这次是使用RNN来处理mnist,正常应该会自己搭建RNN模型,然后训练,最后对模型进行评估,但是keras对RNN封装的很好了,直接调用就行了。
SimpleRNN层:keras.layers.recurrent.SimpleRNN(output_dim, init='glorot_uniform', inner_init='orthogonal', activation='tanh', W_regularizer=None, U_regularizer=None, b_regularizer=None, dropout_W=0.0, dropout_U=0.0)
这是全连接RNN层,output_dim为输出层维度,现在已经改成units了;input_shape输入尺寸,不过上面没写;activation为激活函数;其他的很多属性一般情况下都不用设置,keras官方中文文档也有,所以就不写了(懒!@..@)。还有LSTM层,这次我也没用到。所以没研究。唉,没有学术精神!
第一步,惯例,导入包和设置随机种子,随机种子使得每次运行程序生成随机数那个操作结果是一样的。utils是工具包;datasets是数据包,models是模型包,还是只用到Sequential;layers是层包,SimpleRNN是层,并不是一个模型;optimizers是优化器。
import keras
import numpy as np
np.random.seed(1337)
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import SimpleRNN, Activation, Dense
from keras.optimizers import Adam
第二步,设置一些数据,其实不设置也没事,用到哪些数据,直接用数字代替也行,设置了的话修改和查看比较方便。
TIME_STEPS = 28 #等于图片高度(矩阵的行数),每次读取一行,图片大小是28*28,因此需要读取28次
INPUT_SIZE = 28 #等于图片宽度(矩阵的高数),每次读取一行中的多少个像素,一行有28个
BATCH_SIZE = 50 #每次训练50张图片
BATCH_INDEX = 0 #生成数据
OUTPUT_SIZE = 10 #输出的尺寸,每次输出是0-9的数据,所以为10个[0,1,0 0 0 0 0 0 0 0]这个形式
CELL_SIZE = 50 #RNN里面的隐藏层个数
LR = 0.001 #学习率
第三步,导入数据以及对数据进行预处理。
#数据
(x_train, y_train), (x_test, y_test) = mnist.load_data() #从库中导入数据
x_train = x_train.reshape(-1, 28, 28) / 255 #x数据需要归一化,不然数据太乱
x_test = x_test.reshape(-1, 28, 28) / 255
y_train = np_utils.to_categorical(y_train, 10) #y设成one hot数据标签
y_test = np_utils.to_categorical(y_test, 10)
第四步,建立模型
#建立模型
model = Sequential()
model.add(SimpleRNN( #直接调用封装的RNN层就可以了,就相当于已经完成了RNN模型的搭建
units=CELL_SIZE, #输出就是隐藏层个数
input_shape=(TIME_STEPS, INPUT_SIZE), #输入尺寸就是28*28
))
model.add(Dense(OUTPUT_SIZE)) #最后接一个全连接层,就OK了,最后输出尺寸为10
model.add(Activation('softmax'))
#编译
adam = Adam(LR) #设置优化器参数
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
最后进行训练和测试,这次的训练过程我是明白了,但是为什么这么训练,为什么不是直接全部训练,而是一步一步的来,我并不是很懂!
#训练
for step in range(4001): #循环4001次
#取x_train和y_train中的一部分数据
x_batch = x_train[BATCH_INDEX:BATCH_SIZE+BATCH_INDEX, :, :] #取出的尺寸为(50,28,28)
y_batch = y_train[BATCH_INDEX:BATCH_SIZE+BATCH_INDEX, :] #取出的尺寸为(50,10)
cost = model.train_on_batch(x_batch, y_batch) #一次循环拿50个数据进行训练
BATCH_INDEX += BATCH_SIZE #第一次去前50个数据,下一次就取50-100这50个数据,以此类推
BATCH_INDEX = 0 if BATCH_INDEX >= x_train.shape[0] else BATCH_INDEX #如果数据取完了,就从头开始,没有就继续接着之前的取
#测试
if step % 500 == 0:
cost, accuracy = model.evaluate(x_test, y_test, batch_size=y_test.shape[0]) #一次性拿50个测试数据进行测试
print(cost, accuracy)
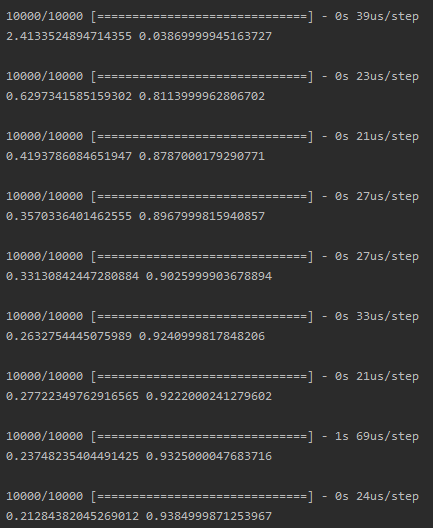
最后的训练过程如下: