Kubernetes实战模拟一(wordpress基础版)
Kubernetes实战模拟二(wordpress高可用)
Kubernetes实战模拟三(wordpress健康检查和服务质量QoS)
Kubernetes实战模拟四(wordpress升级更新)
源码地址:https://github.com/nangongchengfeng/Kubernetes/tree/main/wordpress-example
Kubernetes实战模拟三,已经构建wordpress的健康检查和服务质量,对后期的稳定运行有一定的帮助
(1)startupProbe,首次启动探测,如果没有成功,不会运行下面的检测。配置有restartPolicy:Always 会自动的重启
(2)健康检查,采取readinessProbe方式,如果检查失败,kubernetes会把Pod从service endpoints中剔除,不在提供流量,错误现场保留,方便排查问题
(3)fortio 压测,模拟生产环境,确定resources的数值。采用Guaranteed(有保证的),防止宿主机资源不够被优先驱逐
版本4
思路:类似wordpress是静态服务,后期可能有版本的变更,我们都需要更新和升级pod,我们接下来优化升级更新操作
Kubernetes官方推荐使用Deployment来取代Rep
lication Controller(rc) ,两者间主要相同点包括确保处在服务状态的Pod数量(replicas)能满足先前所设定的值以及支援滚动升级(Rolling update),前者额外支持回滚(Roll back)的机制,因此接下来会介绍如何利用Deployment来进行滚动升级。
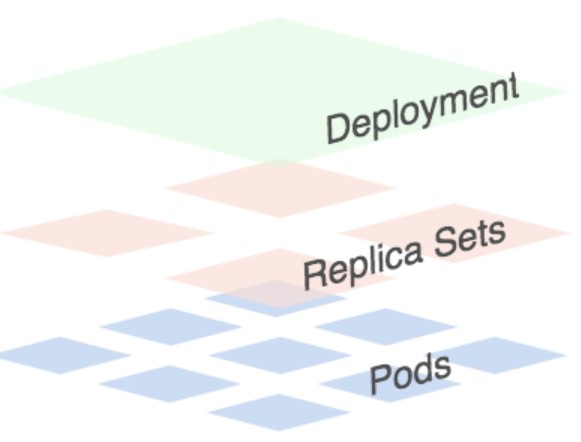
图中可以看到一个Deployment掌管一或多个Replica Set ,而一个Replica Set掌管一或多个Pod
版本升级
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2
maxUnavailable: 2
minReadySeconds: 5
revisionHistoryLimit: 10 # 最多保留10个升级副本,便于回滚minReadySeconds:
Kubernetes在等待设置的时间后才进行升级 (容器内应用的启动时间, pod变为run状态, 会在minReadySeconds后继续更新下一个pod.)
如果没有设置该值,Kubernetes会假设该容器启动起来后就提供服务了
如果没有设置该值,在某些极端情况下可能会造成服务不正常运行
maxSurge:
升级过程中最多可以比原先设置多出的POD数量
例如:maxSurage=1,replicas=5,则表示Kubernetes会先启动1一个新的Pod后才删掉一个旧的POD,整个升级过程中最多会有5+1个POD。
maxUnavaible:
升级过程中最多有多少个POD处于无法提供服务的状态
当maxSurge不为0时,该值也不能为0
例如:maxUnavaible=1,则表示Kubernetes整个升级过程中最多会有1个POD处于无法服务的状态。
Deployment 控制器默认的就是滚动更新的更新策略,该策略可以在任何时间点更新应用的时候保证某些实例依然可以正常运行来防止应用 down 掉,当新部署的 Pod 启动并可以处理流量之后,才会去杀掉旧的 Pod。在使用过程中我们还可以指定 Kubernetes 在更新期间如何处理多个副本的切换方式,比如我们有一个3副本的应用,在更新的过程中是否应该立即创建这3个新的 Pod 并等待他们全部启动,或者杀掉一个之外的所有旧的 Pod,或者还是要一个一个的 Pod 进行替换?
