cartographer 代码解读
编程基础
读懂 cartographer 代码所需编码知识主要包含一下内容:
-
C++ 基础知识 (必要程度:9.9)
C++ 是嵌入式平台开发的主要语言,读懂cartographer代码需要一定的C++基础知识,同时,解读牛人代码也是提升编程能力必要手段。
参考链接:(需要掌握该链接中,至少95%内容)
-
google 相关库
-
Google Abseil (必要程度:6.0)
Abseil 提供了 C ++ 标准中缺失的部分; 此外,Abseil 还提供了一些特殊需求标准的替代方案。cartographer代码中用到的库函数与C++中标准库函数很像,仅仅为解读代码,该部分不需要太深入了解。
-
Google gflags、gtest、glog、gmock (必要程度:7.0)
参考链接:
https://www.cnblogs.com/heimazaifei/p/12176771.html
https://www.cnblogs.com/heimazaifei/p/12176749.html
-
-
C++ 高级用法 (必要程度:8.0)
如果能掌握以上内容,解析cartographer代码肯定没问题,上文没提到的不常用语法功能,程序中基本都加入了注释。但是,也许没有这么多时间系统学习C++相关知识,可以参考C++ 手册,一边看,一边学,当然这样可能会慢点。
参考资料:(nice)
C++ 网络版手册 https://zh.cppreference.com/w/cpp
流程图:
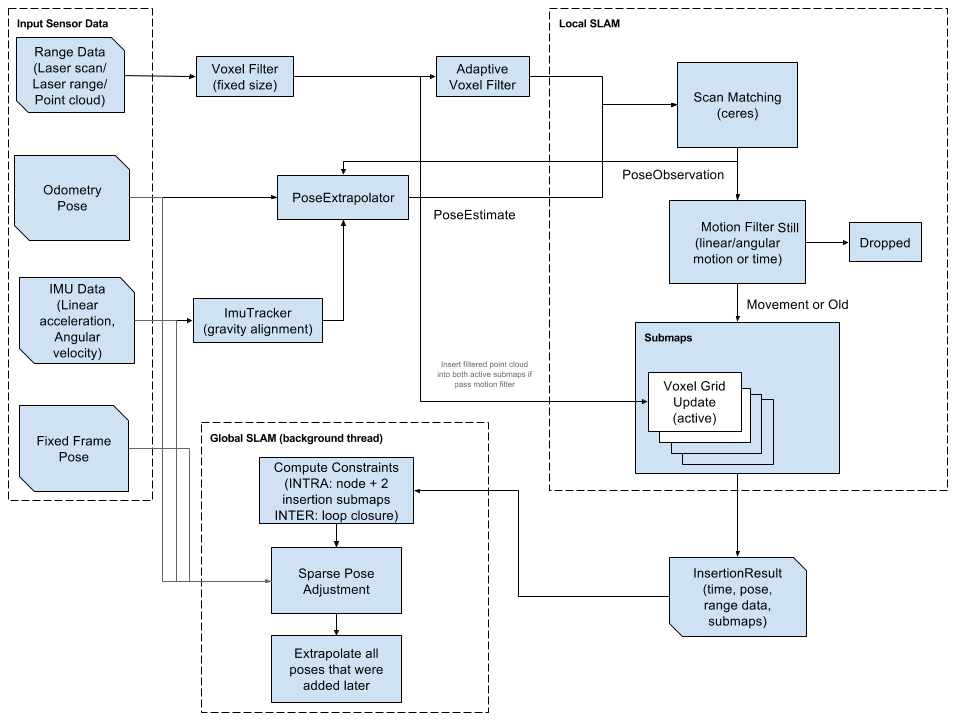
一些概念:Submaps,可以理解为:地图是一片一片拼接逐渐形成的,一片地图便是一个submap。
激光数据(range data)经过体素滤波(Voxel Filter)和自适应滤波与当前子地图(submap)匹配。该匹配过程需要里程计(Odometry Pose)提供初始位置(PoseEstimate)。初始位置的确定可以单独采用里程计,也可以采用里程计和陀螺仪(IMU,如果没有IMU,仅仅采用里程计即可)融合的方式。如果里程计也没有呢?可以采用激光与地图直接匹配(算法相对复杂些)。(插入时,同时插入两个活跃的submaps。每个时刻两个submap是活跃的,当前submap和上一个submap)。
激光匹配后,准备插入submap,但并非所有匹配后的激光都要插入submap,只有运动一段时间或举例后才进行匹配后的激光插入,所以需要一个运动过滤器(Motion Filter),不符合运动过滤器的会被丢弃(Dropped)。
以上过程可以理解为局部SLAM,或者说前端: 采集传感信息,形成地图的过程,下面介绍全局优化的基本思路
经过局部SLAM形成结果InsertionResult,主要包括rangde_data,也就是所谓的node和当前的submaps;把结果插入到pose_graph中进一步计算node和submap以及其它约束(odom,landmark)的约束关系(constraints),并根据参数,options_.optimize_every_n_nodes()决定什么时候运行一次全局优化.
