mysql官方文档 https://dev.mysql.com/doc/refman/
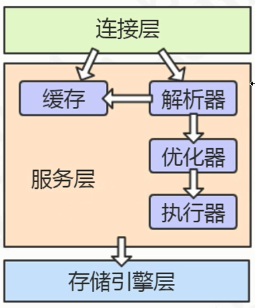
一条查询语句的执行流程
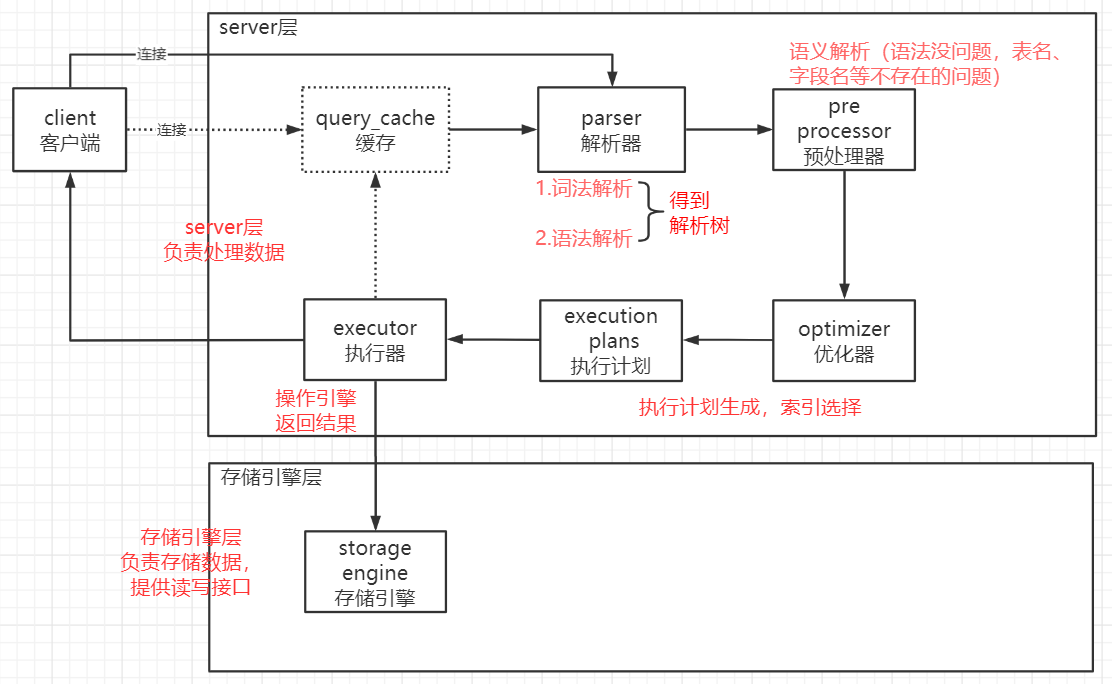
1. 连接
Mysql服务监听的端口默认为3306,有专门负责处理连接的模块,连接是需要权限验证。
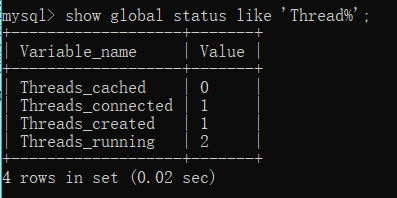
如何查看mysql的连接数?
show global status 'Thread%';
| 字段 | 含义 |
|---|---|
| Threads_cached | 缓存中的线程连接数 |
| Threads_connected | 当前打开的连接数 |
| Threads_created | 为处理连接创建的线程数 |
| Threads_running | 非睡眠状态的连接数,通常指并发连接数 |
为何查看mysl的连接数是“show Thread”查看线程数呢?
因为客户端每产生一个连接或一个会话,在服务器端就会创建一个线程来处理。反过来,如果要结束会话,就需要杀死进程。
每一个连接都分配线程的话,毋庸置疑是需要消耗服务端资源的,所以在连接时长和连接数(并发量)上mysql就做了些处理。
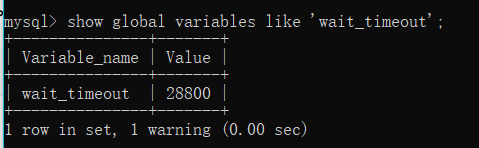
- 连接时长:mysql会把长时间不活动(sleep)的连接自动断开。
show variables like 'wait_timeout'; --非交互式超时时间,如JDBC程序
show variables like 'max_connections'; --交互式超时时间,如数据库工具
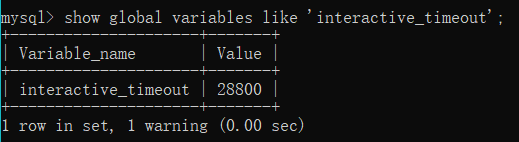
交互式和非交互式的默认连接超时时长都是28800秒(8小时)。
- 连接数:mysql服务允许最大的连接数(并发数)是多少?
show variables like 'max_connections';
下图中的最大连接数为200(这里是我自己做了修改),在mysql5.7和目前的mysql8.0的版本中,mysql的默认最大连接数为151,最大可支持设置成100000(10w)

mysql8.0官网关于max_connections的描述

2. 查询缓存
mysql中查询缓存默认为关闭状态(不推荐使用),且mysql8.0中已经将查询缓存移除了。需要缓存还是交给ORM(如:mybatis默认开启一级缓存)框架或redis等第三方服务来实现。
show variables like 'query_cache%';
3. 语法解析和预处理
主要是对sql语句基于SQL语法进行词法分析和语法分析以及语义解析。
3.1 词法分析:就是把一条sql语句分成一个个单词。
如
select * from student where student = '1';
会分成select、*、from、student、where、student、=、'1'八个单词,每个单词从哪开始从哪结束,是什么类型。
3.2 语法分析
及对SQL做一些语法检查,比如单引号是否闭合、识别关键字等,然后根据SQL语法规则,生成解析树(select_lex)。
3.3 预处理器
在语法分析的基础上(解决语法分析无法解析的语义),对表名、列名是否存在、别名是否异常等问题进行解析处理,进一步生成一个新的解析树。
4.查询优化和查询执行计划
4.1 查询优化器
查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选择一种最优的执行计划,MySQL里面使用的是基于开销(cost)的优化器,哪种计划开销最小,就用哪种。
查看查询的开销:
show status like 'Last_query_cost';
4.2 优化器都做哪些优化?
如:
两表关联查询时,以哪个表为基准表;
多个索引可以使用时,使用哪个索引等等。
以下来自《数据库查询优化器艺术-原理解析与SQL性能优化》
4.2.1 子查询优化
4.2.2 等价谓词重写
4.2.3 条件简化
4.2.4 外连接消除
4.2.5 嵌套连接消除
4.2.6 连接的消除
4.2.7 语义优化
4.2.8 非SPJ优化
优化完之后,优化器会把解析树变成一个查询执行计划,查询执行计划是一个数据结构。
可以通过在sql语句前加上explain来查看执行计划的信息
如:
EXPLAIN select name from student where id = 1;
获取详细信息:
EXPLAIN FORMAT=JSON select name from student where id = 1;
5.存储引擎
mysql支持多种存储引擎,常用的有MyISAM和InnoDB,5.5.5之前mysql默认的存储引擎为MyISAM,5.5.5之后mysql默认的存储引擎为InnoDB。
常见的存储引擎
5.7 https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
8.0 https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html
MyISAM
- 通常用于只读或以读为主的工作,表级锁定限制了读写性能。
特点:- 支持表级别的锁(插入和更新会锁表)。不支持事物。
- 拥有较高的插入(insert)和查询(select)速度。
- 存储了表的行数(count速度更快)。
tips: 怎么快速向数据库插入100w条数据?
