---------------------------------------------------------------------------------------
本系列文章为《机器学习实战》学习笔记,内容整理自书本,网络以及自己的理解,如有错误欢迎指正。
源码在Python3.5上测试均通过,代码及数据 --> https://github.com/Wellat/MLaction
---------------------------------------------------------------------------------------
1、基于数据集多重抽样的分类器
1.1 bagging
自举汇聚法(bootstrap aggregating),也称为bagging方法,是在从原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集的大小相等,每个数据集都是在原始数据集中有放回随机选择样本得到,这意味着新数据集中可以有重复的样本,也可能没有包括原数据集的所有样本。
在S个数据集建好之后,将某个学习算法分别作用于每个数据集就得到了S个分类器。当我们要对新数据进行分类时,就可以应用这S个分类器进行分类。与此同时,选择分类器投票结果中最多的类别作为最后的分类结果。
1.2 boosting
boosting和bagging很类似,他们使用相同类型的分类器,但是在boosting中,不同的分类器是通过串行训练而获得的。Boosting集中关注被已有分类器错分的那些数据来获得新的分类器。
由于boosting分类的结果是基于所有分类器的加权求和的结果,所以在boosting中分类器的权重并不相等,每个权重代表的是其对于分类器在上一轮迭代中的成功度。
Boosting方法有多个版本,本节只关注其中一个最流行的版本AdaBoost。
1.3 AdaBoost
AdaBoost是adaptive boosting(自适应boosting)的缩写,它的理论根植于使用弱分离器和多个实例来构建一个强分类器。这里的“弱”意味着分类器的性能比随机猜测要略好,但是也不会好太多;而“强”分类器的错误率将会低很多。
其运行过程如下:训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。在分类器的第二次训练当中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。其中,错误率ε的定义为:

而alpha的计算公式为:

AdaBoost算法流程如下图:
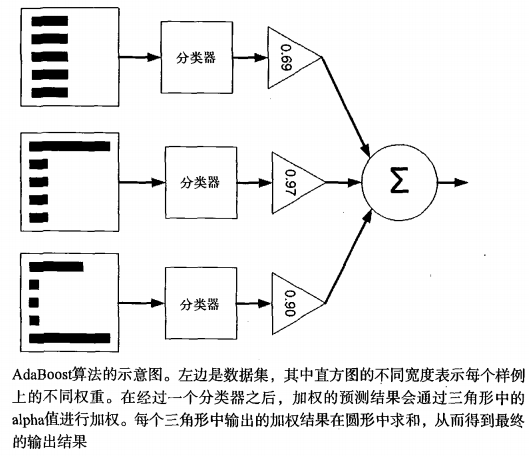
计算出alpha值之后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高。
如果某个样本被正确分类,权重更改为: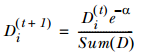
而如果被错分,权重则更改为:
在计算出D之后,AdaBoost又开始进入下一轮迭代,知道训练错误率为0或者弱分类器的数目达到用户指定值为止。
2、AdaBoost算法的实现
2.1 构建弱分类器
单层决策树是AdaBoost中最流行的弱分类器。
算法伪代码↓

1 def buildStump(dataArr,classLabels,D): 2 ''' 3 建立一个单层决策树 4 输人为权重向量D, 5 返回具有最小错误率的单层决策树、最小的错误率以及估计的类别向量 6 ''' 7 dataMatrix = mat(dataArr); labelMat = mat(classLabels).T 8 m,n = shape(dataMatrix) 9 numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1))) 10 minError = inf # 11 for i in range(n):#对数据集中的每一个特征 12 rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max(); 13 stepSize = (rangeMax-rangeMin)/numSteps 14 for j in range(-1,int(numSteps)+1):#对每个步长 15 for inequal in ['lt', 'gt']: #对每个不等号 16 threshVal = (rangeMin + float(j) * stepSize) 17 predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal) 18 errArr = mat(ones((m,1))) 19 errArr[predictedVals == labelMat] = 0 20 weightedError = D.T*errArr #计算加权错误率 21 #print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)) 22 #如果错误率低于minError,则将当前单层决策树设为最佳单层决策树 23 if weightedError < minError: 24 minError = weightedError 25 bestClasEst = predictedVals.copy() 26 bestStump['dim'] = i 27 bestStump['thresh'] = threshVal 28 bestStump['ineq'] = inequal 29 return bestStump,minError,bestClasEst 30 31 def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): 32 ''' 33 通过阈值比较对数据进行分类 34 ''' 35 retArray = ones((shape(dataMatrix)[0],1)) 36 if threshIneq == 'lt': 37 retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 38 else: 39 retArray[dataMatrix[:,dimen] > threshVal] = -1.0 40 return retArray
2.2 基于单层决策树的AdaBoost训练过程
算法伪代码↓