基本代码结构:
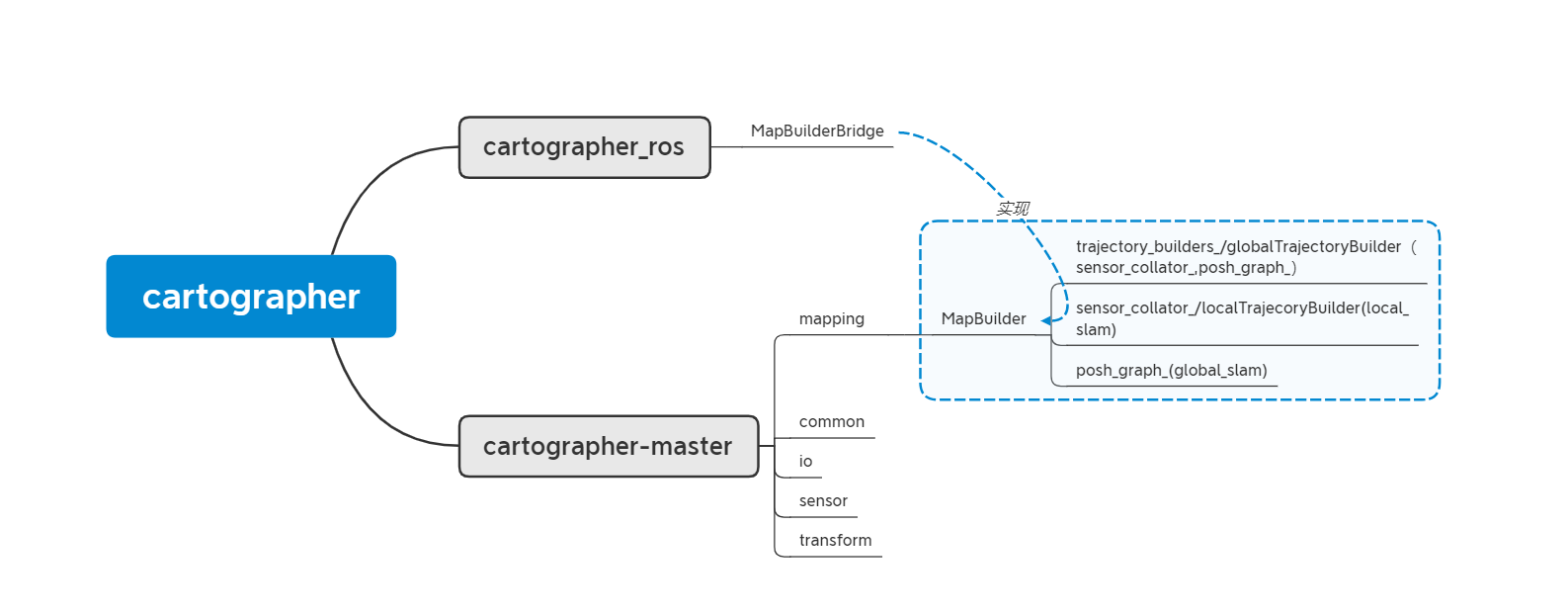
mapBuilder:实现整个地图构建,包括前端local slam和后端 global slam。
轨迹(trajectory): 可以理解为一次SLAM 从起点到终点过程中的机器人行走轨迹,建图中可以通过startTrajectory和finishTrajectory控制。在轨迹生成的过程中,完成sensor到sumap的生成,以及pose_graph的构建。TrajectoryBuilder(globalTrajectory类)主要通过sensor_collator(localTrajecory类)和pose_graph构成 。sensor_collator实现局部地图构建,最终结果传递给pose_graph;
节点图(poseGraph):具体参考图优化的知识。简单理解图优化(如果没接触过图优化,下面估计看不懂,后续会详细讲):每个插入的激光和生成sumap,以及landmark(后续讲)都可以理解为图优化的一个节点,建图过程中,生成这些点之间的关系,这些关系便是图中的线,最终优化,就是调整点的位置,得到最优值。可以理解为PoseGraph主要实现全局优化(global slam)功能。
代码流程:最终代码运行通过ROS node 方式实现。node中对应topic和service订阅和发布等功能通过MapBuilderBridge类实现。MapBuilderBridge顾名思义,实现ROS节点代码和cartographer功能代码之间的桥接,也可以理解为对cartographer主体代码的接口封装。cartographer主体代码主要功能通过构建地图MapBuilder类实现。此外,MapBuilderBridge 还包含sensorBridge类,实现传感信息ros格式和cartographer自定义格式之间的转换,这些传感器主要包括scan,imu,odom,tf 等。
MapBuilder 类源码注释:
// Wires up the complete SLAM stack with TrajectoryBuilders (for local submaps)
// and a PoseGraph for loop closure.
// 人话:把局部SLAM中submap,node等连接起来,形成 PoseGraph,以便回环优化。
class MapBuilder : public MapBuilderInterface{}
总结:
整个SLAM 过程主要通过TrajectoryBuilder 完成,实现sensor到submap的构建,以及pose_graph 的构建,最后通过pose_graph 实现最终全局优化(finalOptimization)。
其它代码说明:
mapping :实现建图功能
以下四个文件夹都是mapping中要用到的库函数。
common: 时间戳处理,数据统计,参数读取,线程池构建,任务队列等。
io: 读写文件,读写地图,数据类型(proto,pcd,地图grid)转换等。
sensor: range(激光),cloud,imu,odom数据类型封装。
transform: 坐标系转换。
scan处理流程
从scan处理过程理解代码结构。采取至上而下的方式。为了便于理解,以下代码中,删去了大部门源码,仅仅留存我们需要关注的部分。
cartographer_ros/node.cc
// ros node中处理订阅到的激光数据
void Node::HandleLaserScanMessage(const sensor_msgs::LaserScan::ConstPtr& msg) {
map_builder_bridge_.sensor_bridge(trajectory_id)->HandleLaserScanMessage(sensor_id, msg);
}
cartographer_ros/sensor_bridge.cc
void SensorBridge::HandleLaserScanMessage(
const std::string& sensor_id, const sensor_msgs::LaserScan::ConstPtr& msg) {
std::tie(point_cloud, time) = ToPointCloudWithIntensities(*msg);
HandleLaserScan(sensor_id, time, msg->header.frame_id, point_cloud)
