一切都是对象
数据存储
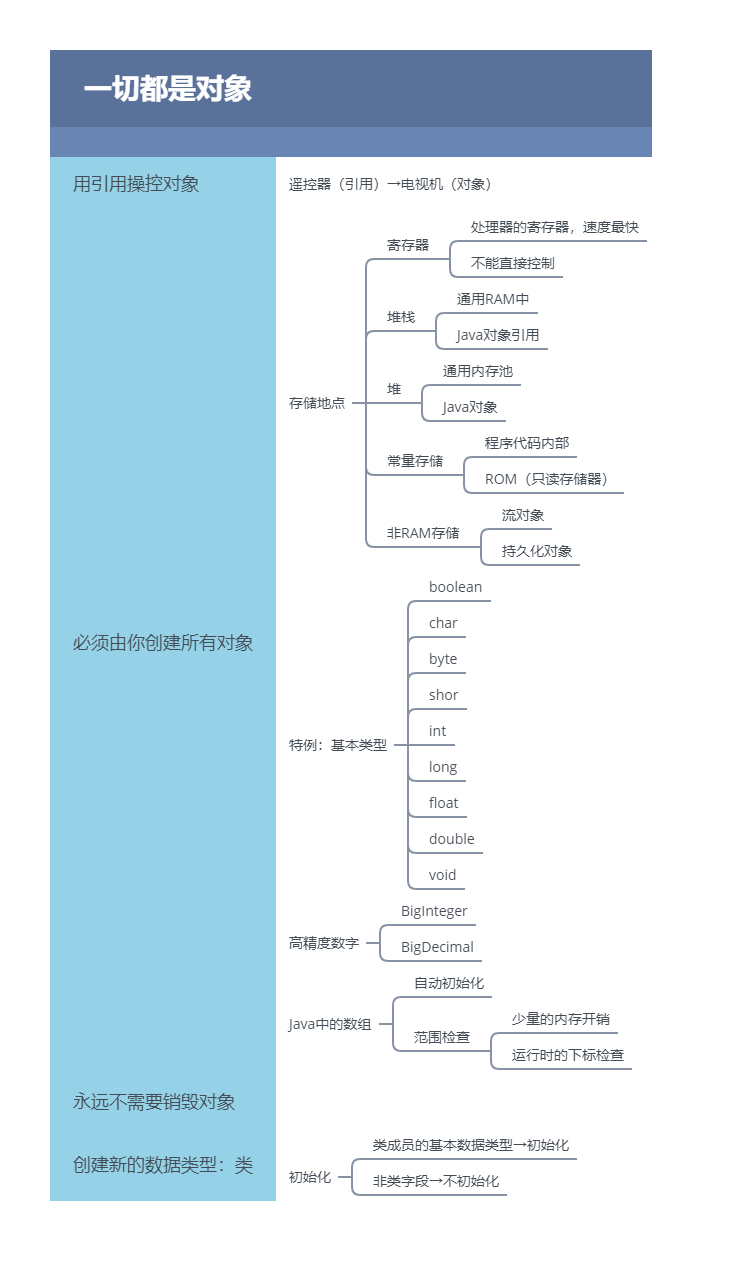
程序在运行时是如何存储的呢?尤其是内存是怎么分配的。有5个不同的地方可以存储数据:
-
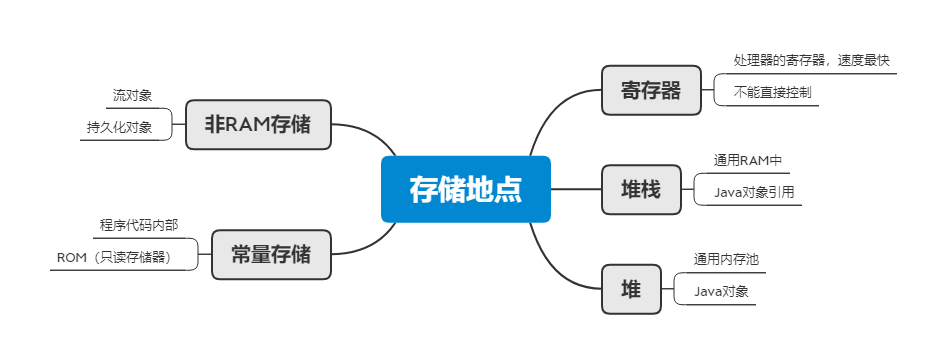
寄存器
这是最快的存储区,其位于处理器内部。但是数量极其有限。所以寄存器根据需求进行分配。我们对其没有直接的控制权,也无法在自己的程序里找到寄存器存在的踪迹(另一方面,C/C++ 允许开发者向编译器建议寄存器的分配)。
-
堆栈
位于RAM(随机访问存储器)中,通过堆栈指针可以从处理器那里获得直接支持。这也是一种快速有效的存储分配方法,仅次于寄存器。创建程序时,Java 系统必须知道栈内保存的所有项的生命周期。这种约束限制了程序的灵活性。因此,虽然在栈内存上存在一些 Java 数据(如对象引用),但 Java 对象本身的数据却是保存在堆内存的。
-
堆内存
一种通用的内存池(也在 RAM 区域),所有 Java 对象都存在于其中。编译器不需要知道对象必须在堆内存上停留多长时间,因此用堆内存保存数据更具灵活性。创建一个对象时,只需用
new命令实例化对象即可,当执行代码时,会自动在堆中进行内存分配。这种灵活性是有代价的:分配和清理堆内存要比栈内存需要更多的时间(如果可以用 Java 在栈内存上创建对象,就像在 C++ 中那样的话)。随着时间的推移,Java 的堆内存分配机制现在已经非常快,因此这不是一个值得关心的问题了。 -
常量存储
常量值通常直接放在程序代码中,因为它们永远不会改变。如需严格保护,可考虑将它们置于只读存储器 ROM (只读存储器,Read Only Memory)中。
-
非 RAM 存储
数据完全存在于程序之外,在程序未运行以及脱离程序控制后依然存在。两个主要的例子:
- 序列化对象:对象被转换为字节流,通常被发送到另一台机器;
- 持久化对象:对象被放置在磁盘上,即使程序终止,数据依然存在。
这些存储的方式都是将对象转存于另一个介质中,并在需要时恢复成常规的、基于 RAM 的对象。Java 为轻量级持久化提供了支持。而诸如 JDBC 和 Hibernate 这些类库为使用数据库存储和检索对象信息提供了更复杂的支持。
-
特例:基本类型存储
Java 的基本类型的创建并不是通过
new关键字来产生。通常new出来的对象都是保存在堆内存中的,以此方式创建小而简单的变量往往是不划算的。所以对于这些基本类型的创建方法,Java 使用了和 C/C++ 一样的策略。也就是说,不是使用new创建变量,而是使用一个“自动”变量。 这个变量直接存储"值",并置于栈内存中,因此更加高效。Java 确定了每种基本类型的内存占用大小。 这些大小不会像其他一些语言那样随着机器环境的变化而变化。
