1.高级建表和插入
使用creat 和select 进行建表操作,中间采用AS 标识符;
CREATE TABLE new_table AS SELECT * FROM exist_table LIMIT 10;
从一个表中复制列插入到指定的表中:
INSERT INTO table2
SELECT * FROM table1;
2.select 子查询
子查询就是一个select 语句作为另一个查询语句的输入值,主要分为以下三种情况:
- 出现在where 语句处 的子查询语句,作用是作为过滤的条件来使用;
Select 列名 From 表名 Where 列 操作符 (Select 列名 From 表名)
******使用注意:
(1)子查询语句必须针对一个字段进行查询操作,否则抛错:Operand should contain 1 column(s - 出现在from 语句处的子查询语句,作用是作为一个临时的表进行查询;
Select 字段 from (select * from 表名)as 别名
*********此处的使用注意:
(1)子查询在from 语句之后,其实就是生成了一个临时表,所以子查询可以查询多个字段;
(2)子查询 在from 之后的时候,必须要对表取一个别名进行使用 - 出现在Select list 语句处的子查询语句,作用是作为一个字段值进行返回;
select 字段1,(select 字段2 from 表名) from 表名
***********此处的使用注意:
(1)子查询语句必须针对一个字段进行查询操作,否则抛错:Operand should contain 1 column(s)
(2)子查询语句返回的必须是一行数据,否则抛错:Subquery returns more than 1 row
3.多表操作
- 行合并操作
格式: select * from 表A union (union All) select * from 表B; ******使用注意: (1)操作合并的两个表,必须是字段或者列数相同; (2)union 对表做合并操作的时候,会进行去重操作; (3)union all 对表做合并操作的时候,不会进行去重操作; (4)使用合并操作的时候,不能进行order by操作,如果需要进行排序操作,可以在合并表结束后,使用子查询的方式,进行order by 操作;
4.行结合 Join :
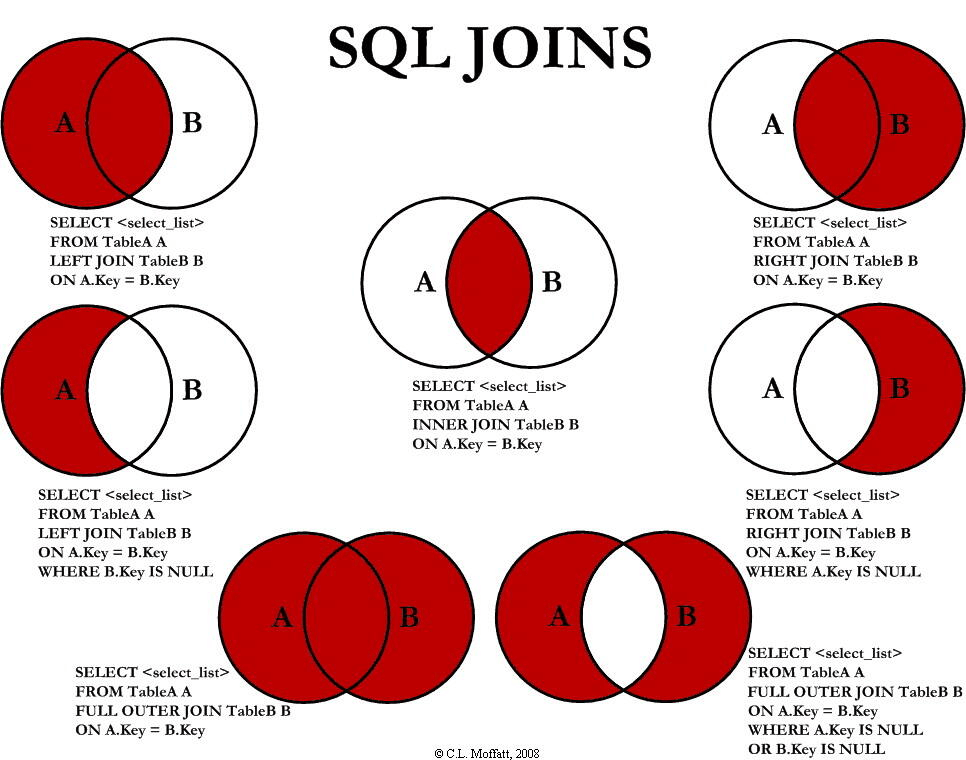
SQL 的join 子句基于多个表之间的相同字段,进行表之间的行结合操作,主要分为Left Join,Right Join ,Inner Join ,Full Outer Join四种,以下为这四种操作描述:
- INNER JOIN:Join 操作的默认操作(使用Join 即可表示Inner Join ),如果关键字在表中存在一个匹配的时候,则返回行;
- LEFT JOIN:左表返回所有行,右表进行匹配,如果有匹配值,则返回对应的字段值,如果没有匹配值,则全部置为Null 值;
- RIGHT JOIN:与Left Join 操作相反,右表返回所有行,左表进行匹配,如果有匹配值,则返回对应的字段值,如果没有匹配值,则全部置为Null 值;
- FULL Outer JOIN:关键字只要左表和右表其中一个表中存在匹配,则返回行,它结合了 LEFT JOIN 和 RIGHT JOIN 的结果;
注意事项:
1)多表关联的核心原理在于笛卡尔积,参考文章(https://www.cnblogs.com/nick-huang/p/4919178.html#my_inner_label1); 2)多表关联可能会导致数据的重复,也就是在建立关联时的 1:1,1:N,N:N 的形式,所以需要注意数据的去重工作,要先处理每个表的数据,再进行关联操作;
5.MySql 变量
- 变量的使用场景:
1)代码中很多地方都会重复用到同一段代码; 2)每次重新使用代码的时候,可能只需要修改某些参数即可;例如:时间,区域 3)构建一个标识字段,帮助做数据分析判别。例如:对某类型字段进行排序分析;
- 变量的定义规则:
1)变量声明: 使用@变量名; 2)变量命名组成元素可以是:字母、数字、下划线、‘.’ 、'$'几种元素; 3)变量的赋值: 使用: set @变量名 =value; 使用: set @变量名 :=value; 使用: select 方式赋值:select @变量名:=value;(注意:该种方式声明变量只能使用‘:=’进行,因为在select 语句中 ‘=’会被认为是比较操作符) 4)变量的使用:直接调用变量名即可; **********注意: 变量的声明属于会话级别,所以变量在SQL 定义完成并执行后才会有,变量无法指定变量的类型,是在赋值的时候自动推断变量的类型;