{
carto::sensor::TimedPointCloud ranges getfrom(points);
HandleRangefinder( ranges)
{
//trajectory_builder_:通过CollatedTrajectoryBuilder实现
trajectory_builder_->AddSensorData(
sensor_id, carto::sensor::TimedPointCloudData{
carto::sensor::TransformTimedPointCloud(ranges)});
}
}
}
cartographer/mapping/internal/collated_trajectory_builder.cc *****
class CollatedTrajectoryBuilder : public TrajectoryBuilderInterface{
void AddSensorData(
const std::string& sensor_id,
const sensor::TimedPointCloudData& timed_point_cloud_data) override {
AddData(sensor::MakeDispatchable(sensor_id, timed_point_cloud_data));
}
}
void CollatedTrajectoryBuilder::AddData(std::unique_ptr<sensor::Data> data) {
// sensor_collator_:通过Collator实现
sensor_collator_->AddSensorData(trajectory_id_, std::move(data));
}
cartographer/sensor/internal/collator.cc
void Collator::AddSensorData(const int trajectory_id,
std::unique_ptr<Data> data) {
QueueKey queue_key{trajectory_id, data->GetSensorId()};
queue_.Add(std::move(queue_key), std::move(data));
}
cartographer/sensor/internal/Ordered_multi_queue.cc
void OrderedMultiQueue::Add(const QueueKey& queue_key,
std::unique_ptr<Data> data) {
auto it = queues_.find(queue_key); // 插入数据
it->second.queue.Push(std::move(data)); // 并处理 通过call_back 函数处理数据
Dispatch();//调用一次Add()就要调用一次Dispatch()
}
接下来,寻找处理数据的函数call_back 具体实现形式。从下往上回溯。
由于call_back 函数是在collator.cc 中Collator类的函数AddTrajectory定义的。
cartographer/sensor/internal/collator.cc
void Collator::AddTrajectory(
const int trajectory_id,
const absl::flat_hash_set<std::string>& expected_sensor_ids,
const Callback& callback) { // call_back 函数在此引入
for (const auto& sensor_id : expected_sensor_ids) {
const auto queue_key = QueueKey{trajectory_id, sensor_id};
queue_.AddQueue(queue_key,
[callback, sensor_id](std::unique_ptr<Data> data) {
callback(sensor_id, std::move(data));
});
queue_keys_[trajectory_id].push_back(queue_key);
}
}
