Springboot2整合kafka
kafka是一个分布式消息队列。在项目中应用十分广泛,具有高性能、持久化、多副本备份、横向扩展能力。
kafka
- 在多台机器上分别部署Kafka,即Kafka集群。每台机器运行的Kafka服务称为broker。
- 一个Topic主题可以被分为若干个分区(partition),每个分区在存储层面是append log文件。
- 分区(Partition )为Kafka提供了可伸缩性,水平扩展功能。
- 多副本机制(Partition Replica)提高了kafka的数据可靠性和容灾能力。
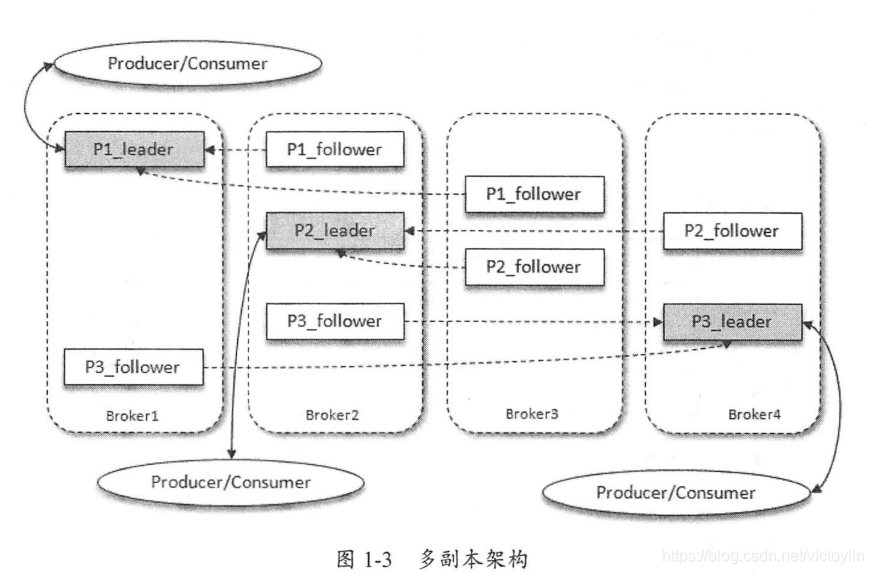
图片来源《深入理解kafka核心设计和实践原理》
docker上安装环境
1.安装zookeeper 和 安装kafka
- 这里使用了wurstmeister/kafka和wurstmeister/zookeeper这两个版本的镜像
2.运行镜像
- 整个启动过程遇到了8个左右报错,一个个解决,最后运行成功,简单列几个
- Please define KAFKA_LISTENERS / (deprecated) KAFKA_ADVERTISED_HOST_NAME
- WARN Session 0x0 for server zookeeper:2181, unexpected error, closing socket
- java.nio.channels.UnresolvedAddressException
- could not be established. Broker may not be available
- Give up sending metadata request since no node is available
- 总结下最后的启动命令,依此启动zookeeper和kafka
docker run --name zk01 -p 2181:2181 --restart always -d zookeeper
- 1
docker run --name kafka01 -e HOST_IP=localhost -e KAFKA_ADVERTISED_PORT=9092 -e KAFKA_ADVERTISED_HOST_NAME=localhost -e KAFKA_ZOOKEEPER_CONNECT="192.168.0.111:2181" -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.111:9092 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 -e KAFKA_BROKER_ID=1 -e ZK=zk -p 9092 --link zk01:zk -t wurstmeister/kafka
- 1
Springboot2引入kafka
<!--引入Kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 1
- 2
- 3
- 4
- 5
- application.properties配置
#kafka配置
spring.kafka.bootstrap-servers=192.168.0.111:9092
#=============== provider =======================
spring.kafka.producer.retries=0
# 每次批量发送消息的数量
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#=============== consumer =======================
# 指定默认消费者group id
spring.kafka.consumer.group-id=test-consumer-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
基于注解
生产
@Component
public class KafkaProducer {
private static final String MY_TOPIC = "TOPIC_LIN_LIANG";
@Autowired
KafkaTemplate kafkaTemplate;
public void produce(){
Message message = new Message();
message.setId(12L);
message.setMsg("hello jack");
message.setTime(new Date());
kafkaTemplate.send(MY_TOPIC,message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
消费
@KafkaListener可以接受的参数有:
- data : 对于data值的类型其实并没有限定,根据KafkaTemplate所定义的类型来决定。 data为List集合的则是用作批量消费。
- ConsumerRecord:具体消费数据类,包含Headers信息、分区信息、时间戳等
- Acknowledgment:用作Ack机制的接口
- Consumer:消费者类,使用该类我们可以手动提交偏移量、控制消费速率等功能
public void listen1(String data)
public void listen2(ConsumerRecord<K,V> data)
public void listen3(ConsumerRecord<K,V> data, Acknowledgment acknowledgment)
public void listen4(ConsumerRecord<K,V> data, Acknowledgment acknowledgment, Consumer<K,V> consumer)
public void listen5(List<String> data)
public void listen6(List<ConsumerRecord<K,V>> data)
public void listen7(List<ConsumerRecord<K,V>> data, Acknowledgment acknowledgment)
public void listen8(List<ConsumerRecord<K,V>> data, Acknowledgment acknowledgment, Consumer<K,V> consumer)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用示例
@KafkaListener(topics = {MY_TOPIC})
public void consume(String message){
