一、配置
IKAnalyzer 中文分词器配置,简单,超简单。
IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误。
给出我配置成功的版本IK Analyzer 2012FF_hf1(包含源码和中文使用手册),我的solr是4.7的,当然相应的Lucene也是4.7的,链接地址:
http://code.google.com/p/ik-analyzer/downloads/detail?name=IK%20Analyzer%202012FF_hf1.zip&can=2&q= 谷歌,不过貌似已经不能下载了,国内封杀了谷歌,tmd真蛋疼。
http://down.51cto.com/data/894638 51CTO上面的,有账号有积分的支持一下吧,我也是从人家那里下载的。
百度网盘,我自己共享的,时间久了就不一定还存在。链接:http://pan.baidu.com/s/1bngYiKZ 密码:g7dp
废话少说,下载后文件夹里至少有IKAnalyzer.cfg.xml、IKAnalyzer2012FF_u1.jar、stopword.dic,只需要配置这三个东西。
把IKAnalyzer2012FF_u1.jar拷贝到Tomcat的安装目录,我的是C:apache-tomcat-8.0.8webappssolrWEB-INFlib,把IKAnalyzer.cfg.xml、stopword.dic拷贝到C:apache-tomcat-8.0.8webappssolrWEB-INFclasses,classes目录没有的话自行创建。
现在IKAnalyzer 中文分词器已经配置好了,是不是超简单,不要把目录搞错了就可以了。
二、使用
现在说使用,在你的scheme.xml配置(不清楚什么是scheme.xml,请移步到上一篇博客看看)文件找到<types></types>在中间加入
<!--IKAnalyzer分词器-->
<fieldType name="text_IKFENCHI" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
然后在<fields>节点下增加一个节点:
<field name="PRODUCTNAME" type="text_IKFENCHI" indexed="true" stored="true"/>
注意field节点type里面的内容就是上面配置的fieldType,上面当于定义一个类,下面相当于用这个类定义一个变量。
这时你的PRODUCTNAME域就是通过IKAnalyzer分词器分词器进行分词的了。
现在我们来solr客户端界面测试一下分词器。重启一下Tomcat服务,打开http://localhost:8080/solr/#/
在这里找到我们的core,这里是可以配置多个core的,怎么配置后面再说,其实非常简单。这个core我也不知道叫什么(内核?核心?),但可以打个比方,比如你做电商搜索系统,你可以搜索商品,可以搜索店铺,那么你可以配置两个core,分别对应商品和店铺,这样你可以在不同的core下的配置文件里配置不同的field等,这是我暂时这样理解,有错误帮忙指正一下。这个不理解不要紧,后面我还有一系列的博客会说清楚。
这里默认是有一个叫collection1的,如果你刚才分词器配错了,这里可能就什么都没有了哦,这时可以看一下Logging是不是有错误日志,找到后点击下面的Analysis,在下拉框找到刚才配置的PRODUCTNAME

其实认真观察的话,会发现这个下拉框里面是有分类的,分成了Fields和Types,这个PRODUCTNAME在Fields节点下,还可以找到text_IKFENCHI在Types下,其实就是对应刚才配置的scheme.xml,选择其中一个都可以进行分词测试,我们可以在Field Value文本框里面输入一段话,点击Anayse Values按钮,就会显示分词结果。
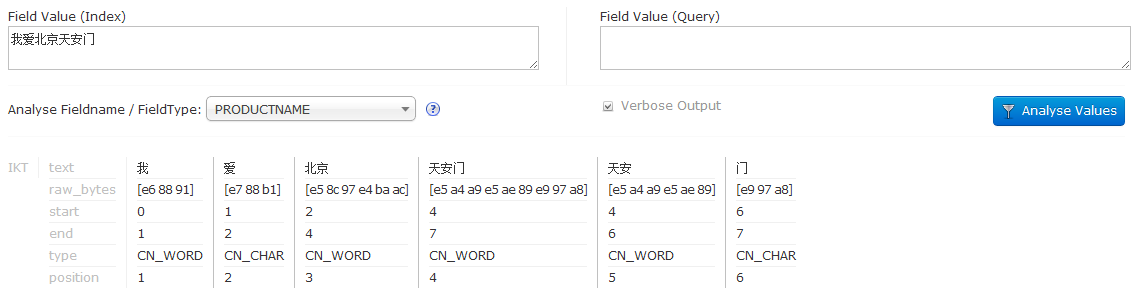
至于分出的结果是什么意思,可以自行深入研究吧,后面如果我学到了再补充。