

1:集合:存储对象 遍历取出对象
List<要存储元素的数据类型> 变量名 = new ArrayList<要存储元素的数据类型>();
必须要引用数据类型,不能是基本类型,除非把基本数据类型变成包装类
b:集合
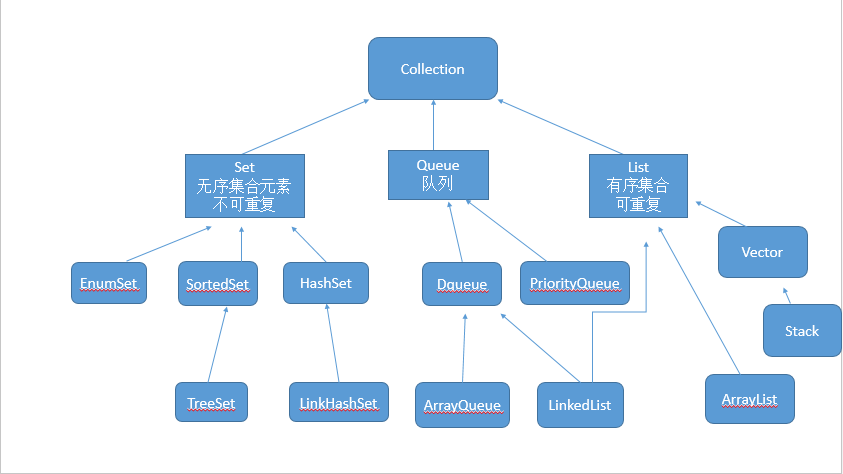
* b1:集合的层次结构
* Iterable <E> 实现了Iterable接口的集合类才可以被foreach
* Collection 接口 集合最顶层的接口
* List 接口特点: 有序 有索引 可以重复元素 元素存与取的顺序相同
泛型用来约束集合中可有存储的数据类型
* ArrayList 底层是数组 根据索引查询,增删慢 ArrayList是实现了基于动态数组的数据结构 寻址容易,插入和删除困难;
* LinkedList 底层是链表 增删快 查询慢 LinkedList是基于链表的数据结构 寻址困难,插入和删除容易。 子类特有的功能,不能多态调用
* Stack 栈结构的集合 stack继承vector其底层用的还是数组存储方式
Stack 栈结构的集合 官方建议:使用栈尽量使用ArrayDeque:
Deque 接口及其实现提供了 LIFO 堆栈操作的更完整和更一致的 set,应该优先使用此 set,而非此类。例如:
Deque stack = new ArrayDeque();
* Vector 线程安全的线性集合
**Vector集合数据存储的结构是数组结构,为JDK中最早提供的集合。Vector中提供了一个独特的取出方式,就是枚举Enumeration,它其实就是早期的迭代器。此接口Enumeration的功能与 Iterator 接口的功能是类似的。Vector集合已被ArrayList替代。枚举Enumeration已被迭代器Iterator替代。
2.0 HashSet集合存储数据的结构(哈希表)
什么是哈希表呢?
哈希表底层使用的也是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些对象给数组中存放时,那么会根据这些对象的特有数据结合相应的算法,计算出这个对象在数组中的位置,然后把这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表。
当向哈希表中存放元素时,需要根据元素的特有数据结合相应的算法,这个算法其实就是Object类中的hashCode方法。由于任何对象都是Object类的子类,所以任何对象有拥有这个方法。即就是在给哈希表中存放对象时,会调用对象的hashCode方法,算出对象在表中的存放位置,这里需要注意,如果两个对象hashCode方法算出结果一样,这样现象称为哈希冲突,这时会调用对象的equals方法,比较这两个对象是不是同一个对象,如果equals方法返回的是true,那么就不会把第二个对象存放在哈希表中,如果返回的是false,就会把这个值存放在哈希表中。
总结:保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
Set 无序不可重复 set集合可以存储多个对象,但并不会记住元素的存储顺序,也不允许集合中有重复元素(不同的set集合有不同的判断方法)。 元素存与取的顺序可能不同
*hashSet 底层是哈希表
*TreeSet TreeSet 底层实际使用的存储容器就是 TreeMap TreeMap 的实现就是红黑树数据结构
* eg:
* hashset底层是使用什么实现的?
* 底层数据结构是哈希表,哈希表就是存储唯一系列的表,而哈希值是由对象的hashCode()方法生成。
* hashset中元素是唯一的 为什么是唯一的?它是如何实现的?
* 确保唯一性的两个方法:hashCode()和equals()方法。
HashSet按照Hash算法存储集合中的元素,具有很好的存取和查找性能。当向HashSet中添加一些元素时,HashSet会根据该对象的HashCode()方法来得到该对象的HashCode值,然后根据这些HashCode的值来决定元素的位置。
TreeSet支持两种排序方法:自然排序和定制排序。在默认的情况下,TreeSet采用自然排序。
自然排序:TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后让集合按照升序排列,这种方式叫做自然排序。
定制排序:定制排序是按照使用者的要求,需要自己设计的一种排序。如果需要定制排序,比如需要数据按照降序排列,则可以通过Comparator接口的帮助。
PS:
1.如果希望TreeSet能够正常运行,TreeSet只能添加同一种类型的对象。
2.TreeSet集合中判断元素相等的唯一标准是:两个对象通过comparator(Object obj)方法比较后,返回0;否则认为不相等。
Map
* HashMap ---------丨 HashMap的遍历速度和他的容量有关。不自动同步
* Hashtable -------丨 都实现了Map接口,它继承自Dictionary类 Hashtable线程安全, HashMap线程不安全
* LinkedHashMap LinkedHashMap的遍历速度只和他的数据有关。 LinkedHashMap实现类使用链表来维护key-value的次序,可以记住键值对的插入顺序。
* TreeMap 实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序 TreeMap底层采用红黑树来管理key-value对
TreeMap存储key-value键值对时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。也有两种排序方式:
1) 自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则抛出ClassCastException异常。
2) 定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。不需要Map的key实现Comparable接口。
* hashmap底层是什么结构?如何保证key是唯一的?请解释
* 数组+链表(维护了一张 HashTable ) 每一个被添加的元素都有一个 hashCode(哈希值),他们先比较哈希值,是否相同?
