框架结构
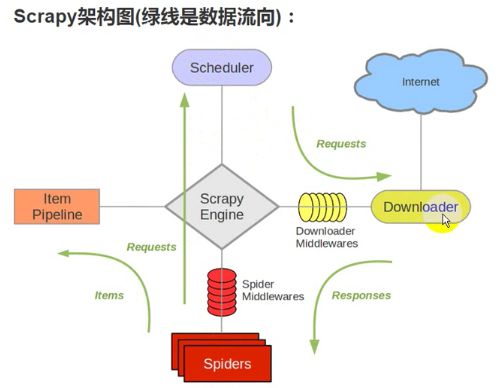
引擎:处于中央位置协调工作的模块
spiders:生成需求url直接处理响应的单元
调度器:生成url队列(包括去重等)
下载器:直接和互联网打交道的单元
管道:持久化存储的单元


框架安装
一般都会推荐pip,但实际上我是用pip就是没安装成功,推荐anaconda,使用conda install scarpy来安装。
scarpy需要使用命令行,由于我是使用win,所以还需要把scarpy添加到path中,下载好的scarpy放在anaconda的包目录下,找到并添加。
框架入门

创建项目
在开始爬取之前,您必须创建一个新的Scrapy项目。 进入您打算存储代码的目录中,运行下列命令:
scrapy startproject tutorial
该命令将会创建包含下列内容的 tutorial 目录,这个目录会创建在当前cmd的工作目录下:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件分别是:
scrapy.cfg: 项目的配置文件tutorial/: 该项目的python模块。之后您将在此加入代码。tutorial/items.py: 项目中的item文件.tutorial/pipelines.py: 项目中的pipelines文件.tutorial/settings.py: 项目的设置文件.tutorial/spiders/: 放置spider代码的目录.
实际上这算也是一个项目,可以使用pycharm加载。
编写爬虫
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
-
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。 -
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取 -
parse()是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。 -
allowed_domains:域范围,非此域内url不予爬取。
spider文件要保存在Spider目录下,文件名和类名都可以随便取,但是name属性是唯一的,调用时用的也是name属性。
import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response.body)
开始爬取
scrapy crawl dmoz
输出类似下面:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [dmoz] INFO: Spider opened
2014-01-23 18:13:08-0400 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-01-23 18:13:09-0400 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-01-23 18:13:09-0400 [dmoz] INFO: Closing spider (finished)
查看包含 [dmoz] 的输出,可以看到输出的log中包含定义在 start_urls 的初始URL,并且与spider中是一一对应的。在log中可以看到其没有指向其他页面( (referer:None) )。
回顾一下过程
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。