如果我们从旧版本到新版本进行滚动更新,只是简单的通过输出显示来判断哪些 Pod 是存活并准备就绪的,那么这个滚动更新的行为看上去肯定就是有效的,但是往往实际情况就是从旧版本到新版本的切换的过程并不总是十分顺畅的,应用程序很有可能会丢弃掉某些客户端的请求。比如我们在 Wordpress 应用中添加上如下的滚动更新策略,随便更改以下 Pod Template 中的参数,比如容器名更改为 blog:
这里修改wordpress.yaml
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: kube-example
spec:
selector:
app: wordpress
tier: frontend
ports:
- port: 80
name: web
targetPort: wdport
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
namespace: kube-example
labels:
app: wordpress
tier: frontend
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
replicas: 4 #多副本+pod的反亲合力可以实现pod的高可用
strategy: # 滚动更新的更新策略
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # 表示Kubernetes会先启动1一个新的Pod后才删掉一个旧的POD,整个升级过程中最多会有5+1个POD。
maxUnavailable: 1 # 表示Kubernetes整个升级过程中最多会有1个POD处于无法服务的状态。
minReadySeconds: 5 # 容器内应用的启动时间, pod变为run状态, 会在minReadySeconds后继续更新下一个pod.
revisionHistoryLimit: 10 # 最多保留10个升级副本,便于回滚
template:
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
containers:
- name: wordpress
image: wordpress:5.3.2-apache
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 800m
memory: 150Mi
requests:
cpu: 800m
memory: 150Mi
startupProbe: #首次启动探测(如果没有成功,不会运行下面livenessProbe)
