该篇文档基于kaggle course,通过简单的理论介绍、程序代码、运行图以及动画等来帮助大家入门深度学习,既然是入门,所以没有太多模型推导以及高级技巧相关,都是深度学习中最基础的内容,希望大家看过之后可以自己动手基于Tensorflow或者Keras搭建一个处理回归或者分类问题的简单的神经网络模型,并通过dropout等手段优化模型结果;
每部分都有对应的练习,练习都是很有针对性的,而且都很有趣,尤其是一些练习中都写好了动画的可视化展示,还是很有心的;
目录:
- 概述
- 线性模型:单神经元
- 非线性模型:深度神经网络
- 模型训练:随机梯度下降
- 验证模型:过拟合和欠拟合
- 提升性能:Dropout和Batch Normalization
- 分类问题
概述
经过本篇文章,你将搭建自己的深度神经网络,使用Keras和Tensorflow,创建全连接神经网络,在分类和回归问题上应用神经网络,通过随机梯度下降训练网络、通过dropout等技术提升模型性能;
近些年在AI方面的主要发展都在深度学习,尤其是应用于自然语言处理、图像识别、游戏AI等领域,深度学习能得到更接近于人类的结果;
深度学习是一种允许大量深度计算为特征的机器学习方法,深度计算使得深度学习模型可以理解真实世界数据中的复杂和高维的信息模式,比如这句话的含义是什么、这张图中的人在干嘛等等;
通过这种优势和灵活性,神经网络成为深度学习的定义模型,神经网络由神经元组成,每个神经元单独看只是一个简单的计算单元,神经网络的能力来自于许多神经元之间的复杂的组合模式;
单个神经元
线性单元
只有一个输入的线性单元对应公式如下:
x为输入,神经元连接的权重为w,w的更新就是神经网络学习的过程,b为偏差,它与输入没有关系,偏差允许神经元不依赖输入来修改输出,y是神经元的输出,即公式y=w*x+b的结果;
线性单元作为模型的例子
神经元通常作为神经网络的一部分,往往也会将一个单独的神经元模型作为基准模型,单神经元模型是线性模型;
假设我们使用糖分作为输入训练模型,卡路里作为输出,假设偏差b为90,权重w为2.5,当糖分为5时,卡路里为2.5*5+90=102.5;
多个输入
当我们期望使用多个输入而不是一个时,其实就是将多个输入连接并神经元,计算每个连接权重,并全部加起来得到最终输出,如下:
上述公式使用了三个输入,并分别对应各自的连接权重,从输入维度上看,单个输入拟合一条直线,两个输入你和一个平面,多个输入拟合的则是超平面;
Keras中使用线性单元
最简单的创建线性单元模型是通过keras.Sequential,可以通过dense层来创建上述提到的线性单元模型,对于一个有三个输入,一个输出的线性模型,Keras创建方式如下:
from tensorflow import keras
from tensorflow.keras import layers
# Create a network with 1 linear unit
model = keras.Sequential([
layers.Dense(units=1, input_shape=[3])
])
其中units为1表示该层只有一个输出,input_shape为[3]则表示有3个输入,之所以参数是个列表[],这是因为在图像领域可能需要三维输入,比如[高度,宽度,通道];
线性单元练习
可以通过这个notebook来进行这部分的练习,里面包含了如何通过keras搭建线性单元的神经元模型,并通过其weights属性来查看模型的连接权重和偏差,最后还有一个未训练的模型在预测中的表现,可以看到其随机权重在每次运行结果都不一样;
