpy as np#对iris数据集进行训练分类 2 from sklearn import datasets 3 from sklearn.model_selection import train_test_split 4 from sklearn.metrics import classification_report,confusion_matrix#对模型分类结果进行评估的两个模型 5 import operator#https://blog.csdn.net/u010339879/article/details/98304292,关于operator的使用 6 import random 7 def knn(x_test, x_data, y_data, k): 8 x_data_size = x_data.shape[0] # 计算样本数量 9 diffMat = np.tile(x_test,(x_data_size,1)) - x_data# 复制x_test,计算x_test与每一个样本的差值 10 sqDiffMat = diffMat**2# # 计算差值的平方 11 sqDistance = sqDiffMat.sum(axis= 1) # 求和 12 distances = sqDistance**0.5 # 开方 13 sortedDistance = distances.argsort()# 从小到大排序 14 classCount = {} 15 for i in range(k): 16 vlabel = y_data[sortedDistance[i]] # 获取标签 17 classCount[vlabel] = classCount.get(vlabel,0)+1# 统计标签数量 18 sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1), reverse = True) # 根据operator.itemgetter(1)-第1个值对classCount排序,然后再取倒序 19 return sortedClassCount[0][0] 20 iris = datasets.load_iris()# 载入数据 21 x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.3) 22 #打乱数据 23 # data_size = iris.data.shape[0] 24 # index = [i for i in range(data_size)] 25 # random.shuffle(index) 26 # iris.data = iris.data[index] 27 # iris.target = iris.target[index] 28 # test_size = 40#切分数据集 29 # x_train = iris.data[test_size:] 30 # x_test = iris.data[:test_size] 31 # y_train = iris.target[test_size:] 32 # y_test = iris.target[:test_size] 33 prodictions = [] 34 for i in range(x_test.shape[0]): 35 prodictions.append(knn(x_test[i],x_train,y_train,5)) 36 print(prodictions) 37 print(classification_report(y_test, prodictions)) 38 print(confusion_matrix(y_test,prodictions)) 39 #关于混淆矩阵可以看这篇博客,#https://www.cnblogs.com/missidiot/p/9450662.html
1 # 导入算法包以及数据集 2 from sklearn import neighbors 3 from sklearn import datasets 4 from sklearn.model_selection import train_test_split 5 from sklearn.metrics import classification_report 6 import random 7 # 载入数据 8 iris = datasets.load_iris() 9 #print(iris) 10 # 打乱数据切分数据集 11 # x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2) #分割数据0.2为测试数据,0.8为训练数据 12 13 #打乱数据 14 data_size = iris.data.shape[0] 15 index = [i for i in range(data_size)] 16 random.shuffle(index) 17 iris.data = iris.data[index] 18 iris.target = iris.target[index] 19 20 #切分数据集 21 test_size = 40 22 x_train = iris.data[test_size:] 23 x_test = iris.data[:test_size] 24 y_train = iris.target[test_size:] 25 y_test = iris.target[:test_size] 26 27 # 构建模型 28 model = neighbors.KNeighborsClassifier(n_neighbors=3) 29 model.fit(x_train, y_train) 30 prediction = model.predict(x_test) 31 print(prediction) 32 print(classification_report(y_test, prediction))
这三个代码第一个,第二个是根据底层原理实现knn算法,第三个则是调用库函数处理数据。
下面一个代码是利用第三个代码中用到的库实现第一个代码功能,可以发现使用系统提供的库,简单许多
1 from sklearn import neighbors 2 from sklearn.model_selection import train_test_split 3 from sklearn.metrics import classification_report 4 import numpy as np 5 x_data = np.array([[3,104], 6 [2,100], 7 [1,81], 8 [101,10], 9 [99,5], 10 [81,2]]) 11 y_data = np.array(['A','A','A','B','B','B']) 12 x_test1 = np.array([[18,90]]) 13 x_train, x_test, y_train,y_test = train_test_split(x_data, y_data,test_size= 0.3) 14 model = neighbors.KNeighborsClassifier(n_neighbors=3) 15 model.fit(x_train, y_train) 16 print(x_test1) 17 prediction = model.predict(x_test1) 18 print(prediction)