cartographer/mapping/internal/collated_trajectory_builder.cc *****
CollatedTrajectoryBuilder::CollatedTrajectoryBuilder(
const proto::TrajectoryBuilderOptions& trajectory_options,
sensor::CollatorInterface* const sensor_collator, const int trajectory_id,
const std::set<SensorId>& expected_sensor_ids,
std::unique_ptr<TrajectoryBuilderInterface> wrapped_trajectory_builder)
: sensor_collator_(sensor_collator),
collate_landmarks_(trajectory_options.collate_landmarks()),
collate_fixed_frame_(trajectory_options.collate_fixed_frame()),
trajectory_id_(trajectory_id),
wrapped_trajectory_builder_(std::move(wrapped_trajectory_builder)),
last_logging_time_(std::chrono::steady_clock::now()) {
sensor_collator_->AddTrajectory(
trajectory_id, expected_sensor_id_strings,
[this](const std::string& sensor_id, std::unique_ptr<sensor::Data> data) {
HandleCollatedSensorData(sensor_id, std::move(data)); // call_back 函数在此实现
});
}
void CollatedTrajectoryBuilder::HandleCollatedSensorData(
const std::string& sensor_id, std::unique_ptr<sensor::Data> data) {
data->AddToTrajectoryBuilder(wrapped_trajectory_builder_.get());
}
// 到此,对data的处理过程: call_back 调用HandleCollatedSensorData ,再调用AddToTrajectoryBuilder , 传入 wrapped_trajectory_builder_
wrapped_trajectory_builder_ 的具体实现形式是在初始化CollatedTrajectoryBuilder过程中声明的。
也就是在定义trajectory_builder_ 时,定义的。
trajectory_builder_ 定义在cartographer_ros/sensor_bridge.cc 中。 具体通过 map_builder.cc 实现:
int MapBuilder::AddTrajectoryBuilder(
const std::set<SensorId>& expected_sensor_ids,
const proto::TrajectoryBuilderOptions& trajectory_options,
LocalSlamResultCallback local_slam_result_callback) {
....
trajectory_builders_.push_back(absl::make_unique<CollatedTrajectoryBuilder>(
trajectory_options, sensor_collator_.get(), trajectory_id,
expected_sensor_ids,
CreateGlobalTrajectoryBuilder2D( // call_back函数的具体形式在此定义
std::move(local_trajectory_builder), trajectory_id,
static_cast<PoseGraph2D*>(pose_graph_.get()),
local_slam_result_callback)));
....