基本类型 大小 最小值 最大值 包装类型 boolean — — — Boolean char 16 bits Unicode 0 Unicode 216 -1 Character byte 8 bits (-128) (+127) Byte short 16 bits (-2^{15}) (+2^{15} -1) Short int 32 bits (-2^{31}) (+2^{31} -1) Integer long 64 bits (- 2^{63}) (+ 2^{63} -1) Long float 32 bits IEEE754 IEEE754 Float double 64 bits IEEE754 IEEE754 Double void — — — Void 基本类型有自己对应的包装类型,如果你希望在堆内存里表示基本类型的数据,就需要用到它们的包装类。代码示例:
char c = 'x'; Character ch = new Character(c);或者你也可以使用下面的形式:
Character ch = new Character('x');基本类型自动转换成包装类型(自动装箱)
Character ch = 'x';相对的,包装类型转化为基本类型(自动拆箱):
char c = ch; -
高精度数字
在 Java 中有两种类型的数据可用于高精度的计算。它们是
BigInteger和BigDecimal。尽管它们大致可以划归为“包装类型”,但是它们并没有对应的基本类型。这两个类包含的方法提供的操作,与对基本类型执行的操作相似。也就是说,能对 int 或 float 做的运算,在 BigInteger 和 BigDecimal 这里也同样可以,只不过必须要通过调用它们的方法来实现而非运算符。- BigInteger 支持任意精度的整数。可用于精确表示任意大小的整数值,同时在运算过程中不会丢失精度。
- BigDecimal 支持任意精度的定点数字。例如,可用它进行精确的货币计算。
-
数组存储
当我们创建对象数组时,实际上是创建了一个引用数组,并且每个引用的初始值都为 null 。在使用该数组之前,我们必须为每个引用指定一个对象 。如果我们尝试使用为 null 的引用,则会在运行时报错。因此,在 Java 中就防止了数组操作的常规错误。
我们还可创建基本类型的数组。编译器通过将该数组的内存全部置零来保证初始化。
对象的销毁
-
作用域
在 C、 C++ 和 Java 中,作用域是由大括号
{}的位置决定的。例如:{ int x = 12; // 仅 x 变量可用 { int q = 96; // x 和 q 变量皆可用 } // 仅 x 变量可用 // 变量 q 不在作用域内 }Java 的变量只有在其作用域内才可用。缩进使得 Java 代码更易于阅读。由于 Java 是一种自由格式的语言,额外的空格、制表符和回车并不会影响程序的执行结果。在 Java 中,你不能执行以下操作,即使这在 C 和 C++ 中是合法的:
{ int x = 12; { int x = 96; // 非法 } } -
对象的作用域
Java 对象与基本类型具有不同的生命周期。当我们使用
new关键字来创建 Java 对象时,它的生命周期将会超出作用域。{ String s = new String("a string"); } // 作用域终点上例中,引用 s 在作用域终点就结束了。但是,引用 s 指向的字符串对象依然还在占用内存。只要你需要,
new出来的对象就会一直存活下去。那么问题来了:我们在 Java 中并没有主动清理这些对象,那么它是如何避免 C++ 中出现的内存被填满从而阻塞程序的问题呢?
答案是:Java 的垃圾收集器会检查所有
new出来的对象并判断哪些不再可达,继而释放那些被占用的内存,供其他新的对象使用。也就是说,我们不必担心内存回收的问题了。你只需简单创建对象即可。当其不再被需要时,能自行被垃圾收集器释放。垃圾回收机制有效防止了因程序员忘记释放内存而造成的“内存泄漏”问题。
基本类型默认值
如果类的成员变量(字段)是基本类型,那么在类初始化时,这些类型将会被赋予一个初始值。
| 基本类型 | 初始值 |
|---|---|
| boolean | false |
| char | u0000 (null) |
| byte | (byte) 0 |
| short | (short) 0 |
| int | 0 |
| long | 0L |
| float | 0.0f |
| double | 0.0d |
这些默认值仅在 Java 初始化类的时候才会被赋予。这种方式确保了基本类型的字段始终能被初始化(在 C++ 中不会),从而减少了 bug 的来源。但是,这些初始值对于程序来说并不一定是合法或者正确的。 所以,为了安全,我们最好始终显式地初始化变量。
这种默认值的赋予并不适用于局部变量 —— 那些不属于类的字段的变量。 因此,若在方法中定义的基本类型数据,如下:
int x;
这里的变量 x 不会自动初始化为0,因而在使用变量 x 之前,程序员有责任主动地为其赋值(和 C 、C++ 一致)。如果我们忘记了这一步, Java 将会提示我们“编译时错误,该变量可能尚未被初始化”。 这一点做的比 C++ 更好,在后者中,编译器只是提示警告,而在 Java 中则直接报错。
命名可见性
如果你在两个模块中使用相同的命名,那么如何区分这两个名称,并防止两个名称发生“冲突”呢?在 C 语言编程中这是很具有挑战性的,因为程序通常是一个无法管理的名称海洋。C++ 将函数嵌套在类中,所以它们不会和嵌套在其他类中的函数名冲突。然而,C++ 还是允许全局数据和全局函数,因此仍有可能发生冲突。为了解决这个问题,C++ 使用附加的关键字引入了命名空间。
Java 采取了一种新的方法避免了以上这些问题:为一个类库生成一个明确的名称,Java 创建者希望我们反向使用自己的网络域名,因为域名通常是唯一的。因此我的域名是 MindviewInc.com,所以我将我的 foibles 类库命名为 com.mindviewinc.utility.foibles。反转域名后,. 用来代表子目录的划分。
static关键字
类是对象的外观及行为方式的描述。通常只有在使用 new 创建那个类的对象后,数据存储空间才被分配,对象的方法才能供外界调用。这种方式在两种情况下是不足的。
- 有时你只想为特定字段(注:也称为属性、域)分配一个共享存储空间,而不去考虑究竟要创建多少对象,甚至根本就不创建对象。
- 创建一个与此类的任何对象无关的方法。也就是说,即使没有创建对象,也能调用该方法。
编码规范
Java 编程语言编码规范(Code Conventions for the Java Programming Language)要求类名的首字母大写。 如果类名是由多个单词构成的,则每个单词的首字母都应大写(不采用下划线来分隔)例如:
class AllTheColorsOfTheRainbow {
// ...
}
有时称这种命名风格叫“驼峰命名法”。对于几乎所有其他方法,字段(成员变量)和对象引用名都采用驼峰命名的方式,但是它们的首字母不需要大写。代码示例:
class AllTheColorsOfTheRainbow {
int anIntegerRepresentingColors;
void changeTheHueOfTheColor(int newHue) {
// ...
}
// ...
}
其他可以参考阿里巴巴java手册