Shared Pool 原理
Robinson
由于shared pool中最重要的是library cache,所以本文主要讲解Library cache的结构,library cache latch,library cache lock,library cache pin。
What is shared pool?
Shared pool是SGA中的一部分,由于它是SGA的一部分,这意味着它可以被所有的进程所访问,Shared Pool当中主要包含了2部分:library cache和
dictionary cache 也称为 row cache。
Library cache包含了共享SQL区(shared SQL areas),私有SQL区(private SQLareas,如果配置了共享服务器),PL/SQL存储过程以及包,还有一些控制信息,比如说locks以及library cache handles。
Dictionary cache包含了表,视图的依赖信息,比如表结构,它的用户,Oracle在解析SQL的时候就会频繁的访问dictionary cache。
How is it managed?
Shared pool和PGA都是由一个Oracle的内存管理器来管理,我们称之为KGH heap manager。Heap Manager不是一个进程,而是一串代码。Heap Manager主要目的就是满足server 进程请求memory 的时候分配内存或者释放内存。Heap Manager在管理PGA的时候,Heap Manager需要和操作系统来打交道来分配或者回收内存。但是呢,在shared pool中,内存是预先分配的,Heap Manager管理所有的空闲内存。当某个进程需要分配shared pool的内存的时候,Heap Manager就满足该请求,Heap Manager也和其他ORACLE模块一起工作来回收shared pool的空闲内存。
Library Cache Manager
Library cache Manager 可以看做是Heap Manager的客户端,因为library cache manager是根据Heap Manager来分配内存从而存放library cache objects。Library cache Manager控制所有的library cache object,包括package/procedure, cursor, trigger等等。
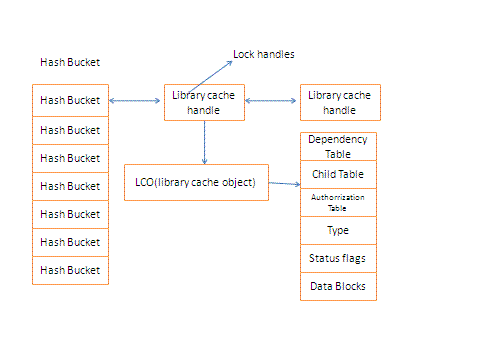
Hash Table and Hash Bucket
Library cache是由一个hash table组成,这个hash table又由hash bucket组成的数组构成,每个hash bucket又是由一些相互指向的library cache handle所组成,library cache object handle就指向具体的library cache object以及一些引用列表。
Library Cache结构示意图如下:
Library Cache handle
我们对Library cache中所有对象的访问是通过利用library cache handle来实现的,也就是说我们想要访问library cache object,我们必须先找到library cache handle。Library cache handle指向library cache object,它包含了library object的名字,命名空间,时间戳,引用列表,lock对象以及pin对象的列表信息等等。Library cache handle也被library cache用来记录哪个用户在这个这个handle上有lock,或者是哪个用户正在等待获得这个lock。那么这里我们也知道了library cache lock是发生在handle上的。
当一个进程请求library cache object, library cache manager就会应用一个hash 算法,从而得到一个hash 值,根据相应的hash值到相应的hash bucket中去寻找。这里的hash算法原理与buffer cache中快速定位block的原理是一样的。如果library cache object在内存中,那么这个library cache handle就会被找到。有时候,当shared pool不够大,library cache handle会保留在内存中,然而library cache heap由于内存不足被age out,这个时候我们请求的object heap就会被重载。最坏的情况下,library cache handle在内存中没有找到,这个时候就必须分配一个新的library cache handle,同时object heap也会被加载到内存中。
Library Cache Object
Library Cache Object是由一些独立的heap所组成,前面说了Library cache handle指向Library cache Object,其实handle是指向第一个heap,这个heap 我们就称之为heap 0。Heap 0记录了指向其他heap的指针信息。

根据上面描述,Library cache中的的Library cache object结构示意图可以用上图来表示(本图摘自DSI405)
Library cache lock/pin
Library cache lock/pin是用来控制对library cache object的并发访问的。Lock管理并发,pin管理一致性,lock是针对于library cache handle,而pin是针对于heap。