* 不相同的元素,添加进入 HashTable. 如果hashCode相同的话, 再去比较 equals()方法,
* 如果也相同的话,JVM就认为数据已经存在了,就不会添加数据!
hashtable和hashmap的区别:
hashtable 有同步机制 不接受值为null的Key 或Value
hashmap 没有同步机制,需要使用者自己进行并发访问控制 接受值为null的Key 或Value
* b2:b1中提到的每种集合类的常用方法需要熟练使用
* b3:b1中提到的每种集合类的底层结构都需要清晰
* 可以从原理角度解释每种集合类的特点
例 1
在使用 List 集合时需要注意区分 indexOf() 方法和 lastIndexOf() 方法。前者是获得指定对象的最小索引位置,而后者是获得指定对象的最大索引位置。前提条件是指定的对象在 List 集合中有重复的对象,否则这两个方法获取的索引值相同。
下面的案例代码演示了 indexOf() 方法和 lastIndexOf() 方法的区别。
- public static void main(String[] args)
- {
- List list=new ArrayList();
- list.add("One");
- list.add("|");
- list.add("Two");
- list.add("|");
- list.add("Three");
- list.add("|");
- list.add("Four");
- System.out.println("list 集合中的元素数量:"+list.size());
- System.out.println("list 集合中的元素如下:");
- Iterator it=list.iterator();
- while(it.hasNext())
- {
- System.out.print(it.next()+"、");
- }
- System.out.println(" 在 list 集合中'丨'第一次出现的位置是:"+list.indexOf("|"));
- System.out.println("在 list 集合中'丨'最后一次出现的位置是:"+list.lastIndexOf("|"));
- }
上述代码创建一个 List 集合 list,然后添加了 7 个元素,由于索引从 0 开始,所以最后一个元素的索引为 6。输出结果如下:
list 集合中的元素数量:7 list 集合中的元素如下: One、|、Two、|、Three、|、Four、 在 list 集合中'|'第一次出现的位置是:1 在 list 集合中'|'最后一次出现的位置是:5
例 2
在仓库管理系统中要记录入库的商品名称,并且需要输出第一个录入的商品名称和最后—个商品名称。下面使用 LinkedList 集合来完成这些功能,实现代码如下:
- public static void main(String[] args)
- {
- LinkedList<String> products=new LinkedList<String>(); //创建集合对象
- String p1=new String("六角螺母");
- String p2=new String("10A 电缆线");
- String p3=new String("5M 卷尺");
- String p4=new String("4CM 原木方板");
- products.add(p1); //将 pi 对象添加到 LinkedList 集合中
- products.add(p2); //将 p2 对象添加到 LinkedList 集合中
- products.add(p3); //将 p3 对象添加到 LinkedList 集合中
- products.add(p4); //将 p4 对象添加到 LinkedList 集合中
- String p5=new String("标准文件夹小柜");
- products.addLast(p5); //向集合的末尾添加p5对象
- System.out.print("*************** 商品信息 ***************");
- System.out.println(" 目前商品有:");
- for(int i=0;i<products.size();i++)
- {
- System.out.print(products.get(i)+" ");
- }
- System.out.println(" 第一个商品的名称为:"+products.getFirst());
- System.out.println("最后一个商品的名称为:"+products.getLast());
- products.removeLast(); //删除最后一个元素
- System.out.println("删除最后的元素,目前商品有:");
- for(int i=0;i<products.size();i++)
- {
- System.out.print(products.get(i)+" ");
- }
- }
如上述代码,首先创建了 5 个 String 对象,分别为 p1、p2、p3、p4 和 p5。同时将 pl、 p2、p3 和 p4 对象使用 add() 方法添加到 LinkedList 集合中,使用 addLast() 方法将 p5 对象添加到 LinkedList 集合中。分别调用 LinkedList 类中的 getFirst() 方法和 getLast()方法获取第一个和最后一个商品名称。最后使用 removeLast() 方法将最后一个商品信息删除,并将剩余商品信息打印出来。
LinkedList<String> 中的 <String> 是 Java 中的泛型,用于指定集合中元素的数据类型,例如这里指定元素类型为 String,则该集合中不能添加非 String 类型的元素。
运行程序,执行结果如下:
*************** 商品信息 *************** 目前商品有: 六角螺母 10A 电缆线 5M 卷尺 4CM 原木方板 标准文件夹小柜 第一个商品的名称为:六角螺母 最后一个商品的名称为:标准文件夹小柜 删除最后的元素,目前商品有: 六角螺母 10A 电缆线 5M 卷尺 4CM 原木方板