- 可以先用MyISAM插入数据,然后修改存储引擎为InnoDB。
InnoDB
5.7、8.0版本中默认的存储引擎,适合经常更新的表,存在并发读写或者有事务处理的业务系统
- 支持事务,支持外键,因此数据的完整性,一致性更高
- 支持行级别的锁和表级别的锁
- 支持读写并发,写不阻塞读(MVCC)。啥是MVCC?以后再说。
- 特殊的索引存放方式,可以减少IO,提升查询效率
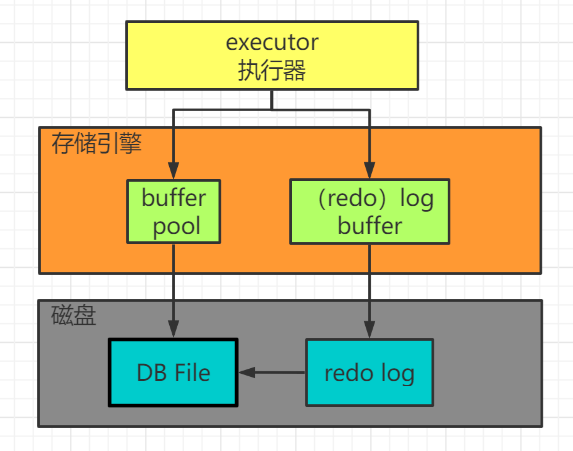
一条更新语句是如何执行的
执行流程简述
一个简化后的过程(因为更新操作涉及到事务,这里先记一个大概的流程示例)
要将student表中id=1的学生姓名(原为lisi)修改为zhangsan,执行sql语句
update student set name='zhangsan' where id=1;
- 事务开始,从内存(buffer pool)或磁盘取到包含这条数据的数据页,返回给Server的执行器;
- 执行器修改数据页的一行数据;
- 记录修改之前的内容到undo log,如update student set name='lisi' where id=1;;
- 记录要修改的操作到redo log,如update student set name='zhangsan' where id=1;
- 调用存储引擎接口,记录数据页到buffer pool
- 事务提交。
缓冲池 Buffer Pool
InnoDB设定了一个存储引擎从磁盘读取数据到内存的最小单位,叫做页。
操作系统也有页的概念。操作系统的页大小一般是4k(传闻中的4k对齐),在InnoDB中,这个最小的单位默认是16KB大小。若需要修改这个值的话,修改后需要清空数据重新初始化服务。
https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_page_size
也就是说InnoDB存储引擎从磁盘读取数据的时候,每次最少读16KB的数据,我们所需要的操作的数据就在这样的页里面,也就是常常说的数据页。
而我们每次拿数据如果都从磁盘中取出来放入内存的话,还是避免不了频繁io消耗资源的问题,这里就还是需要一个缓存的思想,把读取过的数据页缓存起来。
InnoDB设计了一个内存的缓冲区。读取数据的是会,先判断缓冲区内是否存在,若存在则直接取用,不存在则从磁盘读取后将数据放入这个内存的缓冲区内。这个缓冲区就叫做Buffer Pool。
修改数据时,也是先写到buffer pool,而不是直接写到磁盘。内存的数据页和磁盘数据不一致的时候,我们把内存取的这部分数据叫做脏页。InnoDB中有专门的后台线程把buffer pool的数据写到磁盘,每隔一段时间就会一次性的把多个修改写入(同步)的磁盘,这个动作就叫做刷脏。
有次可见,Buffer Pool的作用就是为了提高读写的效率。
redo log
因为刷脏不是实时的,如果Buffer Pool里面的脏页没有同步到磁盘时,服务器或者数据库宕机或者重启,这些数据就会丢失。如何避免这部分数据的丢失,实现内存内数据的持久化呢?
