显示器- unicode -系统- utf8 -存储设备
Unicode是一套复杂的字符编码标准,简单来说就是将人类使用的每个所谓字符与一个非负整数对应,并且保证不同的字符对应的整数一定不同。UTF-8是这个整数的编码方式,用1到4字节来表达一个整数。(来源)
unicode编码长度不是8位的整数倍,为方便使用,构造了多种传送编码方式即utf:
utf32:每字符用32位整数表示,值等于码点值。优点字符长度铳一效率高,缺点浪费存储。用的不多。
utf16:基本位平面字符用一十六位短整型表示,值等于码点值,扩展位平面分为两个部分与代理字符构成两个十六位整型。优点:大多数情况字符长度统一处理效率和存储效率都高。多数现代文本处理软件,windows,java采用utf16,但在微软资料中将其错误称为unicode。
utf16采用整数表达,因此存在字节顺序问题,称为utf16be和utfle.utf32也有同样的情况。
utf8:用变长编码将码点转为一到四字节的字节序列,避免了字节序问题。由干此种编码方式可表明每个字节的类型和在字符中的位置,而可检测传送过程中发生的丢掉字节问题,具有容错能力。一般在网络传送中应用很多。XML文件默认编码就是utf8。utf8码流中没有内容为0的字节,因此一些处理ascii码串的c函数可继续使用,但可能返回与其含义不同的结果。(来源)
《Windows程序设计》里面提到的unicode其实是指UCS-2,是unicode的一个最常用的子集,已经包含了很多要用到的世界各地的字符,用16位就是2个字节代表一个字符(来源)
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:(来源)
一、ASCII 码
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
二、非 ASCII 编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的。
三. Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
四、Unicode 的问题
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
五、UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
六、Unicode 与 UTF-8 之间的转换
通过上一节的例子,可以看到严的 Unicode码 是4E25,UTF-8 编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
Windows平台,有一个最简单的转化方法,就是使用内置的记事本小程序notepad.exe。打开文件后,点击文件菜单中的另存为命令,会跳出一个对话框,在最底部有一个编码的下拉条。

里面有四个选项:ANSI,Unicode,Unicode big endian和UTF-8。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对 Windows 简体中文版,如果是繁体中文版会采用 Big5 码)。
2)Unicode编码这里指的是notepad.exe使用的 UCS-2 编码方式,即直接用两个字节存入字符的 Unicode 码,这个选项用的 little endian 格式。
3)Unicode big endian编码与上一个选项相对应。我在下一节会解释 little endian 和 big endian 的涵义。
4)UTF-8编码,也就是上一节谈到的编码方法。
选择完"编码方式"后,点击"保存"按钮,文件的编码方式就立刻转换好了。
七、Little endian 和 Big endian
上一节已经提到,UCS-2 格式可以存储 Unicode 码(码点不超过0xFFFF)。以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
八、实例
下面,举一个实例。
打开"记事本"程序notepad.exe,新建一个文本文件,内容就是一个严字,依次采用ANSI,Unicode,Unicode big endian和UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit 中的"十六进制功能",观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节D1 CF,这正是严的 GB2312 编码,这也暗示 GB2312 是采用大头方式存储的。
2)Unicode:编码是四个字节FF FE 25 4E,其中FF FE表明是小头方式存储,真正的编码是4E25。
3)Unicode big endian:编码是四个字节FE FF 4E 25,其中FE FF表明是大头方式存储。
4)UTF-8:编码是六个字节EF BB BF E4 B8 A5,前三个字节EF BB BF表示这是UTF-8编码,后三个E4B8A5就是严的具体编码,它的存储顺序与编码顺序是一致的。
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
1. 前言
编码、解码、乱码、Unicode、UCS-2、UCS-4、UTF-8、UTF-16、Big Endian、Little Endian、GBK这些名词,如果你有一个不太清楚,那么建议看看本文。
2. 一幅图说尽Java编码问题
2.1 一幅图与四个概念
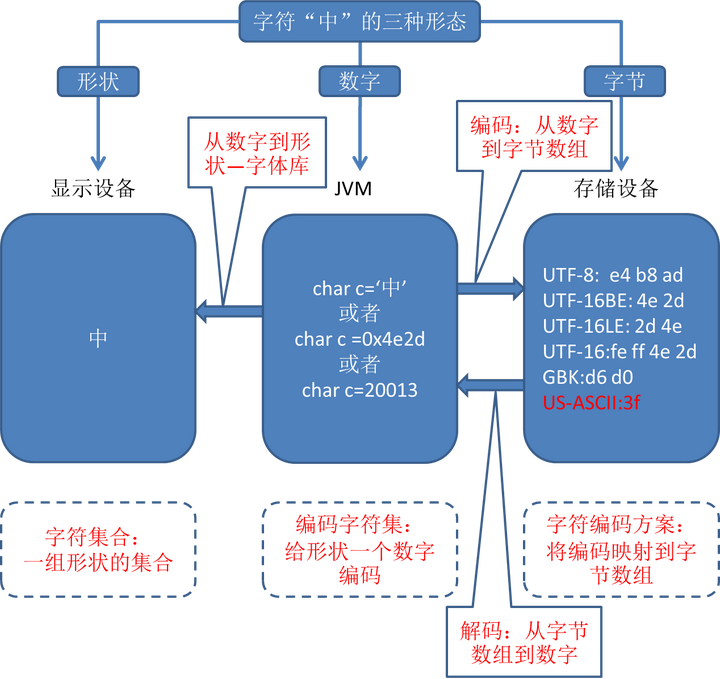
字符有三种形态:形状(显示在显示设备上)、数字(运行于JVM中,Java统一为unicode编码)和字节数组(不同的字符集有不同的映射方案)。
如此就可以明白四个重要的实体概念了(这四个概念来自于《Java NIO》一书):
字符集合(Character set):是一组形状的集合,例如所有汉字的集合,发明于公元前,发明者是仓颉。它体现了字符的“形状”,它与计算机、编码等无关。
编码字符集(Coded character set):是一组字符对应的编码(即数字),为字符集合中的每一个字符给予一个数字。例如最早的编码字符集ASCII,发明于1967年。再例如Java使用的unicode,发明于1994年(持续更新中)。由于编码字符集为每一个字符赋予一个数字,因此在java内部,字符可以认为就是一个16位的数字,因此以下方式都可以给字符赋值:
char c=‘中’
char c =0x4e2d
char c=20013
字符编码方案(Character-encoding schema):将字符编码(数字)映射到一个字节数组的方案,因为在磁盘里,所有信息都是以字节的方式存储的。因此Java的16位字符必须转换为一个字节数组才能够存储。例如UTF-8字符编码方案,它可以将一个字符转换为1、2、3或者4个字节。
一般认为,编码字符集和字符编码方案合起来被称之为字符集(Charset),这是一个术语,要和前面的字符集合(Character set)区分开。
2.2 转换的类型
2.2.1. 从数字到形状—字体库
从JVM中的字符编码,到屏幕上显示的形状。这个转换是在字体库的帮助下完成的。例如windows默认的一些汉字字体,在Java中运行时是一个个的数字编码,例如0x4e2d,通过查找字体库,得到一个形状“中”,然后显示在屏幕上。
2.2.2. 从数字到字节数组—编码
从JVM中的编码,到字节数组,这个转换被称之为编码。转换的目的是为了存储,或者发送信息。
同一个数字,例如0x4e2d,采用不同的字符集进行编码,能得到不同的字节数组。如图中所见。
至于具体的UTF-8、GBK、UTF-16等字符集的历史渊源,具体转换方式都有很多的资料可以查询。
编码的例子代码如下:
第一种方法,使用String的getBytes方法:
private static byte[] encoding1(String str, String charset) throws UnsupportedEncodingException {
return str.getBytes(charset);
}
第二种方法,使用Charset的encode方法:
private static byte[] encoding2(String str, String charset) {
Charset cset = Charset.forName(charset);
ByteBuffer byteBuffer = cset.encode(str);
byte[] bytes = new byte[byteBuffer.remaining()];
byteBuffer.get(bytes);
return bytes;
}
注意:Charset、ByteBuffer以及后文中提到的CharBuffer类都是Java NIO包中的类,具体使用方法可参考《Java NIO》一书。
2.2.3. 从字节数组到数字—解码
从一个字节数组,到一个代表字符的数字,这个转换被称之为解码。解码一般是将从磁盘或者网络上得到的信息,转换为字符或字符串。
注意解码时一定要指定字符集,否则将会使用默认的字符集进行解码。如果使用了错误的字符集,则会出现乱码。
解码的例子代码如下:
第一种方法,使用String的构造函数:
private static String decoding1(byte[] bytes,String charset) throws UnsupportedEncodingException {
String str = new String(bytes, charset);
return str;
}
第二种方法,使用Charset的decode方法:
private static String decoding2(byte[] bytes, String charset) {
Charset cset = Charset.forName(charset);
ByteBuffer buffer = ByteBuffer.wrap(bytes);
CharBuffer charBuffer = cset.decode(buffer);
return charBuffer.toString();
}
2.3 默认的字符集
乱码问题都是因为在编码或者解码时使用了错误的字符集导致的。如果不能明白什么是默认的字符集,则很有可能导致乱码。
Java的默认字符集,可以在两个地方设定,一是执行java程序时使用-Dfile.encoding参数指定,例如-Dfile.encoding=UTF-8就指定默认字符集是UTF-8。二是在程序执行时使用Properties进行指定,如下:
private static void setEncoding(String charset) {
Properties properties = System.getProperties();
properties.put("file.encoding",charset);
System.out.println(properties.get("file.encoding"));
}
注意,这两种方法如果同时使用,则程序开始时使用参数指定的字符集,在Properties方法后使用Properties指定的字符集。