当我们想要访问某个library cache object,我们首先要获得这个指向这个object的handle的lock,获得这个lock之后我们就需要pin住指向这个object的heap。
当我们对包,存储过程,函数,视图进行编译的时候,Oracle就会在这些对象的handle上面首先获得一个library cache lock,然后再在这些对象的heap上获得pin,这样就能保证在编译的时候其它进程不会来更改这些对象的定义,或者将对象删除。
当一个session对SQL语句进行硬解析的时候,这个session就必须获得library cache lock,这样其他session就不能够访问或者更改这个SQL所引用的对象。如果这个等待事件花了很长时间,通常表明共享池太小(由于共享池太小,需要搜索free的chunk,或者将某些可以被移出的object page out,这样要花很长时间),当然了,也有可能另外的session正在对object进行修改(比如split 分区),而当前session需要引用那个table,那么这种情况下我们必须等另外的session进行完毕。
Library Cache lock有3中模式:
l Share(S): 当读取一个library cache object的时候获得
l Exclusive(X): 当创建/修改一个library cache object的时候获得
l Null(N): 用来确保对象依赖性
比如一个进程想要编译某个视图,那么就会获得一个共享锁,如果我们要create/drop/alter某个对象,那么就会获得exclusive lock。Null锁非常特殊,我们在任何可以执行的对象(cursor,function)上面都拥有NULL锁,我们可以随时打破这个NULL锁,当这个NULL锁被打破了,就表示这个对象被更改了,需要从新编译。NULL锁主要的目的就是标记某个对象是否有效。比如一个SQL语句在解析的时候获得了NULL 锁,如果这个SQL的对象一直在共享池中,那么这个NULL锁就会一直存在下去,当这个SQL语句所引用的表被修改之后,这个NULL锁就被打破了,因为修改这个SQL语句的时候会获得Exclusive 锁,
由于NULL锁被打破了,下次执行这个SQL的时候就需要从新编译。
Library Cache pin有2种模式:
l Share(S): 读取object heap
l Exclusive(X):修改object heap
Library Cache pin没有什么好说的,当某个session想要读取object heap,就需要获得一个共享模式的pin,当某个session想要修改object heap,就需要获得排他的pin。当然了在获得pin之前必须获得lock。
下面就是一个在Oracle10g RAC环境中的Library cache lock的案例
这个RAC环境有2个节点
SQL> select inst_id from gv$instance;
INST_ID
----------
2
1
在第一个节点中,session 4538被library cache lock阻塞
SQL> select inst_id,sid,serial#,event ,p1raw,machine,status from gv$session where username='BX5685';
INST_ID SID SERIAL# EVENT P1RAW MACHINE STATUS
---------- ---------- ---------- ------------------------ ------------ --------
1 4538 39833 library cache lock C000000346FBA458 bdhp4462 ACTIVE
在Node1上面查询
SQL> select * from dba_kgllock where kgllkreq > 0;
KGLLKUSE KGLLKHDL KGLLKMOD KGLLKREQ KGLLKTYPE
---------------- ---------------- ---------- ---------- ------------
C0000004789EF9D0 C000000346FBA458 0 2 Lock
SQL> select kglnaown, kglnaobj from x$kglob where kglhdadr = 'C000000346FBA458';
KGLNAOWN KGLNAOBJ
-------------------- --------------------
IDWSU1 PROD_ASSOC_DNORM
SQL> select kglhdadr, kglnaown, kglnaobj from x$kglob where kglnaobj = 'PROD_ASSOC_DNORM' and KGLNAOWN='IDWSU1';
KGLHDADR KGLNAOWN KGLNAOBJ
---------------- -------------------- --------------------
C000000346FBA458 IDWSU1 PROD_ASSOC_DNORM
在Node2上面查询
SQL> select kglhdadr, kglnaown, kglnaobj from x$kglob where kglnaobj = 'PROD_ASSOC_DNORM' and KGLNAOWN='IDWSU1';