深度神经网络
层
典型的神经网络通过层来组织他们的神经元,当我们把线性单元整理到一起时,我们就得到了一个dense层,神经网络通过叠加dense层来将输入以越来越复杂的方式进行转换,在一个训练好的神经网络模型,每一层都会将输入转换的更接近结果一点;
激活函数
激活函数作用于层的输出,最常用的是整流函数max(0,x),纠正函数将负部分处理为0,当我们将整流函数应用于一个线性单元时,也就得到了ReLU,而之前的线性公式:
也变成了:
可以看到,函数也从线性转为了非线性,整流函数图像如下:

堆叠dense层
输出层之前通常有一些隐含层,一般我们不能直接看到他们的输出(因为他们的输出并不是最后输出,而是作为下一层的输入,因此无法直接看到),注意当处理回归问题时,最后一层也就是输出层是线性单元,也就是没有应用激活函数,当我们要处理分类或者其他问题时,仍然需要对应的激活函数;
通过keras.Sequential创建多层神经网络方式很简单,只要从第一层到最后一层依次通过layer定义即可,第一层获取输入,最后一层产生输出,代码如下:
from tensorflow.keras import layers
model = keras.Sequential([
# the hidden ReLU layers
layers.Dense(units=4, activation='relu', input_shape=[2]),
layers.Dense(units=3, activation='relu'),
# the linear output layer
layers.Dense(units=1),
])
其中各个layer表示各个堆叠的网络层,activation表示各个层的激活函数,可以看到最后一层是没有的,这是因为它处理的是回归问题,且最后一层输出只有一个,而其他层则不一定;
深度神经网络练习
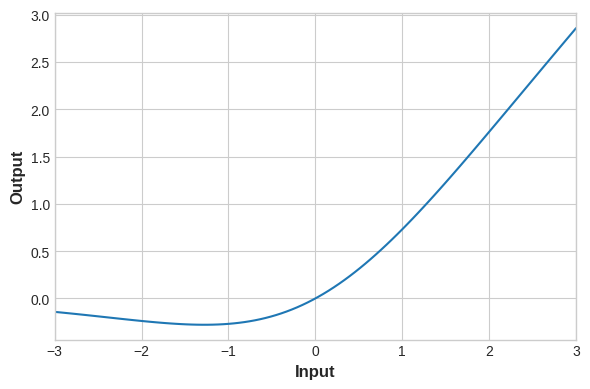
你可以通过这个notebook来进行这部分练习,其中包含如何通过keras.Sequential搭建3个隐含层1个输出层的非线性神经网络模型,以及如何使用单独的激活层来代替activation参数,以及ReLU、eLU、SeLU、swish等各个激活函数的差异,实验证明ReLU适用于大多数场景,因此最适合作为初始激活函数选择,下面给出各个接获函数的图像:
relu:
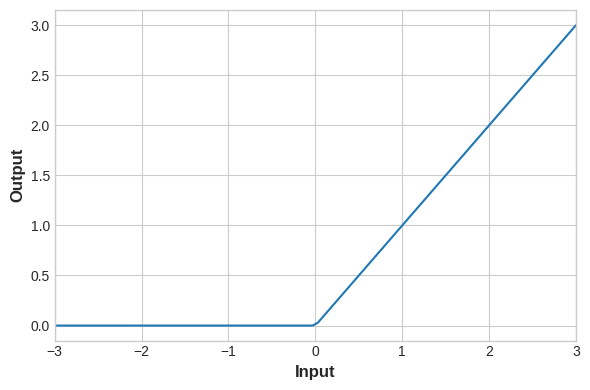
elu:
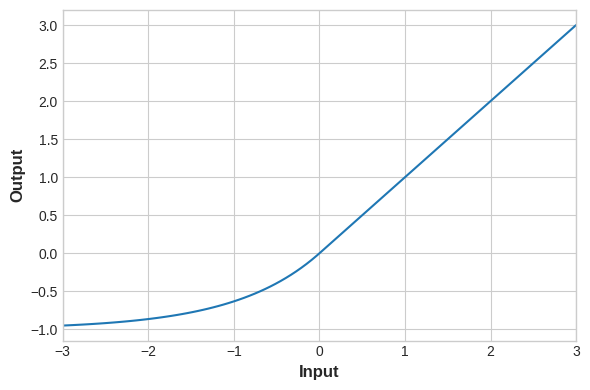
selu:
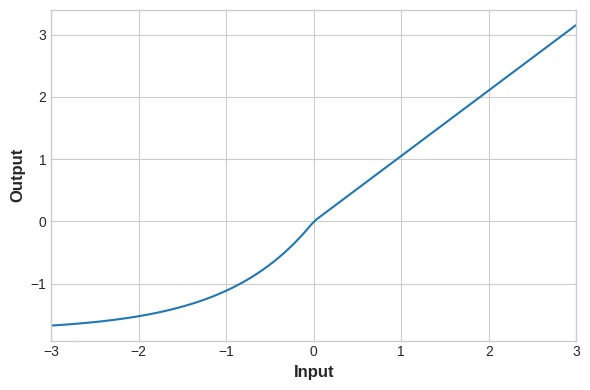
swish:
随机梯度下降
在之前创建的神经网络模型中,网络中的权重都是随机指定的,此时的模型还没有学习到任何东西,这也是第一个练习中每次运行结果都不一样的原因;
所谓训练一个神经网络,指的是通过某种方式不断更新网络中的权重,使得模型通过输入可以得到期望的输出,如果可以做到,那么也说明了这些权重在某种程度上表达了输入特征与输出之间的关系;
训练模型需要两个必要元素:
- 损失函数:衡量模型预测结果好坏;
- 优化方法:指导模型如何去修改权重;
损失函数