log.info("receive msg "+ message);
}
- 1
- 2
- 3
- 4
基于客户端
0.9x版本后的kafka客户端使用java语言编写,本人更倾向于这种开发方式。
在配置中注释了基本意思,具体参考了朱忠华的《深入理解kafka:核心设计和实现原理》,学kafka感觉这一本就够了。
/**
* linliang
*/
@Configuration
public class Kafka_Config implements InitializingBean {
@Value("${kafka.broker.list}")
public String brokerList;
public static final String topic = "TOPIC_LIN_LIANG";
public final String groupId = "group.01";
public Properties customerConfigs() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);//自动位移提交
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 100);//自动位移提交间隔时间
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);//消费组失效超时时间
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");//位移丢失和位移越界后的恢复起始位置
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
return props;
}
public Properties producerConfigs() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 20000000);//20M 消息缓存
//生产者空间不足时,send()被阻塞的时间,默认60s
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 6000);
//生产者重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 0);
//指定ProducerBatch(消息累加器中BufferPool中的)可复用大小
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//生产者会在ProducerBatch被填满或者等待超过LINGER_MS_CONFIG时发送
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.demo");
return props;
}
@Bean
public Producer<Integer, Object> getKafkaProducer() {
//KafkaProducer是线程安全的,可以在多个线程中共享单个实例
return new KafkaProducer<Integer, Object>(producerConfigs());
}
@Override
public void afterPropertiesSet() throws Exception {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
生产
@Component
public class Kafka_Producer {
public String topic = Kafka_Config.topic;
@Autowired
Producer producer;
public void producer() throws Exception {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!");
try {
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println(metadata.partition() + ":" + metadata.offset());
}
}
});
} catch (Exception e) {
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
消费
@Component
public class Kafka_Consumer implements InitializingBean {
public String topic = Kafka_Config.topic;
@Autowired
Kafka_Config kafka_config;
@Override
public void afterPropertiesSet() throws Exception {
//每个线程一个KafkaConsumer实例,且线程数设置成分区数,最大化提高消费能力
int consumerThreadNum = 2;//线程数设置成分区数,最大化提高消费能力
for (int i = 0; i < consumerThreadNum; i++) {
new KafkaConsumerThread(kafka_config.customerConfigs(), topic).start();
}
}
public class KafkaConsumerThread extends Thread {
private KafkaConsumer<String, String> kafkaConsumer;
public KafkaConsumerThread(Properties props, String topic) {
this.kafkaConsumer = new org.apache.kafka.clients.consumer.KafkaConsumer<>(props);
this.kafkaConsumer.subscribe(Arrays.asList(topic));
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records =
kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("message------------ "+record.value());
}
}
} catch (Exception e) {
} finally {
kafkaConsumer.close();
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
欢迎关注公众号fbzl95