如果这两种方法都没有使用,则使用操作系统默认的字符集。例如中文版windows 7的默认字符集是GBK。
默认字符集的优先级如下:
1.程序执行时使用Properties指定的字符集;
2.java命令的-Dfile.encoding参数指定的字符集;
3.操作系统默认的字符集;
4.JDK中默认的字符集,我跟踪了JDK1.8的源代码,发现其默认字符集指定为ISO-8859-1。
2.3.1. JDK支持的字符集
Charset类提供了一个方法可以列出当前JDK所支持的所有字符集,代码如下:
private static void printAvailableCharsets() {
Map<String ,Charset> map = Charset.availableCharsets();
System.out.println("the available Charsets supported by jdk:"+map.size());
for (Map.Entry<String, Charset> entry :
map.entrySet()) {
System.out.println(entry.getKey());
}
}
本测试机使用的JDK为1.8,列出的字符集多达169个。
3. 乱码
3.1 如何产生乱码
从上述章节可知,字符的形态有三种,分别是“形状”、“数字”和“字节”。字符的三种形态之间的转换也有三类:从数字到形状,从数字到字节(编码),从字节到数字(解码)。
从数字到形状不会产生乱码,乱码就产生在编码和解码的时候。仔细想来,编码也是不会产生乱码的,因为从数字到字节(指定某个字符集)一定能够转换成功,即使某字符集中不包含该数字,它也会用指定的字节来代替,并在转换时给出指示。
如此一来,乱码只会产生在解码时:例如使用某字符集A编码的字节,使用字符集B来进行解码,而A和B并不兼容。这样一来,解码产生的数字(字符编码)就是错误的,那么它显示出来也是错误的,典型的乱码例子如下(使用UTF-8编码,使用GBK解码):
private static void generateGrabledCode() throws UnsupportedEncodingException {
String str = "中国";
byte[] bytes = str.getBytes("UTF-8");
str = new String(bytes, "GBK");
System.out.println(str);
}
4. 再论Unicode、UTF和GBK
弄清楚了以上的概念和例子,再来看unicode、UCS-2、UCS-4、UTF-8、UTF-16、Big Endian、Little Endian、GBK这些名词就有了辨别的好方法了。
再复习一遍概念:
字符集合(Character set):是一组形状的集合,一般存储于字库中。
编码字符集(Coded character set):是一组字符对应的编码(即数字),为字符集合中的每一个字符给予一个数字。
字符编码方案(Character-encoding schema):将字符编码(数字)映射到一个字节数组的方案。
字符集(Charset):是编码字符集和字符编码方案的组合。
4.1 Unicode是一个编码字符集
Unicode的全称是“Universal Multiple-Octet Coded Character Set”,通用多字节编码字符集,简写为UCS。
因此我们知道:Unicode规定了一组字符对应的编码。恰好这组字符就是全人类目前所有的字符。
那么UCS-2和UCS-4是什么意思?UCS-2是指用两个字节对应一个字符的编码字符集;UCS-4则是指用四个字节对应一个字符的编码字符集。你可以认为,目前为止Unicode有两个具体的编码字符集,UCS-2和UCS-4。
Java使用的是UCS-2,即我们前面提到的,一个字符由一个16位的二进制数(2个字节)表示。
4.2 UTF是字符编码方案
看过很多文章,往往混淆Unicode和UTF,说不清它们之间的区别,用本文的概念很容易就解释清楚了。
Unicode是某种编码字符集(目前包括UCS-2和UCS-4两种),而UTF则是字符编码方案,就是将字符编码(数字)映射到一个字节数组的方案。UTF中的U是指Unicode,也就是将Unicode编码映射到字节数组的方案。目前UTF包括UTF-7、UTF-8、UTF-16和UTF-32,后面的数字代表转换时最小的位数。例如UTF-8就是用几个8位二进制数来代表一个Unicode编码。而UTF-15就是用几个16位二进制数来代表一个Unicode编码。
4.3 Big Endian和Little Endian是字节序
字节序就是数据在内存中存放的顺序,多于一个字节的数据在内存中存放时有两种选择,即Big Endian和Little Endian。
Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
Big Endian和Little Endian和芯片类型以及操作系统都有关系。但是由于Java是平台无关的,所以Java被设计为Big Endian的。但是当Java中的字符进行编码时,就要注意其字节序了。
例如UTF-16字符编码方案就分为UTF-16BE和UTF-16LE。
4.4 GBK是一个字符集
GBK同时包含编码字符集和字符编码方案。GBK编码了目前使用的大多数汉字(编码字符集),它将每一个汉字映射为两个字节,对于英文和数字,它则使用与ASCII相同的一个字节编码(字符编码方案)。
5. 小结
编码、解码和乱码问题,永远是程序员的梦魇。看懂一幅图,弄明白四个概念,也许有助于一劳永逸的解决此问题。