索引的重要性
数据库性能优化中索引绝对是一个重量级的因素,可以说,索引使用不当,其它优化措施将毫无意义。
聚簇索引(Clustered Index)和非聚簇索引 (Non- Clustered Index)
最通俗的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关。举例来说,你翻到新华字典的汉字“爬”那一页就是P开头的部分,这就是物理存储顺序(聚簇索引);而不用你到目录,找到汉字“爬”所在的页码,然后根据页码找到这个字(非聚簇索引)。
下表给出了何时使用聚簇索引与非聚簇索引:
| 动作 | 使用聚簇索引 | 使用非聚簇索引 |
| 列经常被分组排序 | 应 | 应 |
| 返回某范围内的数据 | 应 | 不应 |
| 一个或极少不同值 | 不应 | 不应 |
| 小数目的不同值 | 应 | 不应 |
| 大数目的不同值 | 不应 | 应 |
| 频繁更新的列 | 不应 | 应 |
| 外键列 | 应 | 应 |
| 主键列 | 应 | 应 |
| 频繁修改索引列 | 不应 | 应 |
聚簇索引的唯一性
正式聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引,因为物理存储只能有一个顺序。正因为一个表最多只能有一个聚簇索引,所以它显得更为珍贵,一个表设置什么为聚簇索引对性能很关键。
初学者最大的误区:把主键自动设为聚簇索引
因为这是SQLServer的默认主键行为,你设置了主键,它就把主键设为聚簇索引,而一个表最多只能有一个聚簇索引,所以很多人就把其他索引设置为非聚簇索引。这个是最大的误区。甚至有的主键又是无意义的自动增量字段,那样的话Clustered index对效率的帮助,完全被浪费了。
刚才说到了,聚簇索引性能最好而且具有唯一性,所以非常珍贵,必须慎重设置。一般要根据这个表最常用的SQL查询方式来进行选择,某个字段作为聚簇索引,或组合聚簇索引,这个要看实际情况。
事实上,建表的时候,先需要设置主键,然后添加我们想要的聚簇索引,最后设置主键,SQLServer就会自动把主键设置为非聚簇索引(会自动根据情况选择)。如果你已经设置了主键为聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
记住我们的最终目的就是在相同结果集情况下,尽可能减少逻辑IO。
我们先从一个实际使用的简单例子开始。
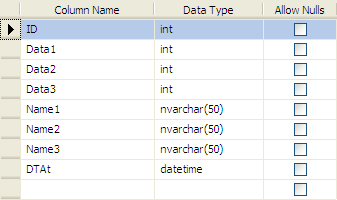
一个简单的表:
- CREATE TABLE [dbo].[Table1](
- [ID] [int] IDENTITY(1,1) NOT NULL,
- [Data1] [int] NOT NULL DEFAULT ((0)),
- [Data2] [int] NOT NULL DEFAULT ((0)),
- [Data3] [int] NOT NULL DEFAULT ((0)),
- [Name1] [nvarchar](50) NOT NULL DEFAULT (''),
- [Name2] [nvarchar](50) NOT NULL DEFAULT (''),
- [Name3] [nvarchar](50) DEFAULT (''),
- [DTAt] [datetime] NOT NULL DEFAULT (getdate())
来点测试数据(10w条):
- declare @i int
- set @i = 1
- while @i < 100000
- begin
- insert into Table1 ([Data1] ,[Data2] ,[Data3] ,[Name1],[Name2] ,[Name3])
- values(@i, 2* @i,3*@i, CAST(@i AS NVARCHAR(50)), CAST(2*@i AS NVARCHAR(50)), CAST(3*@i AS NVARCHAR(50)))
- set @i = @i + 1
- end
- update table1 set dtat= DateAdd (s, data1, dtat)
打开查询分析器的IO统计和时间统计:
- SET STATISTICS IO ON;
- SET STATISTICS TIME ON;
显示实际的“执行计划”:
我们最常用的SQL查询是这样的:
- SELECT * FROM Table1 WHERE Data1 = 2 ORDER BY DTAt DESC;
先在Table1设主键ID,系统自动为该主键建立了聚簇索引。
然后执行该语句,结果是:
- Table 'Table1'. Scan count 1, logical reads 911, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 16 ms, elapsed time = 7 ms.