}
到此,基本完成了从下到上对call_back 函数的最终,最后,通过CreateGlobalTrajectoryBuilder2D,由GlobalTrajectoryBuilder2D类实现。
总结
从ros node 在调用函数处理scan信息,最终压入队列queue,该过程中,同时定义了queue的call_back 函数,具体实现流程如下:
从node.cpp -> map_builder_bridge.cc(sensor_bridge <- map_builder) -> collated_trajectory_builder.cc ->collator.cc -> queue.cc
主要涉及的变量: map_builder_bridge <- trajectory_builder < queue_
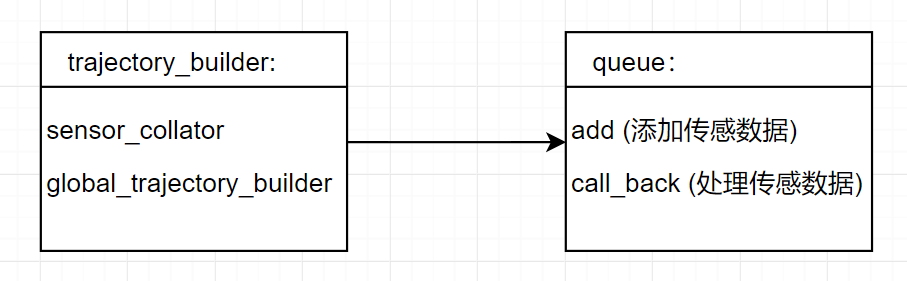
同样的,对于imu和odom里程计数据,处理方式相似。接下来就需要研究这个核心类。看看scan怎么处理的。
参考上面程序 cartographer/mapping/internal/collated_trajectory_builder.cc,可知,处理data的方式,通过
data->AddToTrajectoryBuilder(wrapped_trajectory_builder_.get()) 实现,这里的wrapped_trajectory_builder_ 即为 GlobalTrajectoryBuilder 类型。
sensor/internal/dispatchable.h
class Dispatchable : public Data {
public:
void AddToTrajectoryBuilder(
mapping::TrajectoryBuilderInterface *const trajectory_builder) override {
trajectory_builder->AddSensorData(sensor_id_, data_);
}
显然,data的处理方式是通过GlobalTrajectoryBuilder -> AddSensorData(...)函数来实现的。
cartographer/mapping/internal/global_trajectory_builder.cc
std::unique_ptr<TrajectoryBuilderInterface> CreateGlobalTrajectoryBuilder2D(
std::unique_ptr<LocalTrajectoryBuilder3D> local_trajectory_builder,
const int trajectory_id, mapping::PoseGraph3D* const pose_graph,
const TrajectoryBuilderInterface::LocalSlamResultCallback&
local_slam_result_callback) {
return absl::make_unique<
GlobalTrajectoryBuilder<LocalTrajectoryBuilder3D, mapping::PoseGraph3D>>(
std::move(local_trajectory_builder), trajectory_id, pose_graph,
local_slam_result_callback);
}
// 因此组成global_trajectory_builder主要有三个变量:
// 1. local_trajectory_builder
// 2. pose_graph
// 3. local_slam_result_callback
void AddSensorData(
const std::string& sensor_id,
const sensor::TimedPointCloudData& timed_point_cloud_data) override {
matching_result = local_trajectory_builder_->AddRangeData(
sensor_id, timed_point_cloud_data);
auto node_id = pose_graph_->AddNode(
matching_result->insertion_result->constant_data, trajectory_id_,
matching_result->insertion_result->insertion_submaps);
insertion_result = absl::make_unique<InsertionResult>(InsertionResult{
node_id, matching_result->insertion_result->constant_data,
std::vector<std::shared_ptr<const Submap>>(
matching_result->insertion_result->insertion_submaps.begin(),
matching_result->insertion_result->insertion_submaps.end())});
}
if (local_slam_result_callback_) {
local_slam_result_callback_(
trajectory_id_, matching_result->time, matching_result->local_pose,
std::move(matching_result->range_data_in_local),
std::move(insertion_result));
}
}
// 通过该函数我们知道,对激光信号处理主要经过了四个过程(可以与流程图对照):
// 1. local_trajectory_builder_ addRangeData() 结合里程计数据进行激光匹配
// 2. 把匹配结果加入全局优化图pose_graph 中
