在单机模式的基础上,完成伪分布部署!
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改如下配置文件 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
1、修改core-site.xml(刚打开的时候是下面这样)
<configuration>
</configuration>将他修改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>常用配置项说明:
- fs.defaultFS这是默认的HDFS路径。当有多个HDFS集群同时工作时,用户在这里指定默认HDFS集群,该值来自于hdfs-site.xml中的配置。
- fs.default.name这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。
- hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在/tmp/hadoop-${user.name}这个路径中。
更多说明请参考core-default.xml,包含配置文件所有配置项的说明和默认值。
2、修改hdfs-site.xml(具体配置可查看官网文档)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3、修改mapred-site.xml(具体配置可查看官网文档)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration><!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>5、修改hadoop-env.sh(找到如下内容,修改)
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_171
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0/etc/hadoop
到这里,伪分布的配置就配置完成了。
在使用hadoop前,必须格式化一个全新的HDFS安装。执行下列语句完成格式化:
$ hadoop namenode -format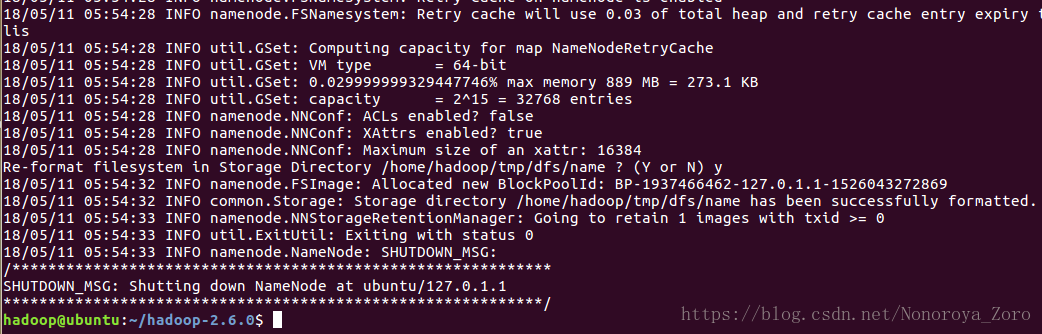
显示格式化HDFS成功。
之后便可以启动hadoop了,通过start-dfs.sh启动hdfs守护进程,分别启动namenode和datanode。

之后可以启动yarn,通过start-yarn.sh来启动resourcemanager和nodemanager,检查是否启动成功,可以打开浏览器,输入
http://localhost:8088进入resourcemanager管理页面,输入http://localhost:50070进入HDFS页面。
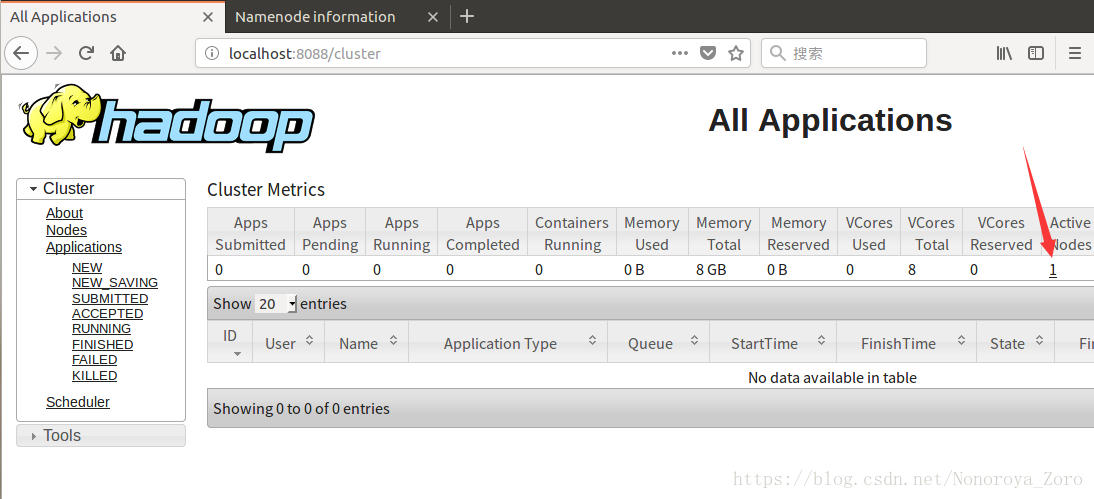
可以看到活动节点为1,就是本机。

datanode使用情况查看。
接下来还是用词频统计来验证:
先在伪分布机器上创建相关文件夹,我们需要将我们的数据文件拷贝到HDFS上去,可以使用下面命令:
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hadoop
hadoop fs -mkdir /user/hadoop/hgg
#创建多层目录
hadoop fs -mkdir -p /user/hadoop/hgg查看是否创建成功:

成功!!!
输入下面命令完成词频统计:
hadoop jar /home/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /user/hadoop/hgg hggoutput
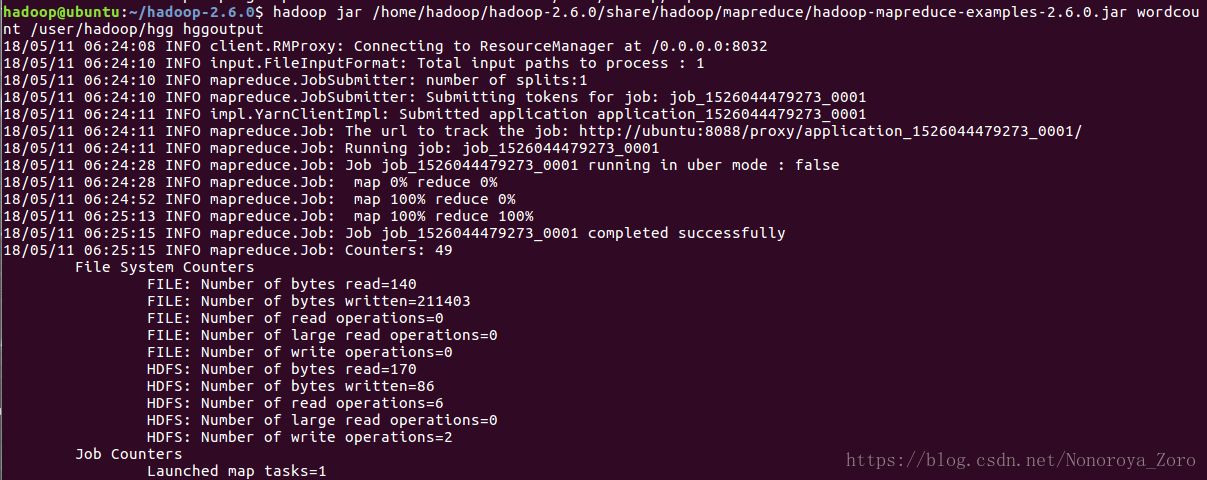
查看结果:
hadoop -cat /user/hadoop/hggoutput/*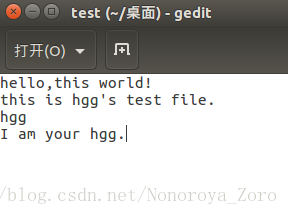

停止服务:
stop-dfs.sh
stop-yarn.sh伪分布部署完毕。
集群分布转载:(写的很详细,在这不做阐述)