然后我们在Data1和DTat字段分别建立非聚簇索引:
- CREATE NONCLUSTERED INDEX [N_Data1] ON [dbo].[Table1]
- (
- [Data1] ASC
- )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY]
- CREATE NONCLUSTERED INDEX [N_DTat] ON [dbo].[Table1]
- (
- [DTAt] ASC
- )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY]
再次执行该语句,结果是:
- Table 'Table1'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 39 ms.
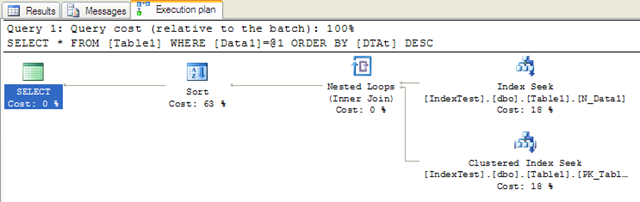
可以看到设立了索引反而没有任何性能的提升而且消耗的时间更多了,继续调整。
然后我们删除所有非聚簇索引,并删除主键,这样所有索引都删除了。建立组合索引Data1和DTAt,最后加上主键:
- CREATE CLUSTERED INDEX [C_Data1_DTat] ON [dbo].[Table1]
- (
- [Data1] ASC,
- [DTAt] ASC
- )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF) ON [PRIMARY]
再次执行语句:
- Table 'Table1'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 1 ms.
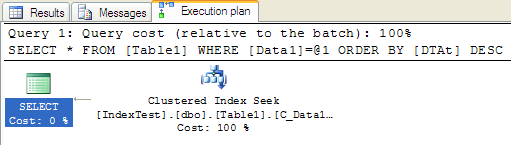
可以看到只有聚簇索引seek了,消除了index scan和nested loop,而且执行时间也只有1ms,达到了最初优化的目的。
组合索引小结
小结以上的调优实践,要注意聚簇索引的选择。首先我们要找到我们最多用到的SQL查询,像本例就是那句类似的组合条件查询的情况,这种情况最好使用组合聚簇索引,而且最多用到的字段要放在组合聚簇索引的前面,否则的话就索引就不会有好的效果,看下例: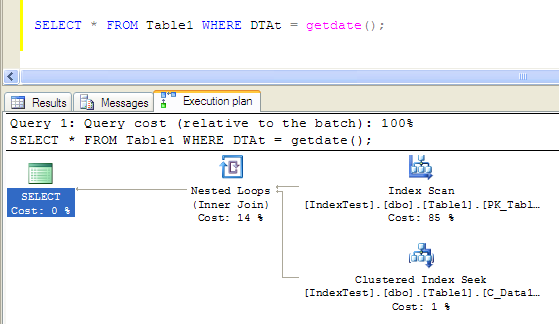
查询条件落在组合索引的第二个字段上,引起了index scan,效果很不好,执行时间是:
- Table 'Table1'. Scan count 1, logical reads 238, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 16 ms, elapsed time = 22 ms.
而如果仅查询条件是第一个字段也没有问题,因为组合索引最左前缀原则,实践如下: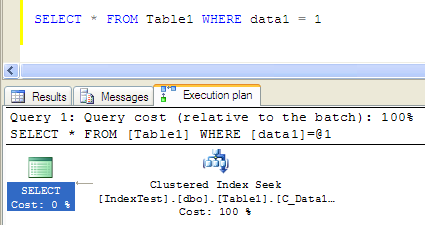
- Table 'Table1'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- SQL Server Execution Times:
- CPU time = 0 ms, elapsed time = 1 ms.
从中可以看出,最多用到的字段要放在组合聚簇索引的前面。
Index seek 为什么比 Index scan好?
索引扫描也就是遍历B树,而seek是B树查找直接定位。
Index scan多半是出现在索引列在表达式中。数据库引擎无法直接确定你要的列的值,所以只能扫描整个整个索引进行计算。index seek就要好很多.数据库引擎只需要扫描几个分支节点就可以定位到你要的记录。回过来,如果聚集索引的叶子节点就是记录,那么Clustered Index Scan就基本等同于full table scan。
一些优化原则
1、缺省情况下建立的索引是非聚簇索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说:
a.有大量重复值、且经常有范围查询( > ,< ,> =,< =)和order by、group by发生的列,可考
虑建立群集索引;
b.经常同时存取多列,且每列都含有重复值可考虑建立组合索引;
c.组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。索引虽有助于提高性能但不是索引越多越好,恰好相反过多的索引会导致系统低效。用户在表中每加进一个索引,维护索引集合就要做相应的更新工作。
2、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短语,任何一种索引都有助于SELECT的性能提高。
3、多表操作在被实际执行前,查询优化器会根据连接条件,列出几组可能的连接方案并从中找出系统开销最小的最佳方案。连接条件要充份考虑带有索引的表、行数多的表;内外表的选择可由公式:外层表中的匹配行数*内层表中每一次查找的次数确定,乘积最小为最佳方案。
4、任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
5、IN、OR子句常会使用工作表,使索引失效。如果不产生大量重复值,可以考虑把子句拆开。拆开的子句中应该包含索引。
Sql的优化原则2:
1、只要能满足你的需求,应尽可能使用更小的数据类型:例如使用MEDIUMINT代替INT
2、尽量把所有的列设置为NOT NULL,如果你要保存NULL,手动去设置它,而不是把它设为默认值。
3、尽量少用VARCHAR、TEXT、BLOB类型
4、如果你的数据只有你所知的少量的几个。最好使用ENUM类型
使用SQLServer Profiler找出数据库中性能最差的SQL
首先打开SQLServer Profiler:
然后点击工具栏“New Trace”,使用默认的模板,点击RUN。
也许会有报错:"only TrueType fonts are supported. There id not a TrueType font"。不用怕,点击Tools菜单->Options,重新选择一个字体例如Vendana 即可。(这个是微软的一个bug)
运行起来以后,SQLServer Profiler会监控数据库的活动,所以最好在你需要监控的数据库上多做些操作。等觉得差不多了,点击停止。然后保存trace结果到文件或者table。
这里保存到Table:在菜单“File”-“Save as ”-“Trace table”,例如输入一个master数据库的新的table名:profileTrace,保存即可。
找到最耗时的SQL:
- use master
- select * from profiletrace order by duration desc;
找到了性能瓶颈,接下来就可以有针对性的一个个进行调优了。
对使用SQLServer Profiler的更多信息可以参考:
http://www.codeproject.com/KB/database/DiagnoseProblemsSQLServer.aspx
使用SQLServer Database Engine Tuning Advisor数据库引擎优化顾问
使用上述的SQLServer Profiler得到了trace还有一个好处就是可以用到这个优化顾问。用它可以偷点懒,得到SQLServer给您的优化顾问,例如这个表需要加个索引什么的…
首先打开数据库引擎优化顾问:
然后打开刚才profiler的结果(我们存到了master数据库的profileTrace表):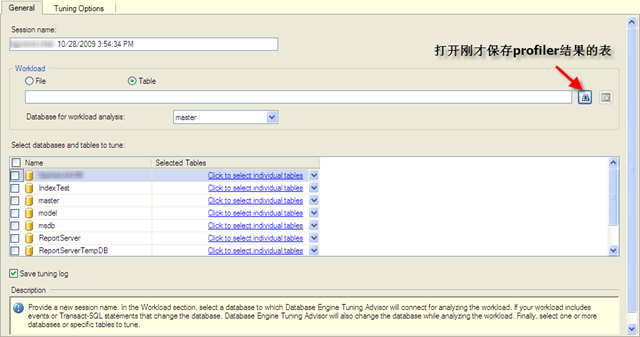
点击“start analysis”,运行完成后查看优化建议(图中最后是建议建立的索引,性能提升72%)
这个方法可以偷点懒,得到SQLServer给您的优化顾问。