KGLHDADR KGLNAOWN KGLNAOBJ
------------------------------ -------------------- ------------------------------
C000000443267070 IDWSU1 PROD_ASSOC_DNORM
C00000035C33E248 IDWSU1 PROD_ASSOC_DNORM
SQL> col event format a30
select sid, serial#,s.event, sql_text from dba_kgllock w, v$session s, v$sqlarea a
where w.kgllkuse = s.saddr and w.kgllkhdl='C000000443267070'
and s.sql_address = a.address
and s.sql_hash_value = a.hash_value;SQL> 2 3 4
SID SERIAL# EVENT SQL_TEXT
---------- ---------- ------------------------------
4774 36583 db file scattered read ALTER TABLE PROD_ASSOC_DNORM ENABLE CONSTRAINT PROD_ASSOC_DNORM_PK USING INDEX STORAGE ( INITIAL 4194304 NEXT 4194304 PCTINCREASE 0 ) TABLESPACE CDW_REFERENCE01M LOCAL
在Oracle10gR2中,library cache pin被library cache mutex 所取代
Library cache Latch
Library cache latch用来控制对library cache object的并发访问。前面已经提到,我们要访问library cache object之前必须获得library cache lock, lock不是一个原子操作(原子操作就是在操作程中不会被打破的操作,很明显这里的lock可以被打破),Oracle为了保护这个lock,引入了library cache latch机制,也就是说在获得library cache lock之前,需要先获得library cache latch,当获得library cache lock之后就释放library cache latch。
如果某个library cache object没有在内存中,那么这个lock就不能被获取,这个时候需要获得一个library cache load lock latch,然后再获取一个library cache load lock,当load lock获得之后就释放library cache load lock latch。
我们来看一下在 Oracle10gR2 中的一个有关library cache latch,
library cache lock, library cache pin 的统计情况
SQL> select name,gets,misses,sleeps from v$latch where name like '%library%';
NAME GETS MISSES SLEEPS
------------------------------ ---------- ---------- ----------
library cache 1937415298 5513866 2346346
library cache lock 734620587 425030 3021
library cache pin 171326029 108613 868
library cache pin allocation 2930490 35 1
library cache lock allocation 5226147 349 2
library cache load lock 720252 1762 34
library cache hash chains 0 0 0
library cache latch受隐含参数_KGL_LATCH_COUNT的控制,默认值为大于等于系统中CPU个数的最小素数,但是Oracle对其有一个硬性限制,该参数不能大于67。注意:我们去查询_kgl_latch_count有时候显示为0,这是一个bug。
那么library cache object handle是由哪个子latch来保护的呢?Oracle利用下面算法来确定:
latch# = mod(bucket#, #latches)(摘自DSI405)
也就是说用哪个子latch去保护某个handle是根据那个handle所在的bucket号,以及总共有多少个子latch来进行hash运算得到的,对此我们不必深究。
latch contention
根据前面的讲解,存在大量硬解析的系统上面就必然引发library cache latch, library cache lock竞争,下面就是一个每秒高达74个硬解析所引发
Library cache lock 成为Top wait event的一个案例。
Load Profile
|
Per Second |
Per Transaction |
|
|
Redo size: |
832,040.22 |
10,738.95 |
|
Logical reads: |
56,114.37 |
724.26 |
|
Block changes: |
5,897.48 |