1 def loadSimpData(): 2 ''' 3 导入简单训练数据 4 ''' 5 datMat = matrix([[ 1. , 2.1], 6 [ 2. , 1.1], 7 [ 1.3, 1. ], 8 [ 1. , 1. ], 9 [ 2. , 1. ]]) 10 classLabels = [1.0, 1.0, -1.0, -1.0, 1.0] 11 return datMat,classLabels 12 13 def adaBoostTrainDS(dataArr,classLabels,numIt=40): 14 ''' 15 基于单层决策树的AdaBoost训练过程 16 ''' 17 weakClassArr = [] 18 m = shape(dataArr)[0] 19 D = mat(ones((m,1))/m) #初始化权重向量为1/m 20 aggClassEst = mat(zeros((m,1)))#记录每个数据点的类别估计累计值 21 for i in range(numIt): 22 #建立一个单层决策树 23 bestStump,error,classEst = buildStump(dataArr,classLabels,D) 24 print("D:",D.T) 25 #计算alpha,此处分母用max(error,1e-16)以防止error=0 26 alpha = float(0.5*log((1.0-error)/max(error,1e-16))) 27 bestStump['alpha'] = alpha 28 weakClassArr.append(bestStump) 29 print("classEst: ",classEst.T) 30 #计算下一次迭代的D 31 expon = multiply(-1*alpha*mat(classLabels).T,classEst) 32 D = multiply(D,exp(expon)) 33 D = D/D.sum() 34 #以下计算训练错误率,如果总错误率为0,则终止循环 35 aggClassEst += alpha*classEst 36 print("aggClassEst: ",aggClassEst.T) 37 aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) 38 errorRate = aggErrors.sum()/m 39 print("total error: ",errorRate) 40 if errorRate == 0.0: break 41 return weakClassArr,aggClassEst
2.3 简单测试分类效果
1 def adaClassify(datToClass,classifierArr): 2 ''' 3 利用训练出的多个弱分类器进行分类 4 datToClass:待分类数据 5 classifierArr:训练的结果 6 ''' 7 dataMatrix = mat(datToClass) 8 m = shape(dataMatrix)[0] 9 aggClassEst = mat(zeros((m,1))) 10 #遍历classifierArr中的所有弱分类器,并基于stumpClassify对每个分类器得到一个类别的估计值 11 for i in range(len(classifierArr)): 12 classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'], 13 classifierArr[i]['thresh'], 14 classifierArr[i]['ineq']) 15 aggClassEst += classifierArr[i]['alpha']*classEst 16 print(aggClassEst) 17 return sign(aggClassEst)
按如下指令测试:
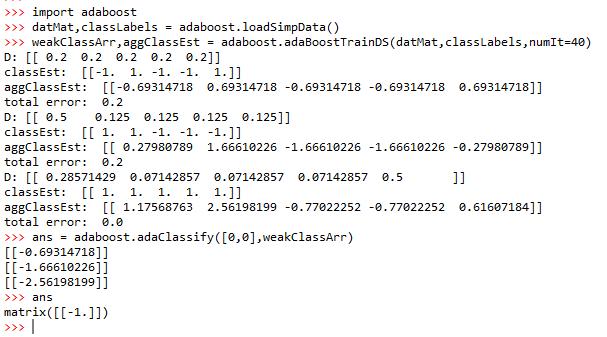
3、实例:在马疝病数据集上应用AdaBoost分类器
前面一个章节中曾利用Logistic回归来预测患有疝病的马是否能够存活,而在本节我们将利用多个单层决策树和AdaBoost来预测。
1 def loadDataSet(fileName): 2 '''读取数据函数''' 3 numFeat = len(open(fileName).readline().split(' ')) #获取列数,默认最后一列为类标签且类标签为+1和-1 4 dataMat = []; labelMat = [] 5 fr = open(fileName) 6 for line in fr.readlines(): 7 lineArr =[] 8 curLine = line.strip().split(' ') 9 for i in range(numFeat-1): 10 lineArr.append(float(curLine[i])) 11 dataMat.append(lineArr) 12 labelMat.append(float(curLine[-1])) 13 return dataMat,labelMat 14 15 if __name__ == "__main__": 16 17 '''马疝病测试''' 18 #导入训练数据 19 datArr,labelArr = loadDataSet('horseColicTraining2.txt') 20 weakClassArr,aggClassEst = adaBoostTrainDS(datArr,labelArr,10) 21 #导入测试数据 22 testArr,testLabelArr = loadDataSet('horseColicTest2.txt') 23 prediction = adaClassify(testArr,weakClassArr) 24 #计算错误率 25 errArr = mat(ones((67,1))) 26 errArr[prediction != mat(testLabelArr).T].sum()/67
将弱分类器的数目设定为1到10000之间的几个不同数字,并运行上述过程。得到如下结果

在同一数据集上采用Logistic回归得到的平均错误率为0.35,而使用AdaBoost方法,从表中可以看出,仅仅使用50个弱分类器就达到了较高的性能。
THE END.