相关论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
概论
用于人脸检测和对齐。
本文提出的unified cascaded CNNs by multi-task learning,包含三个阶段:
1) 利用一个浅层的CNN快速产生候选窗口
2) 利用一个更复杂的CNN排除掉大量非人脸窗口
3) 利用一个更强大的CNN进一步改善结果,并输出人脸关键点位置。
本文的贡献:
1) 提出一个新的基于CNN的级联型框架,用于联和(joint)人脸检测和对齐;还设计轻量级的CNN架构使得速度上可以达到实时。
2) 提出一个有效的online hard sample mining方法来提高表现能力
3) 在人脸检测和人脸对齐上提高了不少精度
II. APPROACH
A. Overall Framework
整体框架如下图:
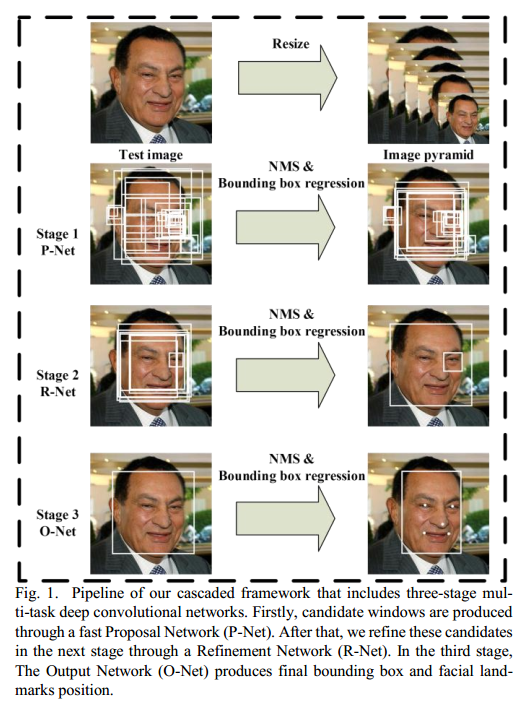
详细流程如下:
给定一张图片,首先将该图片重新调整到不同尺度大小,得到一个图像金字塔,该图像金字塔就是后面三阶段级联结构的输入。
阶段1:利用一个全卷积网络,称为Proposal Network (P-Net),来获得候选窗口和它们的bounding box regression vectors,然后利用bounding box regression vectors来调整候选框。之后,利用非极大值抑制(non-maximum suppression , NMS)来合并那些高度重合的候选框。
阶段2:第1阶段产生的所有候选框作为另一个CNN的输出,该CNN称为Refine
Network (R-Net)。该阶段的作用是利用bounding box regression和NMS进一步排除掉大量错误的候选框。
阶段3:与第2阶段类似,但这个阶段会输出5个人脸关键点位置。
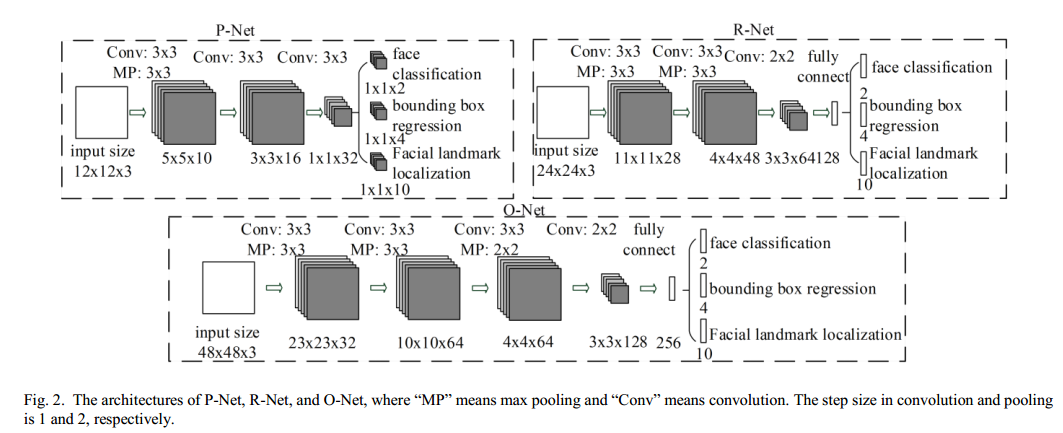
B. CNN Architectures
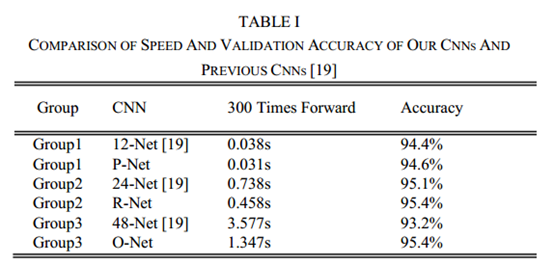
针对文献【19】,主要是减少卷积核的数量和将5x5卷积核变成3x3卷积核来减少计算量,增加深度来获得更好的性能。与文献【19】对比如下:
本文三个阶段的网络结构如下:
C. Training
利用三个任务来训练CNN检测器:人脸/非人脸 分类 ,bounding box regression 和人脸关键点定位(facial landmark localization)
1) 人脸分类器。这是一个二分类问题,对于每个样本xi,我们使用交叉熵损失:
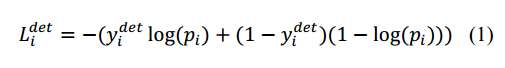
其中,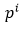 表示网络预测该样本是人脸的概率,
表示网络预测该样本是人脸的概率,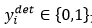 是ground-truth label。
是ground-truth label。
2) 边界框回归(Bounding box regression)。对于每个候选窗口,我们预测该候选窗口与其最近的ground truth(the bounding boxes’ left top, height, and width)的偏移。这是一个回归问题,对每个样本xi,使用欧式损失(Euclidean loss):
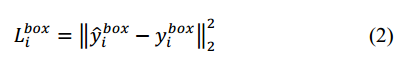
其中,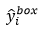 表示从网络中获得目标的坐标,
表示从网络中获得目标的坐标,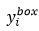 表示ground-truth坐标。有4个坐标,包括左上角x,y坐标,高度和宽度,因此
表示ground-truth坐标。有4个坐标,包括左上角x,y坐标,高度和宽度,因此
3) Facial landmark localization。与Bounding box regression相似,损失函数如下:
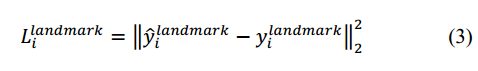
其中,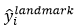 是网络预测的人脸关键点的坐标,
是网络预测的人脸关键点的坐标,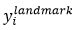 是ground-truth坐标。有5个人脸关键点,包括左眼,右眼,鼻子,嘴边左边角,嘴巴右边角,因此
是ground-truth坐标。有5个人脸关键点,包括左眼,右眼,鼻子,嘴边左边角,嘴巴右边角,因此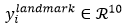
4) Multi-source training。由于在每个CNN网络中,我们使用了不同的任务,因此,在学习阶段有不同种类的训练图像,比如人脸,非人脸,部分对齐的人脸。在这种情况下,一些损失函数(公式1-3)用不到。比如说,对于背景区域图片,我们只计算,另外两个loss都设为0。整体的学习目标如下:
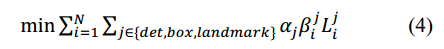
其中,N表示训练样本的数量,表示任务的重要性。在P-Net和R-Net中,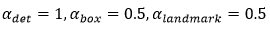 ;在O-Net中,
;在O-Net中,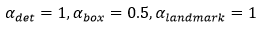 。
。 is the sample type indicator,比如说,对于背景样本,我们只计算
is the sample type indicator,比如说,对于背景样本,我们只计算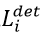 ,另外两个loss都设为0,即此时
,另外两个loss都设为0,即此时 。
。
在这种情况下,使用SGD来训练网络。
5) Online Hard sample mining。与传统的hard sample mining after original classifier had been trained不同,我们在人脸分类中采用在线的hard sample mining来自适应训练。