httpGet:
port: 80
failureThreshold: 2 #探测成功后,最少连续探测失败多少次才被认定为失败。默认是3。最小值是1。
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
timeoutSeconds: 10 # 探测超时时间。默认1秒,最小1秒。
periodSeconds: 5 # 执行探测的频率。默认是10秒,最小1秒。
readinessProbe: # (就绪检查) # 如果检查失败,kubernetes会把Pod从service endpoints中剔除
tcpSocket:
port: 80
initialDelaySeconds: 10
timeoutSeconds: 5
failureThreshold: 5
periodSeconds: 5
successThreshold: 3
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- wordpress
restartPolicy: Always
测试
运行时压测

更新时压测(显示500)

问题分析
从上面的输出可以看出有部分请求处理失败了(502),要弄清楚失败的原因就需要弄明白当应用在滚动更新期间重新路由流量时,从旧的 Pod 实例到新的实例究竟会发生什么,首先让我们先看看 Kubernetes 是如何管理工作负载连接的。
失败原因
我们这里通过 NodePort 去访问应用,实际上也是通过每个节点上面的 kube-proxy 通过更新 iptables 规则来实现的。
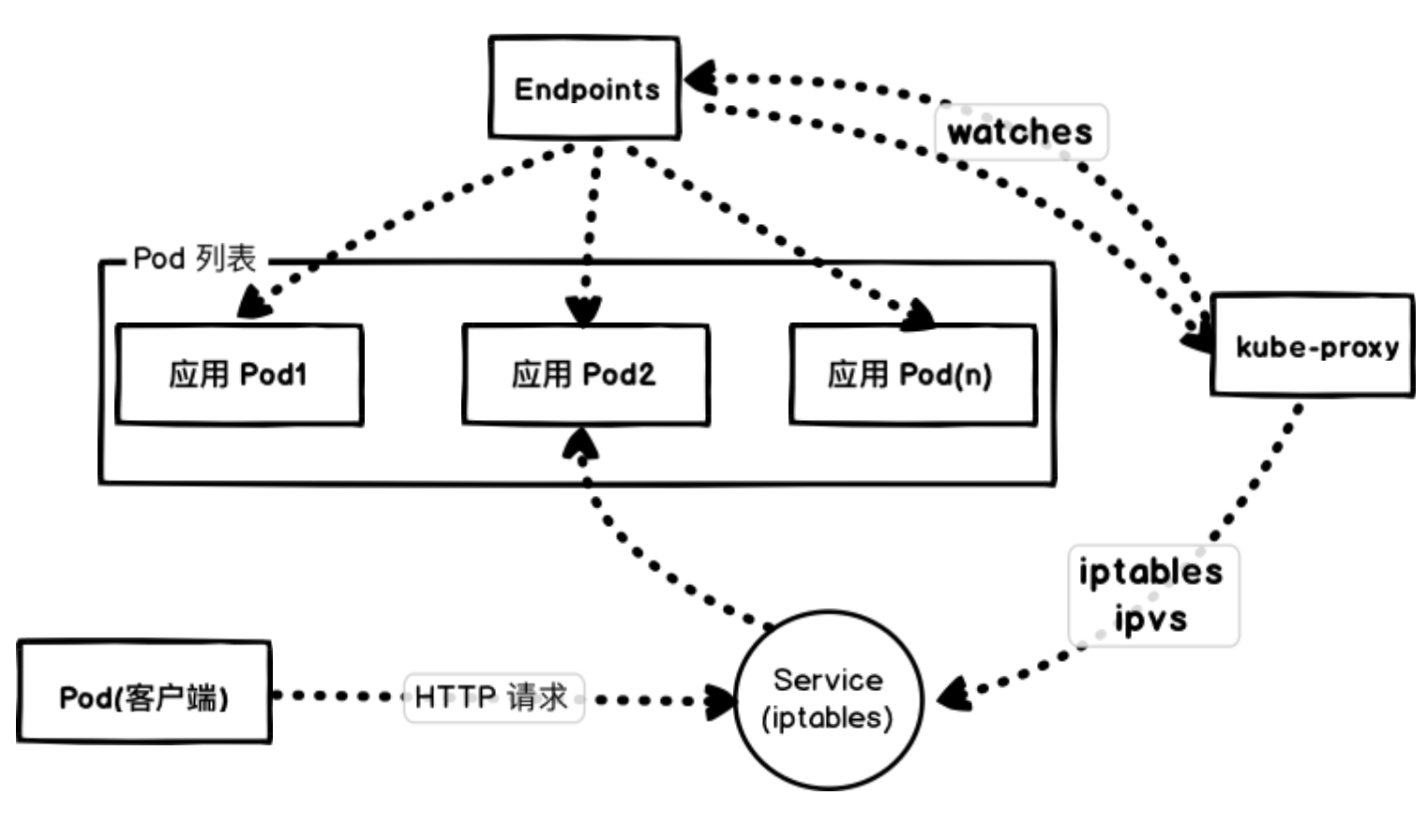
Kubernetes 会根据 Pods 的状态去更新 Endpoints 对象,这样就可以保证 Endpoints 中包含的都是准备好处理请求的 Pod。一旦新的 Pod 处于活动状态并准备就绪后,Kubernetes 就将会停止就的 Pod,从而将 Pod 的状态更新为 “Terminating”,然后从 Endpoints 对象中移除,并且发送一个 SIGTERM 信号给 Pod 的主进程。SIGTERM 信号就会让容器以正常的方式关闭,并且不接受任何新的连接。Pod 从 Endpoints 对象中被移除后,前面的负载均衡器就会将流量路由到其他(新的)Pod 中去。因为在负载均衡器注意到变更并更新其配置之前,终止信号就会去停用 Pod,而这个重新配置过程又是异步发生的,并不能保证正确的顺序,所以就可能导致很少的请求会被路由到已经终止的 Pod 上去了,也就出现了上面我们说的情况。
问题解决
那么如何增强我们的应用程序以实现真正的零宕机迁移更新呢?
首先,要实现这个目标的先决条件是我们的容器要正确处理终止信号,在 SIGTERM 信号上实现优雅关闭。下一步需要添加 readiness 可读探针,来检查我们的应用程序是否已经准备好来处理流量了。为了解决 Pod 停止的时候不会阻塞并等到负载均衡器重新配置的问题,我们还需要使用 preStop 这个生命周期的钩子,在容器终止之前调用该钩子。
生命周期钩子函数是同步的,所以必须在将最终停止信号发送到容器之前完成,在我们的示例中,我们使用该钩子简单的等待,然后 SIGTERM 信号将停止应用程序进程。同时,Kubernetes 将从 Endpoints 对象中删除该 Pod,所以该 Pod 将会从我们的负载均衡器中排除,基本上来说我们的生命周期钩子函数等待的时间可以确保在应用程序停止之前重新配置负载均衡器
lifecycle
创建资源对象时,可以使用lifecycle来管理容 器在运行前和关闭前的一些动作。
lifecycle有两种回调函数:
PostStart: 容器创建成功后,运行前的任务,用于资源部署、环境准备等。
PreStop: 在容器被终止前的任务,用于优雅关闭应用程序、通知其他系统等等。
我们这里使用 preStop 设置了一个 20s 的宽限期,Pod 在真正销毁前会先 sleep 等待 20s,这就相当于留了时间给 Endpoints 控制器和 kube-proxy 更新去 Endpoints 对象和转发规则,这段时间 Pod 虽然处于 Terminating 状态,即便在转发规则更新完全之前有请求被转发到这个 Terminating 的 Pod,依然可以被正常处理,因为它还在 sleep,没有被真正销毁。
现在,当我们去查看滚动更新期间的 Pod 行为时,我们将看到正在终止的 Pod 处于 Terminating 状态,但是在等待时间结束之前不会关闭的,如果我们使用 Fortio 重新测试下,则会看到零失败请求的理想状态。
lifecycle:
preStop: # 在容器被终止前的任务,用于优雅关闭应用程序
exec:
command: ["/bin/bash", "-c", "sleep 20"] #睡眠20s,优雅关闭完整wordpress.yaml
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: kube-example
spec:
selector:
app: wordpress
tier: frontend
ports:
- port: 80
name: web
targetPort: wdport
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
namespace: kube-example
labels:
app: wordpress
tier: frontend
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
replicas: 4 #多副本+pod的反亲合力可以实现pod的高可用
strategy: # 滚动更新的更新策略
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # 表示Kubernetes会先启动1一个新的Pod后才删掉一个旧的POD,整个升级过程中最多会有5+1个POD。
maxUnavailable: 1 # 表示Kubernetes整个升级过程中最多会有1个POD处于无法服务的状态。
minReadySeconds: 5 # 容器内应用的启动时间, pod变为run状态, 会在minReadySeconds后继续更新下一个pod.
revisionHistoryLimit: 10 # 最多保留10个升级副本,便于回滚
template:
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
containers:
- name: blog
image: wordpress:5.3.2-apache
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 800m
memory: 150Mi
requests:
cpu: 800m
memory: 150Mi
startupProbe: #首次启动探测(如果没有成功,不会运行下面livenessProbe)
httpGet:
port: 80
failureThreshold: 2 #探测成功后,最少连续探测失败多少次才被认定为失败。默认是3。最小值是1。
initialDelaySeconds: 20 # 容器启动后第一次执行探测是需要等待多少秒
timeoutSeconds: 10 # 探测超时时间。默认1秒,最小1秒。
periodSeconds: 5 # 执行探测的频率。默认是10秒,最小1秒。
readinessProbe: # (就绪检查) # 如果检查失败,kubernetes会把Pod从service endpoints中剔除
tcpSocket:
port: 80
initialDelaySeconds: 10
timeoutSeconds: 5
failureThreshold: 5
periodSeconds: 5
successThreshold: 3
lifecycle:
preStop: # 在容器被终止前的任务,用于优雅关闭应用程序
exec:
command: ["/bin/bash", "-c", "sleep 20"] #睡眠20s,优雅关闭
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- wordpress
restartPolicy: Always
再次测试

版本回滚
博客参照:https://www.ipcpu.com/2017/09/kubernetes-rolling-update/
查询升级状态、暂停和恢复
#@查询升级状况
$ kubectl rollout status deployment <deployment>
#@暂停滚动升级
$ kubectl rollout pause deployment <deployment>
#@恢复滚动升级
$ kubectl rollout resume deployment <deployment>操作都加了–record 的参数,這参数主要是告知 Kubernetes 记录此次下达的指令,所以我们可以通过以下命令来查看
[root@k8s-master1 v4]# kubectl rollout history deployment -n kube-example wordpress
deployment.apps/wordpress
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 <none>
4 <none>
5 <none>
6 <none>
这些个记录能保存多少个呢?默认是全部保存的。可以通过设置.spec.revisionHistoryLimit 来决定记录的个数,一般生产环境记录10个左右就差不多了。要不然可能会被刷屏。
minReadySeconds: 5
revisionHistoryLimit: 10可以通过以下命令,来回滚到上一个版本或者特定版本
# to previous revision
$ kubectl rollout undo deployment <deployment>
# to specific revision
$ kubectl rollout undo deployment <deployment> --to-revision=<revision>
# exmaple
$ kubectl rollout undo deployment buniess --to-revision=3问题
(1)自动扩缩容
(2)数据持久化
(3)mysql账号密码注入等
期待下个版本更加优化完美