76.12 |
|
Physical reads: |
3,442.07 |
44.43 |
|
Physical writes: |
174.41 |
2.25 |
|
User calls: |
273.48 |
3.53 |
|
Parses: |
82.02 |
1.06 |
|
Hard parses: |
74.53 |
0.96 |
|
Sorts: |
121.00 |
1.56 |
|
Logons: |
0.09 |
0.00 |
|
Executes: |
160.67 |
2.07 |
|
Transactions: |
77.48 |
|
Top 5 Timed Events
|
Event |
Waits |
Time(s) |
Avg Wait(ms) |
% Total Call Time |
Wait Class |
|
library cache lock |
3,603 |
10,588 |
2,939 |
51.7 |
Concurrency |
|
CPU time |
|
7,059 |
|
34.5 |
|
|
db file sequential read |
1,454,620 |
1,932 |
1 |
9.4 |
User I/O |
|
db file scattered read |
863,507 |
1,178 |
1 |
5.7 |
User I/O |
|
log file parallel write |
269,164 |
260 |
1 |
1.3 |
System I/O |
如果shared pool过小,也会引发library cache latch竞争,与此同时还会伴随shared pool latch竞争。下面就是一个由于shared pool过小,导致library cache latch成为top wait event的案例
Load Profile
|
Per Second |
Per Transaction |
|
|
Redo size: |
81,060.24 |
32,559.33 |
|
Logical reads: |
11,204.65 |
4,500.55 |
|
Block changes: |
414.99 |
166.69 |
|
Physical reads: |
0.50 |
0.20 |
|
Physical writes: |
5.62 |
2.26 |
|
User calls: |
189.05 |
75.93 |
|
Parses: |
38.51 |
15.47 |
|
Hard parses: |
3.58 |
1.44 |
|
Sorts: |
24.27 |
9.75 |
|
Logons: |
0.02 |
0.01 |
|
Executes: |
85.29 |
34.26 |
|
Transactions: |
2.49 |
|
Top 5 Timed Events
|
Event |
Waits |
Time(s) |
Avg Wait(ms) |
% Total Call Time |
Wait Class |
|
CPU time |
|
6,663 |
|
61.0 |
|
|
latch: library cache |
1,306 |
157 |
120 |
1.4 |
Concurrency |
|
latch: shared pool |
5,527 |
152 |
28 |
1.4 |
Concurrency |
|
log file parallel write |
81,192 |
122 |
2 |
1.1 |
System I/O |
|
log file sync |
74,187 |
120 |
2 |
1.1 |
Commit |
Shared Pool Advisory
- SP: Shared Pool Est LC: Estimated Library Cache Factr: Factor
- Note there is often a 1:Many correlation between a single logical object in the Library Cache, and the physical number of memory objects associated with it. Therefore comparing the number of Lib Cache objects (e.g. in v$librarycache), with the number of Lib Cache Memory Objects is invalid.
|
Shared Pool Size(M) |
SP Size Factr |
Est LC Size (M) |
Est LC Mem Obj |
Est LC Time Saved (s) |
Est LC Time Saved Factr |
Est LC Load Time (s) |
Est LC Load Time Factr |
Est LC Mem Obj Hits |
|
352 |
0.38 |
115 |
15,602 |
547,132 |
0.88 |
82,833 |
7.60 |
13,561,473 |
|
448 |
0.48 |
210 |
20,206 |
559,218 |
0.90 |
70,747 |
6.49 |
13,681,539 |
|
544 |
0.59 |
304 |
25,430 |
564,732 |
0.91 |
65,233 |
5.99 |
13,732,206 |