损失函数用于衡量模型的预测值与真实值之间的差异,不同的问题使用的损失函数一般也是不同的,例如对于回归问题,即我们要预测的是数值,一个常用的用于回归问题的损失函数为MAE,即平均绝对误差,对于每个预测值y_pred,MAE计算它与y_true的差值的绝对值,所有这些绝对值取平均就是MAE的结果,除了MAE,用于回归问题的还有很多损失函数,比如MSE、MASE、Huber loss等等,对于模型来说,在训练过程中,损失函数起到向导的作用,最小化损失函数就是模型要解决的问题,以此来指导网络中权重的更新方向;
优化方法 - 随机梯度下降
通过损失函数我们确定了模型要解决的问题,但是依然需要告知模型如何去解决这个问题,此时就需要一种优化方法,优化方法是一种最小化损失的算法;
实际上所有应用于深度学习的优化算法都属于随机梯度下降族,它们都是迭代算法,一步一步的训练模型,每一步的训练过程如下:
- 抽样部分训练数据,通过模型运行得到预测结果
y_pred; - 测量这些
y_pred与y_true之间的损失函数值; - 通过损失更小的方向来修改权重;
上述过程一遍一遍的运行,直到损失为0或者损失无法再下降为止;
迭代中从训练集中抽样的部分称之为minibatch,或者一般直接叫做batch,每一轮完整的训练称之为epoch,epoch的数量决定了模型使用各个数据点的次数;
理想的训练过程中,权重不断更新,损失不断减少,预测值越来越接近于真实值;
学习率和Batch Size
学习率决定了模型在每一个batch上学习到的内容的大小,学习率越小意味着模型需要更多的batch来帮助其学习,学习率和batch size是两个训练过程中影响很大的参数,通常也是主要要调的超参数;
可惜的是,对于很多情况下都没有必要通过非常耗时的超参数调整来获取最优的结果,Adam是一种不需要设置学习率的随机梯度下降算法,它不需要调试任何参数,或者说它是自调整的,因此它成为一种很好的通用优化方法;
添加损失函数和优化方法
在定义模型后,可以通过模型的compile方法添加损失函数和优化方法:
model.compile(
optimizer="adam",
loss="mae",
)
例子 - 红酒品质
数据格式如下,最后一列为预测目标列:
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.8 | 0.470 | 0.43 | 2.10 | 0.171 | 27.0 | 66.0 | 0.99820 | 3.17 | 0.76 | 10.8 | 6 |
| 8.1 | 0.820 | 0.00 | 4.10 | 0.095 | 5.0 | 14.0 | 0.99854 | 3.36 | 0.53 | 9.6 | 5 |
| 9.1 | 0.290 | 0.33 | 2.05 | 0.063 | 13.0 | 27.0 | 0.99516 | 3.26 | 0.84 | 11.7 | 7 |
| 10.2 | 0.645 | 0.36 | 1.80 | 0.053 | 5.0 | 14.0 | 0.99820 | 3.17 | 0.42 | 10.0 | 6 |
可以看到,除了最后一列总有11列作为输入,神经网络搭建代码如下:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
看到网络由3个隐含层和1个输出层组成,其中隐含层的units均为512,表示每个隐含层输出都有512个,第一层负责接受输入,最后一层输出结果;
定义完了网络结构,下面需要设置训练需要使用的损失函数和优化方法:
model.compile(
optimizer='adam',
loss='mae',
)