// 3. 插入当前局部地图submap中
// 4. 执行 local_slam_result_callback 函数。 local_slam_result_callback 在调用CreateGlobalTrajectoryBuilder2D 时候定义。CreateGlobalTrajectoryBuilder2D在map_builder_调用,map_builder 被 map_builder_bridge 调用。 最终,local_slam_result_callback的定义在map_builder_bridge
cartographer_ros/map_builder_bridge.cc
void MapBuilderBridge::OnLocalSlamResult(
const int trajectory_id, const ::cartographer::common::Time time,
const Rigid3d local_pose,
::cartographer::sensor::RangeData range_data_in_local) {
std::shared_ptr<const LocalTrajectoryData::LocalSlamData> local_slam_data =
std::make_shared<LocalTrajectoryData::LocalSlamData>(
LocalTrajectoryData::LocalSlamData{time, local_pose,
std::move(range_data_in_local)});
local_slam_data_[trajectory_id] = std::move(local_slam_data);
}
// 最终把局部slam结果传到local_slam_data_ 这个变量中,便于用户调阅查看。
以上便事local_slam的过程。
pose_graph
pose_graph变量是在map_builder.cc定义的,负责处理全局优化问题 (后端). 全局优化过程与前端local_slam,同时进行,通过多线程的方式实现. 可以简单理解为:map_builder 在建立local_trajectory_builder 接受scan数据进行地图构建的过程中,同时构建全局优化(optimization_problem)对应的线程,进行后端优化.
cartographer/mapping/internal/2d/pose_graph_2d.h
PoseGraph2D(
const proto::PoseGraphOptions& options, // 配置参数
std::unique_ptr<optimization::OptimizationProblem2D> optimization_problem,//全局优化主体
common::ThreadPool* thread_pool // 处理全局优化的线程池(可以是一个线程或多个线程)
);
简单看下,线程池使用方法:
cartographer/common/thread_pool.h
// 下面代码为源码简化版
class ThreadPool : public ThreadPoolInterface {
public:
explicit ThreadPool(int num_threads);//初始化一个线程数量固定的线程池。
std::weak_ptr<Task> Schedule(std::unique_ptr<Task> task) //添加想要ThreadPool执行的task,
// 插入tasks_not_ready_,如果任务满足执行要求,直接插入task_queue_准备执行
LOCKS_EXCLUDED(mutex_) override;
private:
void DoWork();//每个线程初始化时,执行DoWork()函数. 与线程绑定
std::deque<std::shared_ptr<Task>> task_queue_ GUARDED_BY(mutex_); // 准备执行的task
task可能有依赖还未完成
GUARDED_BY(mutex_);
};
// 线程池初始化时,每个线程与DoWork()函数绑定,也就是线程在后台不断执行DoWork()函数.
// DoWork()函数负责处理 task_queue_ 内的task(函数)
// task 通过 ThreadPool::Schedule 函数压入.
//总结: ThreadPool初始化后,通过Schedule 压入内部任务队列,并安装队列顺序执行任务.
了解以上内容后,便可以进入pose_graph 看 optimization_problem 是怎样通过 ThreadPool 进行后台执行的.
// AddNode的主要工作是把一个TrajectoryNode的数据加入到PoseGraph维护的trajectory_nodes_这个容器中。并返回加入的节点的Node. 在global_trajectory_builder.AddSensorData()中调用.
NodeId PoseGraph2D::AddNode(
std::shared_ptr<const TrajectoryNode::Data> constant_data,
const int trajectory_id,
const std::vector<std::shared_ptr<const Submap2D>>& insertion_submaps) {e
// 生成的optimized_pose就是该节点的绝对位姿
const transform::Rigid3d optimized_pose(
GetLocalToGlobalTransform(trajectory_id) * constant_data->local_pose);
const NodeId node_id = trajectory_nodes_.Append(
trajectory_id, TrajectoryNode{constant_data, optimized_pose});
// 节点数加1.
++num_trajectory_nodes_;
const SubmapId submap_id =
submap_data_.Append(trajectory_id, InternalSubmapData());
submap_data_.at(submap_id).submap = insertion_submaps.back();
// 检查insertion_submaps的第一个submap是否已经被finished了。
// 如果被finished,那么我们需要计算一下约束并且进行一下全局优化了。
// 这里是把这个工作交到了workItem中等待处理(通过线程池thread_pool处理)
const bool newly_finished_submap = insertion_submaps.front()->finished();
AddWorkItem([=]() REQUIRES(mutex_) { //该部分用到lamda表达式结果作为addWorkItem()输入参数
ComputeConstraintsForNode(node_id, insertion_submaps,
newly_finished_submap);
});
// 上述都做完了,返回node_id.
return node_id;
}
// 该函数实现 node 和 submaps 插入 pose_graph, 并把优化工作交给线程池处理.
// 我们需要进一步查看 AddWorkItem 和 ComputeConstraintsForNode;
void PoseGraph2D::AddWorkItem( // std::function<outType(inType)> f
const std::function<WorkItem::Result()>& work_item) {
absl::MutexLock locker(&work_queue_mutex_);
if (work_queue_ == nullptr) { //当work_queue_为空时... 由于work_queue_ 大部分时候非空,为了先看基本逻辑,该调节暂且认为不成立.所以,AddWorkItem函数主要执行 下面push_back部分
work_queue_ = absl::make_unique<WorkQueue>();
auto task = absl::make_unique<common::Task>();
task->SetWorkItem([this]() { DrainWorkQueue(); });
thread_pool_->Schedule(std::move(task));
}
const auto now = std::chrono::steady_clock::now();
work_queue_->push_back({now, work_item}); // AddWorkItem 每次执行主要部分
}
// 通过以上两个函数,可知,每次addNode时,会把ComputeCocnstraintsForNode(计算约束)函数压入work_queue_. 到此,可以猜测work_queue_的处理函数一定被塞入线程执行. 因此,我们下一步寻找,被压入线程池执行的函数(task)
//work_queue_ = {{time1,ComputeCocnstraintsForNode1},{time2,ComputeCocnstraintsForNode2}, ... }
// 通过搜索,发现,仅有一处thread_pool_->Schedule(task),压入的函数为: DrainWorkQueue()
// Process pending tasks in the work queue on the calling thread, until the
// queue is either empty or an optimization is required.
void PoseGraph2D::DrainWorkQueue() {
bool process_work_queue = true;
size_t work_queue_size;
while (process_work_queue) {
std::function<WorkItem::Result()> work_item;
{
absl::MutexLock locker(&work_queue_mutex_);
if (work_queue_->empty()) {
work_queue_.reset();
return; // work_queue_ 空的时候, thread_pool中DrainWorkQueue执行完,等待下一次addNode时候,再次执行thread_pool_->Schedule(task),再次执行.
}
work_item = work_queue_->front().task;
work_queue_->pop_front();
work_queue_size = work_queue_->size();
}
process_work_queue = work_item() == WorkItem::Result::kDoNotRunOptimization;
// 执行work_item() 也就是ComputeCocnstraintsForNode 并判断是否需要运行优化
// 如果需要需要优化,则work_item() = WorkItem::Result::NotRunOptimization, while退出,
// 如果work_item()都不需要全局优化,则直到work_queue_为空,下面的优化函数不会执行.
}
LOG(INFO) << "Remaining work items in queue: " << work_queue_size;
// We have to optimize again. when constraint_builder done
constraint_builder_.WhenDone(
[this](const constraints::ConstraintBuilder2D::Result& result) {
HandleWorkQueue(result);// 执行全局优化.
});
}
总结:我们已经明白全局规划的程序思路. 从addNode开始.每次addNode后,会把ComputeCocnstraintsForNode以workItem的形式,压入work_queue_中,交给DrainWorkQueue依次执行.当没有任务时(比如初始化时),DrainWorkQueue作为task的形式被压入到thread_pool中进行处理. 最后,当需要执行全局优化时(这个调节可以由ComputeCocnstraintsForNode结果控制),进行全局优化(HandleWorkQueue).