|
640 |
0.69 |
397 |
29,804 |
585,824 |
0.95 |
44,141 |
4.05 |
13,761,147 |
|
736 |
0.79 |
492 |
31,706 |
606,741 |
0.98 |
23,224 |
2.13 |
13,779,369 |
|
832 |
0.90 |
587 |
33,581 |
614,849 |
0.99 |
15,116 |
1.39 |
13,791,238 |
|
928 |
1.00 |
682 |
35,624 |
619,069 |
1.00 |
10,896 |
1.00 |
13,795,452 |
|
1,024 |
1.10 |
777 |
37,928 |
621,113 |
1.00 |
8,852 |
0.81 |
13,798,083 |
|
1,120 |
1.21 |
872 |
40,162 |
623,021 |
1.01 |
6,944 |
0.64 |
13,799,705 |
|
1,216 |
1.31 |
967 |
42,895 |
624,574 |
1.01 |
5,391 |
0.49 |
13,800,847 |
|
1,312 |
1.41 |
1,062 |
45,835 |
626,304 |
1.01 |
3,661 |
0.34 |
13,801,787 |
|
1,408 |
1.52 |
1,157 |
48,677 |
627,737 |
1.01 |
2,228 |
0.20 |
13,802,717 |
|
1,504 |
1.62 |
1,252 |
52,032 |
636,469 |
1.03 |
1 |
0.00 |
13,803,727 |
|
1,600 |
1.72 |
1,347 |
56,719 |
637,734 |
1.03 |
1 |
0.00 |
13,804,715 |
|
1,696 |
1.83 |
1,442 |
60,885 |
638,457 |
1.03 |
1 |
0.00 |
13,805,622 |
|
1,792 |
1.93 |
1,537 |
63,993 |
638,640 |
1.03 |
1 |
0.00 |
13,806,647 |
|
1,888 |
2.03 |
1,632 |
66,977 |
638,660 |
1.03 |
1 |
0.00 |
13,807,680 |
Library Cache Activity
- "Pct Misses" should be very low
|
Namespace |
Get Requests |
Pct Miss |
Pin Requests |
Pct Miss |
Reloads |
Invali- dations |
|
BODY |
5,545 |
0.20 |
7,806 |
0.40 |
20 |
0 |
|
CLUSTER |
91 |
4.40 |
155 |
3.23 |
1 |
0 |
|
INDEX |
75 |
25.33 |
140 |
34.29 |
29 |
0 |
|
SQL AREA |
660,357 |
26.67 |
3,184,169 |
9.38 |
8,452 |
120 |
|
TABLE/PROCEDURE |
20,169 |
2.45 |
965,511 |
0.30 |
1,268 |
0 |
|
TRIGGER |
202 |
0.00 |
1,472 |
0.20 |
3 |
0 |
我是怎么判断shared pool过小的呢?AWR里面提供了多个指标,这里硬解析不是太高,每秒3个,说明硬解析不会导致该问题,shared pool advice已经说得很明白了,当前shared pool只有928m,Oracle建议把shared pool至少调整到1504m。同时查看 Library cache activtiy,大家注意观察pct miss,SQL AREA的pct miss居然达到26.67%,而且重载了8452次,那么我完全可以肯定就是由于shared pool太小,导致SQL被大量重载,从而引发library cache latch竞争。
Library cache latch竞争还有可能是具有高version_count的SQL导致的,某个session去执行一个具有很高version_count的SQL需要pin住child cursor,而由于child cursor过多,在未pin住child cursor之前不会释放library cache latch,这样当其他session想运行该SQL的时候就会发生library cache latch争用,那么遇到这种情况请检查cursor_sharing参数的设置,另外请查询是否遇到bug,或者由于系统中不同schema出现大量同名的表名,这样请更改设计。
在第二个案例中,由于shared pool设置过小还导致了shared pool latch处于top wait event 中的第二名。Shared pool latch是用来干嘛的呢?Shared pool latch用来保护共享池的结构,在分配,释放共享池空间的时候就会获得该latch,那么在这个案例中,由于共享池太小,在对一个新的SQL进行硬解析的时候需要老化某些对象,为新对象腾出空间,那么这个释放空间的过程就需要获得shared pool latch。当然了,在进行硬解析,也需要获得一个shared pool latch因为硬解析需要申请分配shared pool空间,而分配空间的时候就需要获得该latch。