任务为回归预测,损失函数选择平均绝对误差,优化器使用adam;
训练前的准备已经就绪,下面需要告诉模型训练使用的batch数量、迭代次数等信息:
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=10,
)
对于训练过程中的loss进行可视化后可以更好的观察模型的整个迭代过程:
import pandas as pd
# convert the training history to a dataframe
history_df = pd.DataFrame(history.history)
# use Pandas native plot method
history_df['loss'].plot();
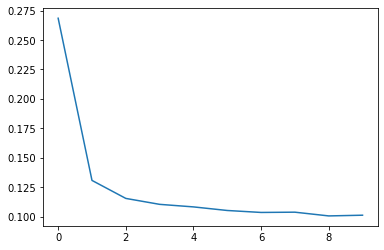
可以看到,在迭代次数达到6次时,后续的迭代中loss的下降不明显,甚至还有变大的情况出行,一般来说这说明迭代次数足够了;
模型训练练习
这部分练习可以通过这个notebook,其中包含了完整的神经网络模型,从定义到设置其损失和优化方法,再到最后的训练过程,并通过很有趣的动画方式展示了在不同的学习率、batch size、样本数量等情况下的模型迭代过程,对于理解各个参数的作用非常有帮助哦,这里展示其中一组参数下的训练过程:
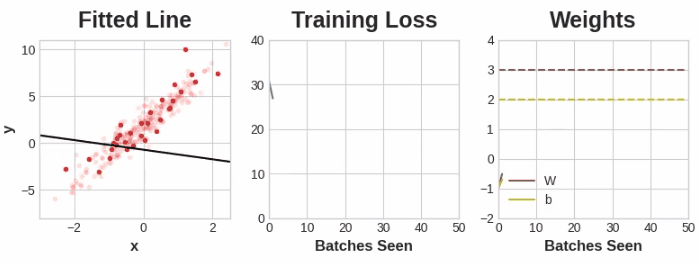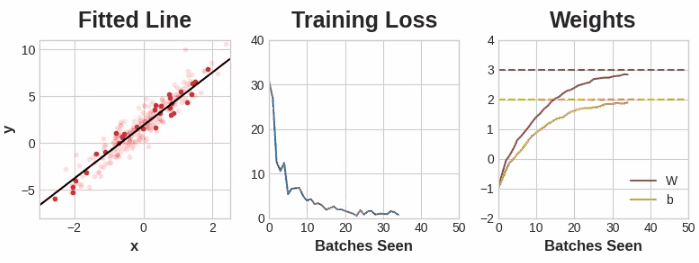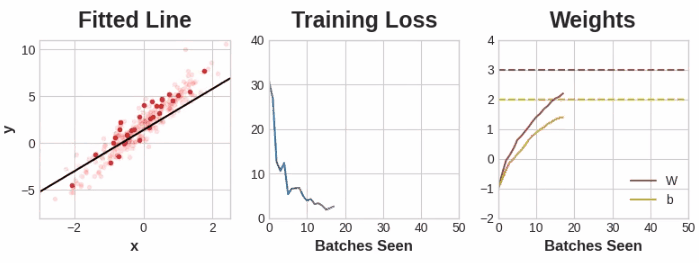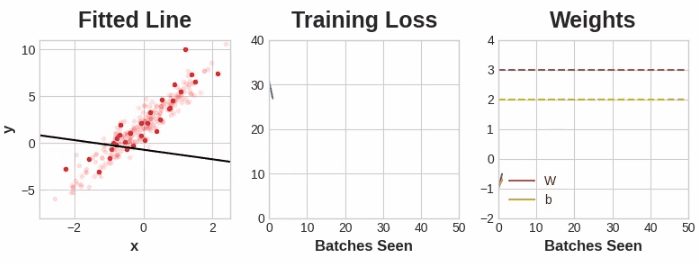
过拟合和欠拟合
过拟合和欠拟合是机器学习中绕不开的两个问题,通常我们可以使用学习曲线来观察模型迭代表现并判断其当前属于过拟合还是欠拟合,通常来说过拟合指的是模型过于复杂,将数据中的噪声部分也拟合了,因此使得模型在真实数据上的表现明显差于在训练集的表现,而欠拟合则指的是模型在训练集上都没有达到足够好的效果,可能是因为模型太简单,也可能是因为数据量太大;
容量
容量指的是模型可以学习到的数据模式的复杂度大小,或者说容量越大的模型,越能深入的理解数据,对于神经网络来说,可以通过增加其宽度和高度来扩大其模型容量;
所谓增大网络宽度指的是增加已有层中的神经元个数,而增大高度指的是增加新的层,一般来说使用同样的神经元个数,增加高度带来的容量增益要大于增加宽度,简单理解如下:
假设当前网络有两层,每一层都有3个神经元,则其组合为3*3=9,此时我们要增加2个神经元:
如果是用于增加宽度,每层增加一个神经元变为4个,则有4*4=16;
如果是用于增加高度,增加一个单独的层,有2个神经元,则有3*3*2=18;
因此都是使用了两个神经元,从结果上看是高度的收益更大,当然这个只是一种直观理解,实际的解释要比这个复杂的多;
提前停止训练
对于模型训练过程,尤其是基于真实数据的训练过程,很多时候是无法完全收敛的,而我们需要保证训练一定可以结束而不是无限运行下去的,因此可以通过Early Stopping来控制其迭代在满足某些条件下提前结束;
增加Early Stopping
keras通过callback的方式添加Early Stopping,所谓callback指的是在每次epoch后运行的内容,用于判断是否应该终止训练过程:
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)