InnoDB把所有对“页”的修改操作写入到一个操作日志文件中。如果脏页中的内容没有同步到磁盘时,数据库再启动的时候,会从这个日志文件进行恢复操作(实现crash-safe)。我们说的事务的ACID中的D(持久性),就是用它来实现的。
这个日志文件就叫做redo log(重做日志)。
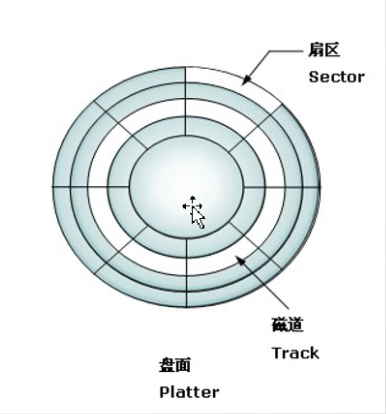
既然都要写磁盘,为何不直接写到DBFile里面,还要先写日志再写磁盘呢?
- 这个与顺序io和随机io有关
- 如果需要的数据是随机分散在磁盘的不同页的不同扇区中的,那么找到相应的数据需要等磁臂旋转到指定的页,然后盘片寻找到对应的扇区(寻址的过程),才能找到所需要的的一块数据,依次进行此过程(不断地重新寻址)直到找完所有数据,这个就是随机IO。
- 顺序IO是指读写操作的访问地址连续。如盘片已经找到了第一块数据所在的扇区(寻址成功)后,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址,可以依次拿到所需的数据,这个就叫顺序IO。
- 直接写数据文件(写数据(写聚簇索引)、写索引(普通索引))是随机I/O,而记录日志是顺序I/O(不断地追加),因此先把修改写入日志文件,在保证了内存数据安全性的情况下,可以延迟刷盘时机,进而提升系统吞吐量。
redo log特点
- 为InnoDB提供了崩溃恢复的特性,实现持久性
- redo log的大小是固定的,前面的内容会被覆盖,一旦写满,就会触发buffer pool到磁盘的同步,以便腾出空间记录后面的修改。
- 默认有两个文件ib_logfile0和ib_logfile1,每个48m。
可以通过以下命令查看InnoDB中redo log的相关参数:
show variables like 'innodb_log%';
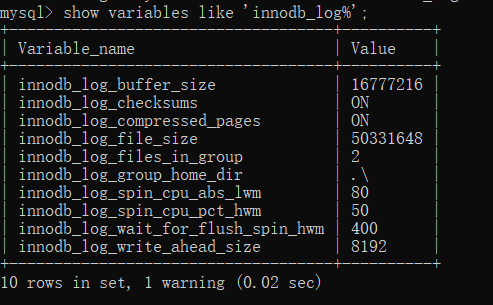
| 参数 | 含义 |
|---|---|
| innodb_log_size | 每个文件的大小,默认48M |
| innodb_log_files_in_group | 文件的数量,默认为2个 |
| innodb_log_group_home_dir | 文件所在路径,如果不指定,则为datadir的路径 |
除了redo log外,还有一个跟修改相关的日志,叫做undo log。redo log和undo log与实务密切相关,统称为事务日志。
undo log
undo log(撤销日志或回滚日志)记录了实务发生之前的数据状态,分为insert undo log和update updo log。如果修改数据时出现异常,可以用undo log来实现回滚操作(保持原子性)。
show variables like '%undo%';
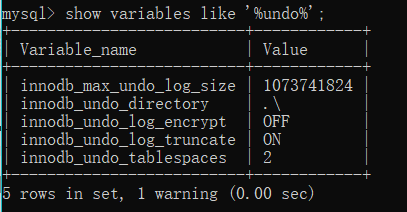
| 参数 | 含义 |
|---|---|
| innodb_undo_directory | uodo文件的路径 |
| innodb_undo_log_truncate | 是否开启在线回收undo log日志文件 |
| innodb_max_undo_log_size | undo文件的大小。如果开启了innodb_undo_log_truncate,超过这个大小的时候就会触发truncate回收动作,如果page大小是16kb,truncate后空间缩小到10M。默认1073741824字节=1G。 |
| innoidb_undo_tablespaces | 设置undo独立表空间个数,范围为0-95,默认为0。0表示不开启独立undo表空间,且undo日志存储在ibdata文件中。 |
| innodb_undo_log_encrypt |