HDFS HA主要是通过Quorum Journal Manager (QJM)在Active NameNode和Standby NameNode之间共享edit logs
hdfs-site.xml的配置
dfs.nameservices - nameservice的逻辑名称,可以是任意的名称,此处配置为cluster
<property> <name>dfs.nameservices</name> <value>cluster</value> </property>
dfs.ha.namenodes.[nameservice ID] - 配置nameservice中的每一个NameNode, NameNode的个数建议不超过5个,最好是3个,此处配置两个
<property> <name>dfs.ha.namenodes.cluster</name> <value>nn1,nn2</value> </property>
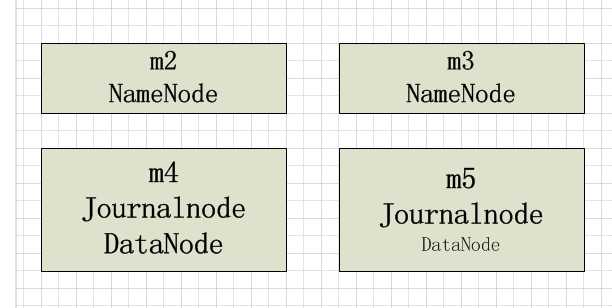
dfs.namenode.rpc-address.[nameservice ID].[name node ID] - 配置NameNode的RPC具体地址,m2和m3为主机名
<property> <name>dfs.namenode.rpc-address.cluster.nn1</name> <value>m2:9820</value> </property> <property> <name>dfs.namenode.rpc-address.cluster.nn2</name> <value>m3:9820</value> </property>
dfs.namenode.http-address.[nameservice ID].[name node ID] - 配置NameNode HTTP监听的地址
<property> <name>dfs.namenode.http-address.cluster.nn1</name> <value>m2:9870</value> </property> <property> <name>dfs.namenode.http-address.cluster.nn2</name> <value>m3:9870</value> </property>
dfs.namenode.shared.edits.dir - 配置JournalNodes上NameNode读和写的edits文件URL地址,URL格式: qjournal://*host1:port1*;*host2:port2*;*host3:port3*/*journalId*.
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://m4:8485;m5:8485;/mycluster</value> </property>
dfs.client.failover.proxy.provider.[nameservice ID] - HDFS客户端联系Active NameNode的java类
<property> <name>dfs.client.failover.proxy.provider.cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyPr ovider</value> </property>
dfs.ha.fencing.methods - 防止脑裂,两种方法,此处使用shell 这种方法
<property> <name>dfs.ha.fencing.methods</name> <value>shell(shell(/bin/true))</value> </property>
dfs.journalnode.edits.dir - JournalNode存储本地状态的路径
<property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/app/hadoop-2.7.3/journalnode/data</value> </property>
core-site.xml配置
<property> <name>fs.defaultFS</name> <value>hdfs://cluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/app/hadoop-2.7.3/tmp/data</value> </property>
至此配置已经结束,接下来启动集群。
1、首先启动journalnode,通过./hadoop-daemon.sh start journalnode命令启动journalnode(m4, m5节点)
jps:可以发现JournalNode进程
2、通过hdfs namenode -format命令初始化集群,格式化完成后拷贝元数据到另外一个namenode节点上
3、启动hadoop集群start-dfs.sh
4、通过hdfs haadmin手动切换namenode是否为active