在每个mini-batch中,我们从所有样本的前向传播中将计算得到的loss排序,然后只取其中loss最高的前70%作为hard samples。然后在反向传播(BP)中只计算这些hard samples,忽略那些简单的样本。
III. EXPERIMENTS
A. Training Data
由于我们共同完成人脸检测和对齐,因此我们在训练阶段使用4中不同类型的数据标注。1)Negatives:与任何ground-truth人脸的IoU(Intersection-over-Union)小于0.3;2)Positives:与ground-truth人脸的IoU大于0.65;3)Part faces:IoU在0.4和0.65之间;4)Landmark faces:标注了5个人脸关键点位置的人脸。
Negatives和positives用于人脸的分类任务,positives和part faces用于bounding box regression,landmark faces用于facial landmark localization。每个网络的训练数据如下:
1)P-Net。从WIDER FACE [24]数据集中随机裁剪出若干的patch来产生positives, negatives and part face。从CelebA [23]数据集中裁剪人脸作为landmark faces。
2)R-Net。使用第一阶段过滤后的图像。
3)O-Net。使用前两个阶段过滤后的图像。
B. The effectiveness of online hard sample mining
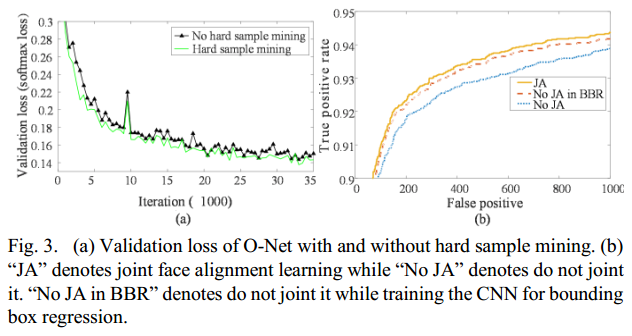
使用两个O-Net(一个有online hard sample mining,另一个没有)来评估online hard sample mining的有效性。这里只实验了分类任务。两个网络的初始化参数是一样的,学习率固定。两个网络的Loss如Fig3:
C. The effectiveness of joint detection and alignment
为了评估 联合人脸分类与对齐 的有效性,我们评估了两个不同的O-Net(一个联合了人脸对齐,另一个没有),(两个网络P-Net和R-Net是一样的)。我们也比较了bounding box regression在这两个O-Net中的表现能力。结果如Fig3所示。
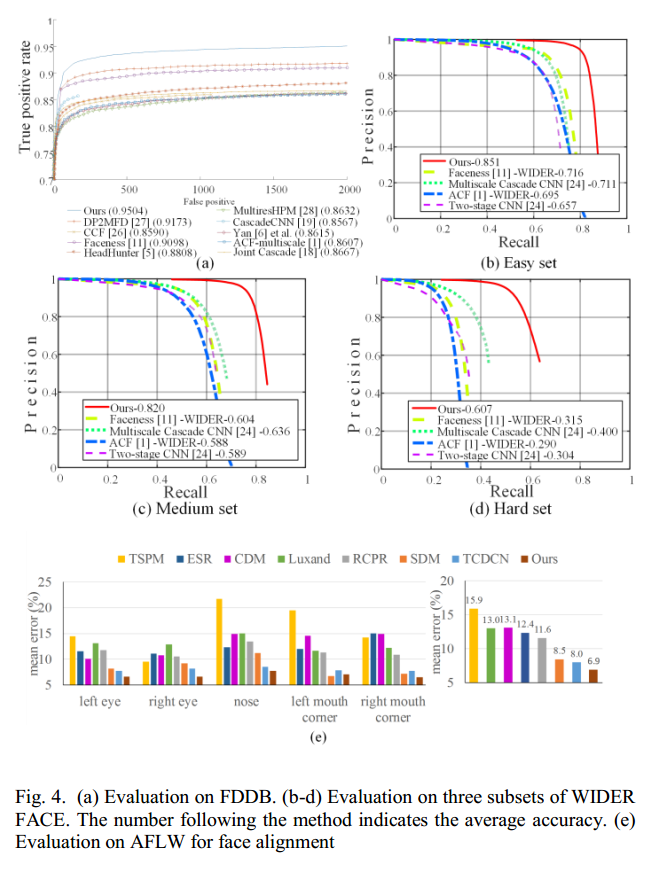
与其他模型的比较:
运行速度
16fps,2.60GHz CPU
99fps,GPU (Nvidia Titan Black)
注:文献19是:H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neural
network cascade for face detection,” in IEEE Conference on Computer
Vision and Pattern Recognition, 2015, pp. 5325-5334.