nginx自带文件读取功能,而且实现地很好。
比如直接读取txt文件,png图片等,用chrome可以直接获取到内容。
但是对于很大的文件,比如有2个G的视频,nginx如何吐出2G的内容呢?
实验:
准备很大的MP4文件(比如2G),nginx搭建好webserver,nginx开启access_log选项(log中要包含下载文件大小,http code,请求时间)
实验步骤:
1,用chrome访问nginx搭建网站的MP4,我自己的是:http://lww.diff.com/data/1.mp4
2,打开chrome的控制面板,切换到network tab页

可以看到有6个请求,第一个请求的状态码是200,剩余请求的状态码都是206(partial content-部分内容)。
可以看到chrome非常贴心地用内置的视频解码工具来播放MP4文件,非常有用的是暂停按钮(如果开始播放后不暂停,nginx会不断地给chrome吐数据,这个过程不会中断,暂停按钮会中断此次通信,断开connection,此时nginx才会写入access log)。
可以看到这个交互过程是:
1,chrome发起新的请求,nginx吐数据;
2,点暂停,chrome断开nginx连接;
3,再点开始,chrome重新连接到nginx,nginx吐数据一直到再次点暂停;
那么第一次,和第二次请求有什么不同?
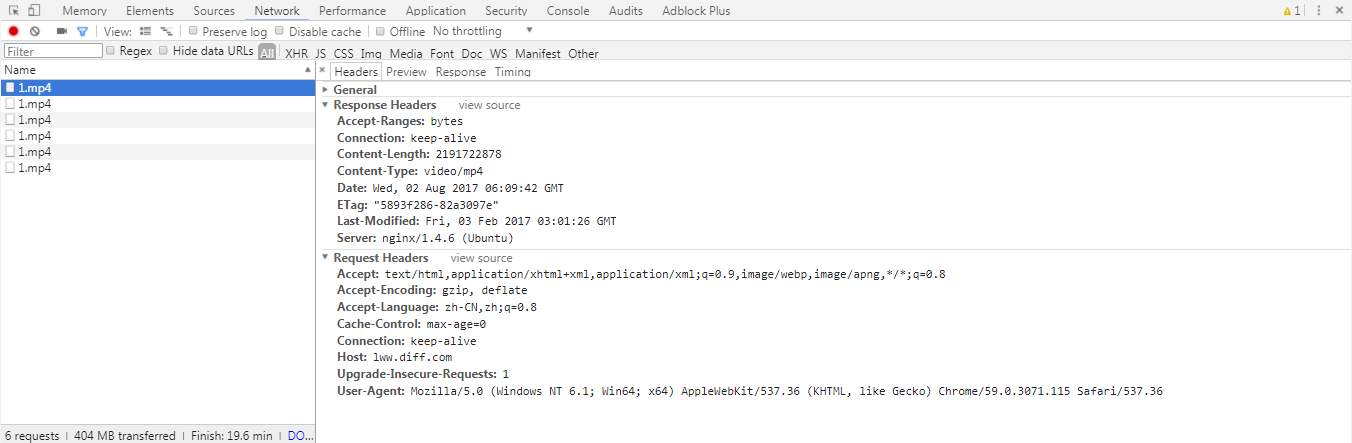
第一次请求:
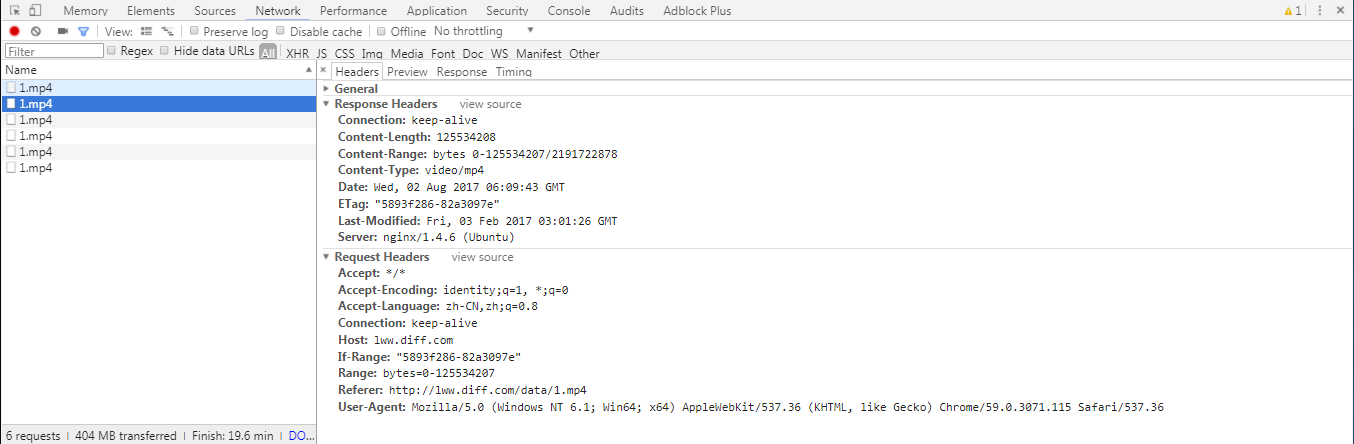
第二次请求:
可以看到第一次获取了内容的基本信息(文件类型,文件长度)
第二次请求获取了真正的数据内容(Range:bytes=0-125534207),具体能获取到多少Bytes的内容,是动态计算的,以connection的四次握手结束后计算得来的。
chrome会保存这个量(已经下载的Bytes),下次使用这个偏移量作为起始点,nginx会从该偏移量开始取数据,而不是从头开始。这个地方如果文件内容有变化,会返回200,从0开始取数据;如果内容没变化,会返回206,表示取的还是原来的文件。
再看一下最后一次请求的header信息:
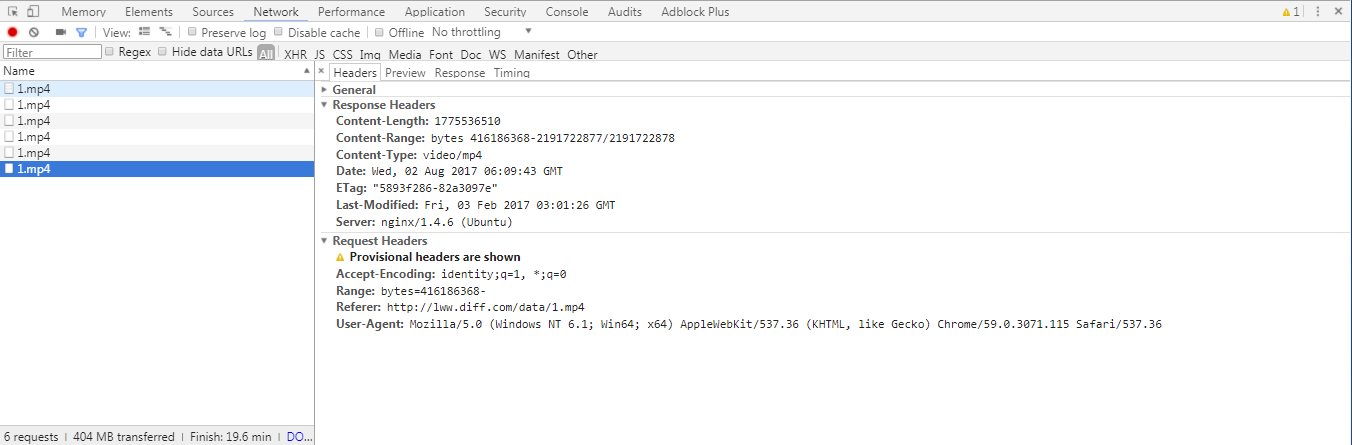
request的header是:Range: bytes=416186368- (这个表示偏移量是400M)
response的header是:Content-Range:bytes (416186368-2191722877)/2191722878(分别表示请求偏移量,文件尾的index-从0开始的,总的文件大小)
结论:现代浏览器都已经内置了对于大文件的默认处理(会自动记录已下载文件的数据量),nginx等WebServer都必须支持文件按Range获取内容。
header中的Range,和Content-Range是静态的(从请求开始就知道),但是请求数据量是动态的,从connection开始到结束统计得来。