本文采用的GoogLenet网络(代号Inception)在2014年ImageNet大规模视觉识别挑战赛取得了最好的结果,该网络总共22层。
Motivation and High Level Considerations
提升深度神经网络的一个最直接的方法就是增加网络的大小。这包括增加网络的深度(网络的层数)和宽度(每一层神经元的个数)。这种简单粗暴的方法有两个缺点:1)更大网络意味着更多数量的参数,这非常容易导致过拟合。2)更大的网络意味着要使用更多的计算资源。
解决这两个问题的一个基本的方式就是引入稀疏性,即将全连接层替换为稀疏连接(卷积层其实就是一个稀疏连接)(减少参数,降低过拟合风险)。而非均匀稀疏网络的弊端是计算效率不高,可以采用将多个稀疏矩阵合并成 相关的稠密子矩阵的方法来解决(即减少计算资源使用)。
Architectural Details
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
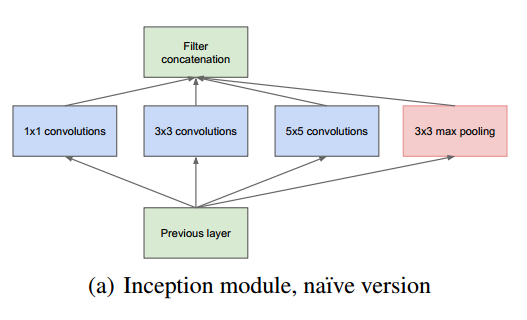
对上图做以下说明:
- 采用不同大小的卷积核意味着不同大小的感受野(尺寸不同的卷积核可以提取不同尺寸的特征,单层的特征提取能力增强了),最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
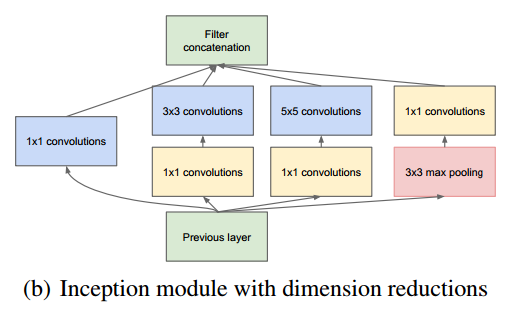
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴Network in Network,采用1x1卷积核来进行降维。在Filter concatenation层将1×1/3×3/5×5的卷积结果连接起来。如此设计的好处在于防止了层数增多带来的计算资源的爆炸性需求。从而使网络的宽度和深度均可扩大。使用了Inception层的结构可以有2-3×的加速。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:
Training Methodology
训练采用随机梯度下降(SGD),momentum为0.9,固定学习率每个8 epochs减小4%。训练策略一直在变化,参考文章Some improvements on deep convolutional neural network based image classification。
在测试中使用提升准确率的技巧