上述代码的含义是,如果连续20次迭代,每次的loss下降都不足0.001,那么训练终止,反正目前为止表现最好的权重数据;
例子 - 使用Early Stopping训练模型
还是之前的红酒例子,数据格式如下:
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.8 | 0.470 | 0.43 | 2.10 | 0.171 | 27.0 | 66.0 | 0.99820 | 3.17 | 0.76 | 10.8 | 6 |
| 8.1 | 0.820 | 0.00 | 4.10 | 0.095 | 5.0 | 14.0 | 0.99854 | 3.36 | 0.53 | 9.6 | 5 |
| 9.1 | 0.290 | 0.33 | 2.05 | 0.063 | 13.0 | 27.0 | 0.99516 | 3.26 | 0.84 | 11.7 | 7 |
| 10.2 | 0.645 | 0.36 | 1.80 | 0.053 | 5.0 | 14.0 | 0.99820 | 3.17 | 0.42 | 10.0 | 6 |
模型定义、指定loss和优化器、指定Early Stopping代码如下:
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=500,
callbacks=[early_stopping],
verbose=0, # turn off training log
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
print("Minimum validation loss: {}".format(history_df['val_loss'].min()))
以上,通过fit方法的callbacks参数将Early Stopping作为一个callback添加到了迭代过程中,用于控制训练的提前结束,运行图如下:
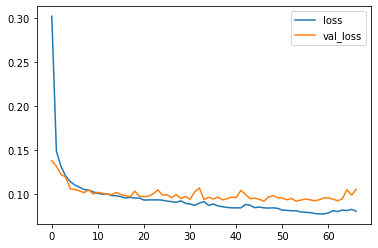
结合代码和上图可以看到,虽然我们设置了epoch为500,但是在迭代不到70次时就终止了,这就是Early Stopping在起作用,一定程度上可以避免不必要的训练过程,减少训练时间;
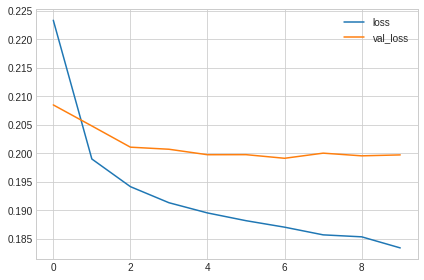
过拟合和欠拟合的练习
这部分练习可以通过这个notebook完成,这里有通过训练简单线性模型和复杂神经网络模型等,并通过学习曲线来观察模型的拟合情况,并通过添加Early Stopping来控制过拟合情况;
Dropout和Batch Normalization
实际的神经网络结构中往往包含更多的层,不仅仅是dense层,比如激活层、Dropout层等等,有些类似dense层,定义神经元的连接,而有些则是用于预处理和转换等;
Dropout
Dropout层有助于纠正过拟合问题,在每次训练迭代中,随机的去掉网络层中的一部分输入单元,使得模型难以从训练数据学习到错误的模式,取而代之的是模型会搜索更普遍适用的模式,也就是具有更好的鲁棒性的模式,借此解决过拟合问题;
可以把Dropout看作是一种集成方法,与随机森林类似,Dropout的随机抽取类似随机森林的行抽取和列抽取,二者的目的都是解决原始模型的过拟合问题,思路是一样的;
增加Dropout
在keras中,Drouput作为层使用,作用于其下的一层,通过参数rate指定随机取出的比例:
keras.Sequential([
# ...
layer.Dropout(rate=0.3), # apply 30% dropout to the next layer
layer.Dense(16),
# ...
])
Batch Normalization
模型在迭代过程中,权重的更新主要由loss和optimater决定,假设我们的输入特征的量纲不一致,比如有的特征范围从0到1,有的特征是从-100到+100,那么在优化器计算过程中就会产生差异很大的结果,并使得训练过程很不稳定,体现就是学习曲线的波动严重;
一个小栗子:比如我们要预测房价,目前有两个属性,一个是面积,范围是10到200,另一个是距离火车站距离,范围是100到100000,如果不进行量纲统一,可以遇见的是在计算过程中由于火车站距离值更大,因此会影响对结果的预测,或者说这个范围一定程度上参与了原来权重该起到的作用;
Batch Normalization类似SKLearn里的StandardScaler和MinMaxScaler的作用,用于将输入特征的量纲统一,避免因为量纲不同导致对于预测结果影响的权重差异;
增加Batch Normalization
可以用在某一层之后:
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),
也可以用在某一层和它的激活层之间:
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
例子 - 使用Dropout和Batch Normalization
继续红酒例子,在每一个隐含层后都先加一个Dropout过滤一部分输入解决过拟合,再应用Batch Normalization优化不稳定情况:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])
训练过程不使用Early Stopping:
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
学习曲线如下:
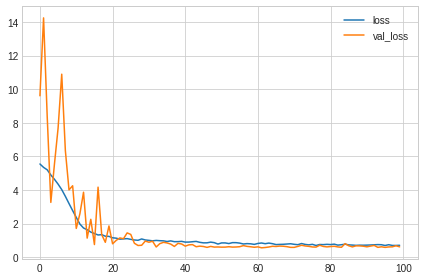
可以看到,首先虽然没有Early Stopping,但是过拟合问题不明显,其次在迭代20次之后不稳定的情况基本消失了,说明Dropout和Batch Normalization都起到了各自的作用;
Dropout和Batch Normalization练习
这部分练习在这个notebook里,其中分别使用两个数据集,对比其上应用Dropout与不应用,应用Batch Normalization与不应用在学习曲线上的差异,可以很直观的看到二者起到的作用;
下面是应用Batch Normalization后的学习曲线,要知道在不应用的情况下曲线都无法绘制出来:
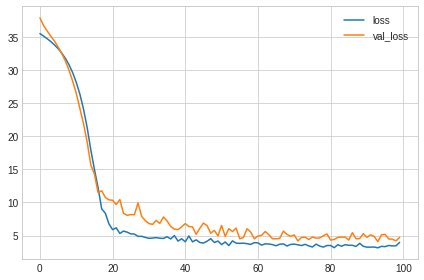
分类问题
之前处理的都是回归问题,处理分类问题的区别只有以下两点:
- 损失函数:分类与回归在损失函数应用上不同,比如MAE和准确率;
- 输出层输出类型:也就是网络结构最后一层输出的内容,之前都是数值,如果是二分类问题,则应该是0/1;
Sigmoid函数
Sigmoid函数同样作为激活函数,它可以将实数输出映射到0到1之间,也就是通常的概率范围,而不管是准确率还是交叉熵等都可以利用概率来计算得到;
Sigmoid函数图像如下,上一个使用它的地方是逻辑回归,同样是将线性回归的结果映射到0和1之间:

例子 - 二分类
数据格式如下:
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | ... | V26 | V27 | V28 | V29 | V30 | V31 | V32 | V33 | V34 | Class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0.99539 | -0.05889 | 0.85243 | 0.02306 | 0.83398 | -0.37708 | 1.00000 | 0.03760 | ... | -0.51171 | 0.41078 | -0.46168 | 0.21266 | -0.34090 | 0.42267 | -0.54487 | 0.18641 | -0.45300 | good |
| 1 | 0 | 1.00000 | -0.18829 | 0.93035 | -0.36156 | -0.10868 | -0.93597 | 1.00000 | -0.04549 | ... | -0.26569 | -0.20468 | -0.18401 | -0.19040 | -0.11593 | -0.16626 | -0.06288 | -0.13738 | -0.02447 | bad |
| 1 | 0 | 1.00000 | -0.03365 | 1.00000 | 0.00485 | 1.00000 | -0.12062 | 0.88965 | 0.01198 | ... | -0.40220 | 0.58984 | -0.22145 | 0.43100 | -0.17365 | 0.60436 | -0.24180 | 0.56045 | -0.38238 | good |
| 1 | 0 | 1.00000 | -0.45161 | 1.00000 | 1.00000 | 0.71216 | -1.00000 | 0.00000 | 0.00000 | ... | 0.90695 | 0.51613 | 1.00000 | 1.00000 | -0.20099 | 0.25682 | 1.00000 | -0.32382 | 1.00000 | bad |
| 1 | 0 | 1.00000 | -0.02401 | 0.94140 | 0.06531 | 0.92106 | -0.23255 | 0.77152 | -0.16399 | ... | -0.65158 | 0.13290 | -0.53206 | 0.02431 | -0.62197 | -0.05707 | -0.59573 | -0.04608 | -0.65697 | good |
像之前处理回归问题一样定义模型,区别在于最后一层的激活函数选择sigmoid用于输出概率:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[33]),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
添加交叉熵和准确率到模型中,继续使用adam,他在分类问题上表现依然很好:
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
使用Early Stopping控制训练过程:
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=1000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
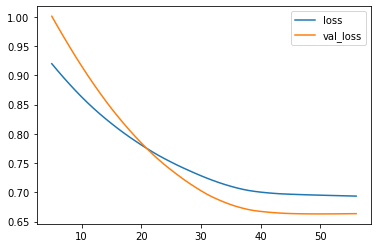
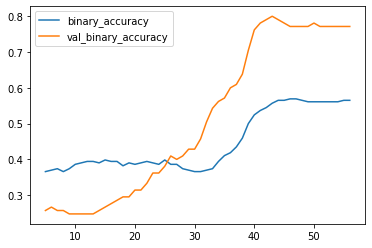
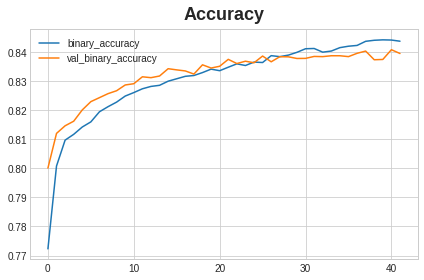
分别观察其交叉熵和准确率的变化情况:
history_df = pd.DataFrame(history.history)
# Start the plot at epoch 5
history_df.loc[5:, ['loss', 'val_loss']].plot()
history_df.loc[5:, ['binary_accuracy', 'val_binary_accuracy']].plot()
print(("Best Validation Loss: {:0.4f}" +
"
Best Validation Accuracy: {:0.4f}")
.format(history_df['val_loss'].min(),
history_df['val_binary_accuracy'].max()))
交叉熵:
准确率:
分类练习
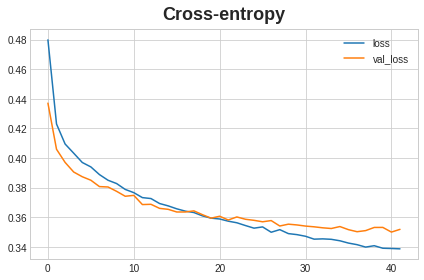
这部分练习在这个notebook,很完整的一个分类模型搭建过程,从基于结构图创建神经网络结构到添加loss和优化器,使用Early Stopping等都有,包括对于结果是否过拟合和欠拟合的讨论等,可以通过这个notebook再次练习下整个深度学习流程,麻雀虽小,五脏俱全;
交叉熵:
准确率:
最后
对于深度学习还有很多很多可以学习的内容,本篇文章以最简单的方式对其中各个基础模块进行介绍,并结合代码和运行结果图等进行说明,希望看完能够在脑海中形成对于深度学习的一个感性认识;
最后的最后
欢迎大佬们关注我的公众号:尼莫的AI小站,新开的公众号,后续会不定期更新有关机器学习、深度学习、数据处理分析、游戏的内容;
