添加记录节点 -> 汇总记录节点 -> run汇总节点 -> [书写器生成]书写入文件 [-> 刷新缓冲区]
可视化关键点:
注意,
1.with tf.name_scope('str'):上下文环境,每一个name_scope内的张量被统一到一个可展开的节点中,且可以嵌套,而带'name'属性的张量会成为可视化图中最小的节点。
2.超参数是张量,使用tf.summary.histogram(layer_name + '/biases', biases)记录,在网页的HISTOGRAM中查询
3.loss值是scalar标量,使用tf.summary.scalar('loss',loss)记录,在网页的SCALAR中查询
4.和Variable一样,记录值需要:
1.merge = tf.summary.merge_all()统计整合
2.sess.run(merge,feed_dict={xs:x_data,ys:y_data})去run出值来
3.writer = tf.summary.FileWriter('./logs',sess.graph):启动可视化进程,指定日志文件存放位置。
4.记录值还需要writer.add_summary(result,i)去添加到书写器中输出到文件
流程总结:
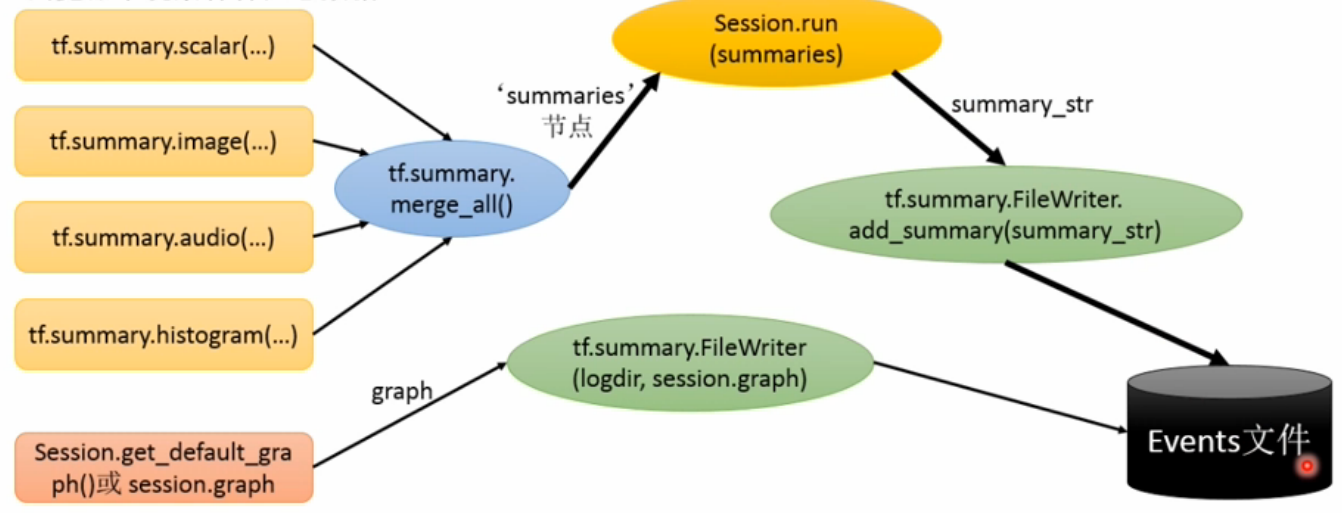
标记函数介绍:

合并函数介绍:

缓存机制介绍:
1.异步提升效率;2.add函数只压进缓冲区,由writer对象自行选择写入时机(有队列控制);3.可以flush强行立即写入。

补充说明:
