简介
推荐系统产生推荐列表的方式通常有两种:协同过滤以及基于内容推荐,或者基于个性化推荐。协同过滤方法根据用户历史行为(例如其购买的、选择的、评价过的物品等)结合其他用户的相似决策建立模型。这种模型可用于预测用户对哪些物品可能感兴趣(或用户对物品的感兴趣程度)。基于内容推荐利用一些列有关物品的离散特征,推荐出具有类似性质的相似物品。而本文使用协同过滤的方法来构建整个推荐系统。
推荐方式
-
根据流行程度
**优点**:能够给使用者推荐一些东西,了解到最新流行动向。 **缺点**:没有代表性,因为这仅仅是该平台的数据集合。推荐的并不符合个性化的需求。 -
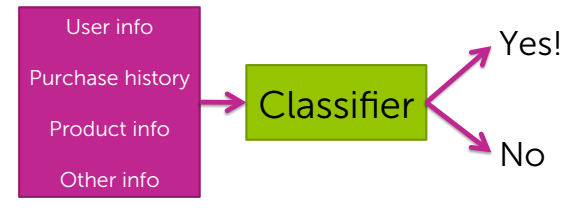
根据个人特征
通过用户信息和商品特征给出推荐。但这往往也有很多问题:用户信息不完善,商品信息不全,给分类的方式带来很大不确定性。
-
根据协同过滤
这也是今天的主角。首先说说什么是协同过滤:**通过其他人的个人特征,商品的特征,用户和商品的一般化关联关系给用户推荐相应的产品。**举个例子:比如你买了一个手机,那么该平台看看和你相似买了手机的用户都会买哪些东西,然后给你进行推荐。
实现步骤
step 1:
需要根据用户购买的东西和商品对应建一个矩阵:(列为商品,横为用户)
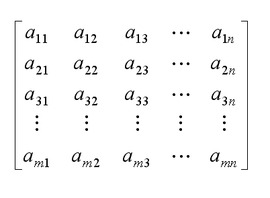
问题:一个人可能会购买多件商品这样会产生计算误差。
这时需要对矩阵进行规范化处理(将数据按比例缩放,使之落入一个小的特定区间),引入Jaccard相似性系数:
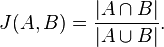
step 2:
将购物历史加入其中,进行权重的计算。假如一名用户买了牛奶和尿布,那么他买湿巾的可能:

最后将加权平均分排序后,即可按排序进行推荐。
step 3:
现象:对一些产品来说,用户可能喜欢,但是他用购买记录没办法得到推荐。
解决方案: 首先拿已经评价过的商品和用户对应构成如下矩阵(列为商品,横为用户),黑块是已经进行评价的,而白块是评价过的,那么将白块变成黑块便是我们下面要做的。

为了计算白块,我们为商品和用户建立向量。而向量里有一系列关于商品和用户特征取值。如一用户喜欢计算机那么他的计算机属性值就较高。而每个商品也具有计算机的属性值并赋值。
Lu = [ 0.3 0.6 1.6 ... ] --用户取值
Ru = [ 0.6 0.8 4.2 ... ] --商品取值
再对Lu和Ru取点乘,便能取得用户和商品的相关性。以这样的思路我们便能建立起矩阵因子分解模型(L为用户集合,R为商品的集合,集合的每项便为特征取值):
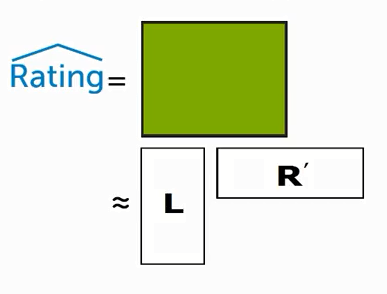
通过得到模型与商品评价矩阵Rating进行残差平方和来判断模型的好坏。这种预测也仅仅是数据层面上的,下面介绍具体判断模型好坏的参数:召回率和精准度。
用户喜欢的商品并且被展示出来的商品 / 喜欢的商品

用户喜欢的商品并且被展示出来的商品 / 被展示出来的商品

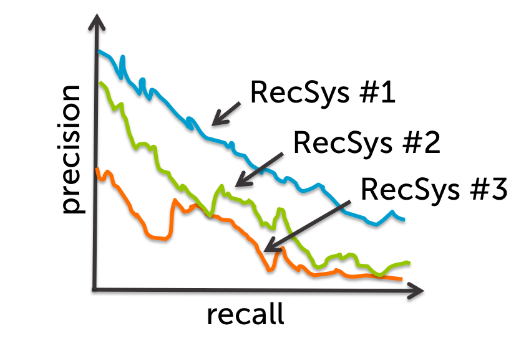
不同模型得到的不同函数