集成方法:训练了7个相同结构的GoogLeNet模型,初始化方法,学习率调整策略相同,图像采用(patch)以及随机输入的顺序不相同。
aggressive cropping方法:ILSVRC中使用的很多图是矩形,非正方形。将图像resize成4种scales,使得最短的边分别为256,288,320和352,然后从左、中、右分别截取方形square图像(如果是肖像图像,则分为上、中、下),然后对于每个square图像从4个角及中心截取224x224 square images,并把原square图像resize成224x224,在对上面5种做镜像变换。所以这样一幅图像可以得到4x3x6x2=144个crops。参考:Imagenet classification with deep convolutional neural networks
multiple crops的softmax概率取平均效果最好。
注:
(1)本文的主要想法其实是想通过构建密集的块结构来近似最优的稀疏结构,从而达到提高性能而又不大量增加计算量的目的。GoogleNet的caffemodel大小约50M,但性能却很优异。
(2)1X1卷积核作用:
1. 实现跨通道的交互和信息整合
2. 进行卷积核通道数的降维和升维
http://www.caffecn.cn/?/question/136
(3)Network-in-Network是Lin等人[12]为了增加神经网络表现能力而提出的一种方法。在他们的模型中,网络中添加了额外的1 × 1卷积层,增加了网络的深度。我们的架构中大量的使用了这个方法。但是,在我们的设置中,1 × 1卷积有两个目的:最关键的是,它们主要是用来作为降维模块来移除卷积瓶颈,否则将会限制我们网络的大小。这不仅允许了深度的增加,而且允许我们网络的宽度增加但没有明显的性能损失。
参考文献:
http://blog.csdn.net/Quincuntial/article/details/76457409?locationNum=7&fps=1
http://www.cnblogs.com/Allen-rg/p/5833919.html
http://www.cnblogs.com/neuface/archive/2016/03/11/5265740.html
附录:GoogLeNet网络结构:
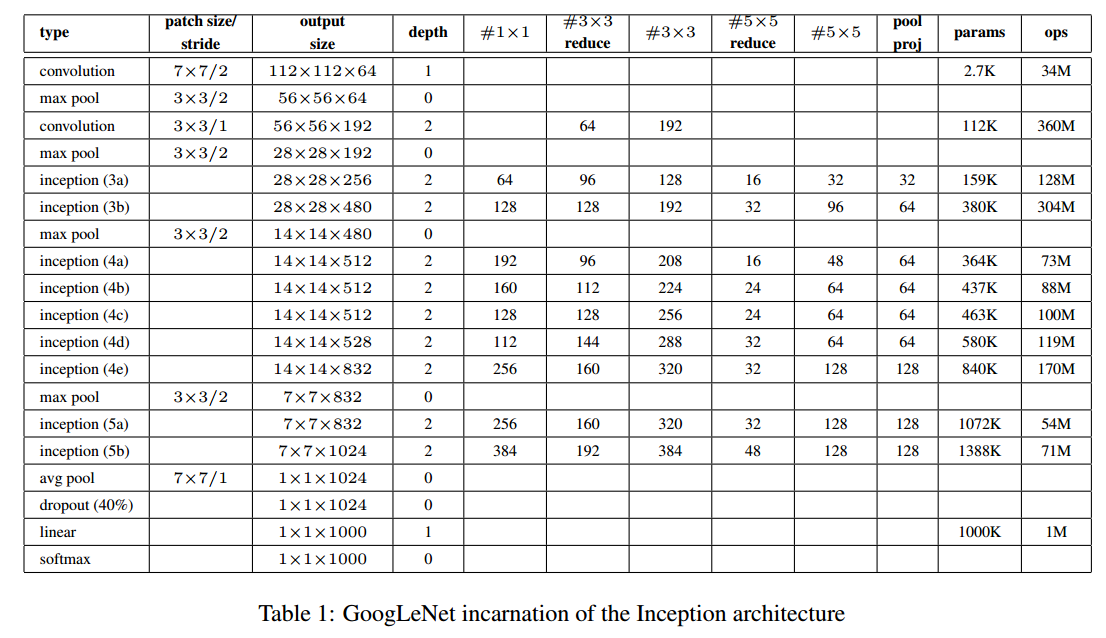
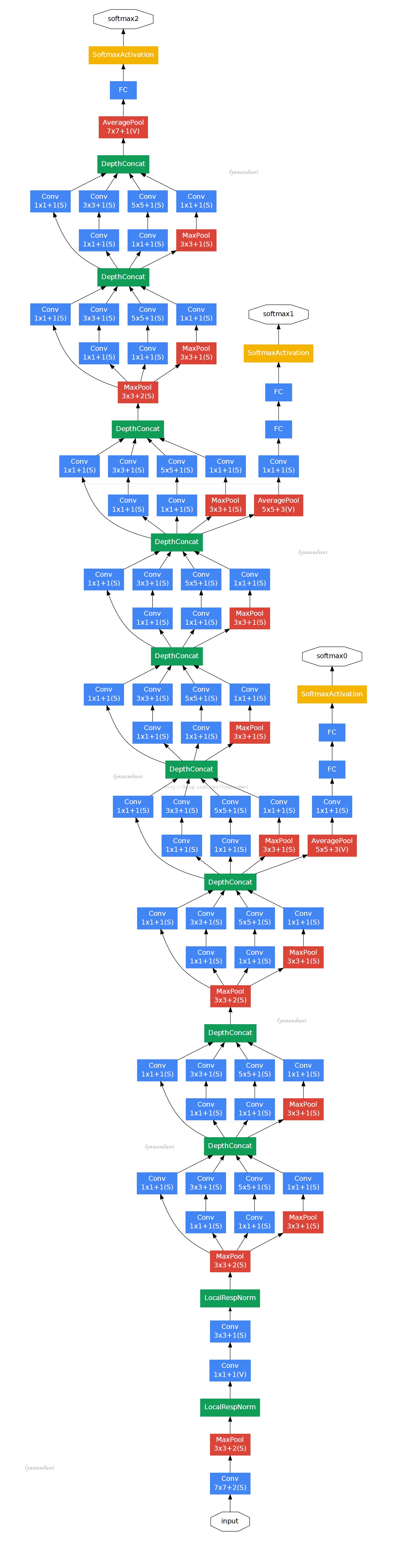
图片出处见水印