这一次是通过keras对官方的手写数据集mnist进行训练,是训练出来的模型能准确分别手写数字mnist手写数据集,里面都是28*28的图片(这个图片是来自https://www.cnblogs.com/xianhan/p/9145966.html):

然后如果只是简单的这样训练模型就没什么意义了,因此每个数字都有很多不同的版本:

这些样式的,这样才有亿点点难度。
#导入一些包
import numpy as np
np.random.seed(123) #随机种子的目的就是让程序每次运行的时候生成随机数那个函数生成的数一样,但是这里
#代码好像没有生成随机数,我也是跟着写的,可能某些指令有随机操作吧
from keras.layers import Dense, Activation
from keras.models import Sequential
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import RMSprop
#下载数据到'C:UsersAdministrator.kerasdatasets'这个路劲,有的话就不用下载了
#然后数据形状就是这样,x是60000个(28x28)的手写数字图片,应该是图片,不过输出出来就是数组了,
#y就是60000个标签,标签是[0,1,2,3, ... ,9]也就是一张图片写的是什么数字
(x_train, y_train), (x_test, y_test) = mnist.load_data() #调用/下载后就赋值给左边那些式子了
#处理x数据,处理成(60000*784)最后归一化,除以255。前面介绍的时候可以看到图片样子,然后在数据里呢就#会将各个颜色转成RGB形式,
#所以输出x_train就会看到里面都是数字,范围是0-255,然后对这些数字进行处理,处理成0-1
x_train = x_train.reshape(x_train.shape[0], -1)/255
x_test = x_test.reshape(x_test.shape[0], -1)/255
#处理y,没处理前y是类似上面说的0,1,2,3,4这个样子,处理后变成[1,0,0,0,0,0,0,0,0,0]一个这样的数组,如果是0,就第一个数变为1,
# 如果是1就变成[0,1,0,0,0,0,0,0,0,0]这个样子
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
#建立模型,这个是另一种方式建立模型,另一种形式就是先model=Sequential(),然后model.add()加入每一个层就行了
model = Sequential([
Dense(32, input_dim = 784), #输出32,输入28*28 = 784
Activation('relu'),
Dense(10),
Activation('softmax'),
])
remprop = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0) #一个优化方法,用这个来找到最合适的参数,应该类似梯度下降
model.compile(optimizer=remprop, loss='categorical_crossentropy', metrics=['accuracy'],)#编译模型
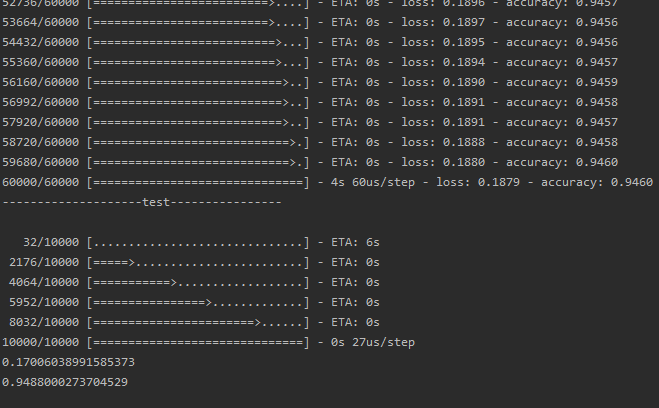
print("-------------------train---------------")
model.fit(x_train, y_train, epochs=2, batch_size=32) #训练,epochs是训练次数,batch_size就是每次取32个数进行训练
print("--------------------test----------------")
loss, accuracy = model.evaluate(x_test, y_test) #按batch_size计算误差
print(loss)
print(accuracy)
其实我自己目前还有些疑问,就比如我怎么用训练出来的模型去分辨一个数字呢?这个以后如果研究明白了再说了!最后的结果是这样,上面的是训练过程,后面的测试过程,最后输出损失和准确度: