1、索引的本质是:索引是帮助MySQL高效获取数据的排好序的数据结构
(1) 索引的数据结构有:

2、MySQL的底层是B+树,B+树能进行水平扩展,高度仅仅为3就能存储几千万的数据。
3、数据库表中的每张表对应的MySQL本地data文件夹下都有几个文件(前缀相同)
4、聚集(束)索引:叶节点包含了完整的数据记录 。简单讲就是:索引和数据放在一起
5、MylSAM索引文件和数据文件是分离的(非聚集),非聚集索引=稀疏索引
InnoDB索引文件和数据文件不是分离的(聚集)
6、聚集索引比非聚集索引查询速度快
7、主键用的uuid什么意思?
整型所占的内存比uuid小,查询的速度比uuid快,因为比较整型比比较字符串更加快, 而且比uuid节约更多的成本。MySQL一般占用的是高速缓存,比较贵。
8、Hash算法在等值查找的时候效率很高,如:where id=10,但是对于范围查找的效率远不如 B+树,如where id>10.因为hash地址是无序的,而B+树的叶子节点是有序排列的。
9、B树与B+ 树的区别:
(1) B树没有冗余索引,而B+树的非叶子节点都是冗余索引
(2) B树的叶子节点之间是相互独立的,没有联系;而B+树的叶子节点之间是个有序的双向链表,每个叶子节点和前后节点都有关联。
(3) B+树把B树的data数据全部移动到叶子节点,非叶子节点是没有数据的。
(4) 高度相同的情况下,B+树能存储的数据远远超过B树
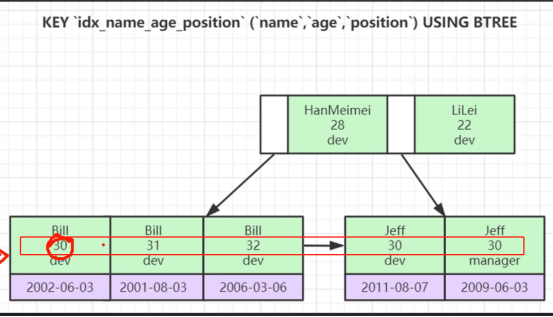
10、联合索引:
(1) 多个索引字段如何比较大小:如:(“name”“age“”position”)
① 他会按照顺序比较,先比较name,如果name比较好了,就不用看下面的字段了,如果相等继续比较下面的age字段。
② 联合索引的第一个字段再整张表的范围看是从左到右有序的,但是第二、三个字段不一定有序。