由于有两个并行运行的处理器(CPU和GPU),会出现许多同步问题。
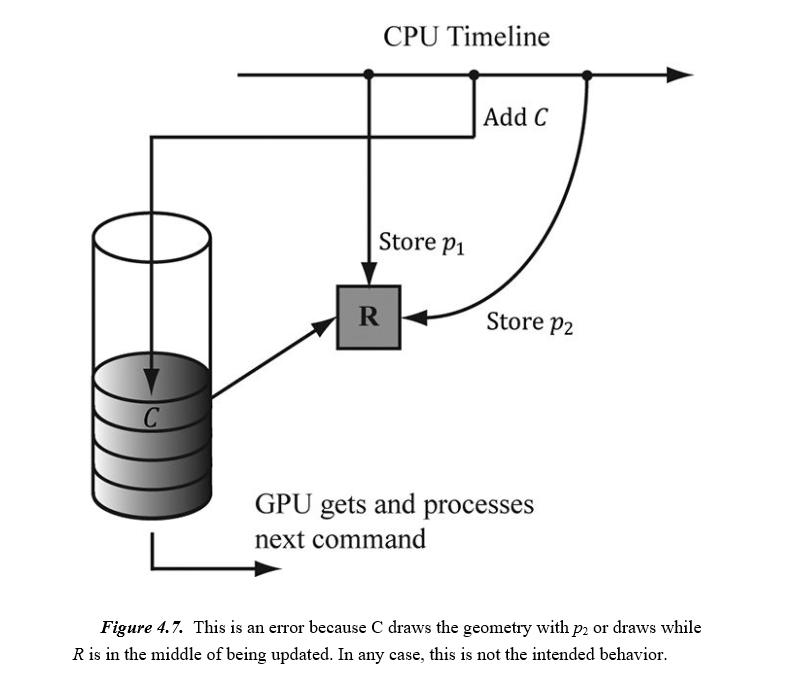
假设我们有一些资源R存储了我们希望绘制的某些几何体的位置。 此外,假设CPU更新R的数据以存储位置p1,然后将引用R的绘图命令C添加到命令队列,目的是在位置p1处绘制图形。 将命令添加到命令队列不会阻塞CPU,因此CPU会继续运行。 在GPU执行绘图命令C之前,CPU继续并覆盖R的数据以存储新位置p2将会导致错误(参见下图)。
这种情况的一种解决方案是强制CPU等待GPU完成处理队列中的所有命令直到指定的栅栏点(fence point)。 我们称之为刷新命令队列(flushing the command queue)。 我们可以使用栅栏(fence)来做到这一点。 栅栏由ID3D12Fence接口表示,用于同步GPU和CPU。 可以使用以下方法创建fence对象:
HRESULT ID3D12Device::CreateFence( UINT64 InitialValue, D3D12_FENCE_FLAGS Flags, REFIID riid, void **ppFence); // Example ThrowIfFailed(md3dDevice->CreateFence( 0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&mFence)));
fence对象维护UINT64值,该值只是一个整数,用于标识栅栏时间点。 我们从零开始,每次我们需要标记一个新的栅栏点时,我们只是递增整数。 现在,以下代码/注释显示了我们如何使用fence来刷新命令队列。
UINT64 mCurrentFence = 0; void D3DApp::FlushCommandQueue() { // Advance the fence value to mark commands up to this fence point. mCurrentFence++; // Add an instruction to the command queue to set a new fence point. // Because we are on the GPU timeline, the new fence point won’t be // set until the GPU finishes processing all the commands prior to // this Signal(). ThrowIfFailed(mCommandQueue->Signal(mFence.Get(), mCurrentFence)); // Wait until the GPU has completed commands up to this fence point. if(mFence->GetCompletedValue() < mCurrentFence) { HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS); // Fire event when GPU hits current fence. ThrowIfFailed(mFence->SetEventOnCompletion(mCurrentFence, eventHandle)); // Wait until the GPU hits current fence event is fired. WaitForSingleObject(eventHandle, INFINITE); CloseHandle(eventHandle); } }
图4.8以图形方式解释了此代码。
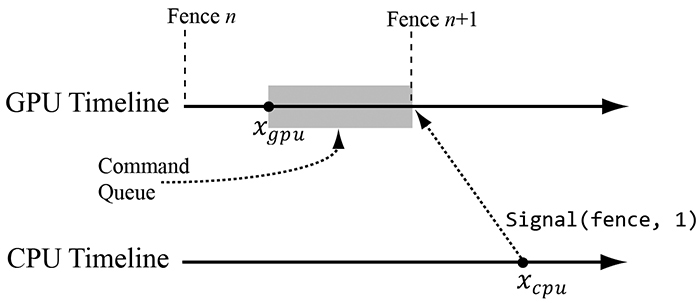
图4.8。 在这个快照中,GPU已经处理了直到xgpu之前的命令,而CPU刚刚调用了ID3D12CommandQueue :: Signal(fence,n + 1)方法。 这实质上是在队列末尾添加一条指令,将fence值更改为n + 1.但是,mFence-> GetCompletedValue()将继续返回n,直到GPU处理完队列中在Signal指令之前的所有命令。
因此在前面的示例中,在CPU发出绘图命令C之后,它将在覆盖R的数据之前刷新命令队列以存储新位置p2。 这个解决方案并不理想,因为它意味着CPU在等待GPU完成时处于空闲状态,但它提供了一个简单的解决方案,我们将在第7章之前使用它。您几乎可以在任何时候刷新命令队列(每帧不一定只有一次); 比如如果您有一些初始化GPU命令,则可以在进入主渲染循环之前刷新命令队列以执行初始化。
请注意,刷新命令队列也可用于解决我们在上一节末尾提到的问题; 也就是说,我们可以刷新命令队列,以确保在重置命令分配器之前已经执行了所有GPU命令。