前言
哈夫曼编码(Huffman coding)是一种可变长的前缀码。哈夫曼编码使用的算法是David A. Huffman还是在MIT的学生时提出的,并且在1952年发表了名为《A Method for the Construction of Minimum-Redundancy Codes》的文章。编码这种编码的过程叫做哈夫曼编码,它是一种普遍的熵编码技术,包括用于无损数据压缩领域。由于哈夫曼编码的运用广泛,本文将简要介绍:
哈夫曼编码的编码(不包含解码)原理
代码(java)实现过程
一、哈弗曼编码原理
哈夫曼编码使用一种特别的方法为信号源中的每个符号设定二进制码。出现频率更大的符号将获得更短的比特,出现频率更小的符号将被分配更长的比特,以此来提高数据压缩率,提高传输效率。具体编码步骤主要为,
1、统计:
在开始编码时,通常都需要对信号源,也就是本文的一段文字,进行处理,计算出每个符号出现的频率,得到信号源的基本情况。接下来就是对统计信息进行处理了
2、构造优先对列:
把得到的符号添加到优先队列中,此优先队列的进出逻辑是频率低的先出,因此在设计优先队列时需要如此设计,如果不熟悉优先队列,请阅读相关书籍,在此不做过多概述。得到包含所有字符的优先队列后,就是处理优先队列中的数据了。
3、构造哈夫曼树:
哈夫曼树是带权值得二叉树,我们使用的哈夫曼树的权值自然就是符号的频率了,我们构建哈夫曼树是自底向上的,先构建叶子节点,然后逐步向上,最终完成整颗树。先把队列中的一个符号出列,也就是最小频率的符号,,然后再出列一个符号。这两个符号将作为哈夫曼树的节点,而且这两个节点将作为新节点,也就是它们父节点,的左右孩子节点。新节点的频率,即权值,为孩子节点的和。把这个新节点添加到队列中(队列会重新根据权值排序)。重复上面的步骤,两个符号出列,构造新的父节点,入列……直到队列最后只剩下一个节点,这个节点也就是哈夫曼树的根节点了。
4、为哈弗曼树编码:
哈夫曼树的来自信号源的符号都是叶子节点,需要知道下。树的根节点分配比特0,左子树分配0,右字数分配1。然后就可以得到符号的码值了。
二、示例(转自这的)
假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3,如图:
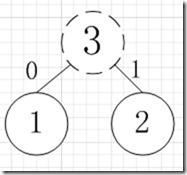
虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图:
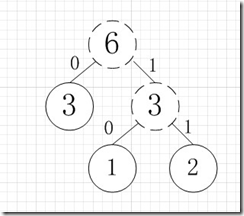
再依次建立哈夫曼树,如下图:
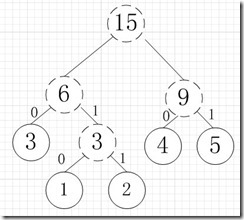
其中各个权值替换对应的字符即为下图:
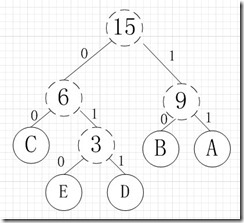
所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
如下图也可以加深大家的理解(图片来自于wikipedia)

下面的这个图片是互动示例的截图,来自http://www.hightechdreams.com/weaver.php?topic=huffmancoding,输入符号就会动态展示出树的构建,有兴趣的朋友可以去看看

三、 代码实现
先是设计一个用于节点比较的接口

1 package com.huffman;
2
3 //用来实现节点比较的接口
4 public interface Compare<T> {
5 //小于
6 boolean less(T t);
7 }
然后写一个哈夫曼树节点的类,主要是用于储存符号信息的,实现上面的接口,get、set方法已经省略了
1 package com.huffman;
2
3 public class Node implements Compare<Node>{
4
5 //节点的优先级
6 private int nice;
7
8 //字符出现的频率(次数)
9 private int count;
10
11 //文本中出现的字符串
12 private String str;
13
14 //左孩子
15 private Node leftNode;
16
17 //右孩子
18 private Node rightNode;
19
20 //对应的二进制编码
21 private String code;
22
23 public Node(){
24 }
25
26 public Node(int nice, String str, int count){
27 this.nice = nice;
28 this.str = str;
29 this.count = count;
30 }
31
32 //把节点(权值,频率)相加,返回新的节点
33 public Node add(Node node){
34 Node n = new Node();
35 n.nice = this.nice + node.nice;
36 n.count = this.count + node.count;
37 return n;
38 }
39
40 public boolean less(Node node) {
41 return this.nice < node.nice;
42 }
43
44
45 public String toString(){
46 return String.valueOf(this.nice);
47 }
设计一个优先队列
1 package com.huffman;
2
3 import java.util.List;
4
5 public class PriorityQueue<T extends Compare<T>> {
6
7 public List<T> list = null;
8
9 public PriorityQueue(List<T> list){
10 this.list = list;
11 }
12
13 public boolean empty(){
14 return list.size() == 0;
15 }
16
17 public int size(){
18 return list.size();
19 }
20
21 //移除指定索引的元素
22 public void remove(int number){
23 int index = list.indexOf(number);
24 if (-1 == index){
25 System.out.println("data do not exist!");
26 return;
27 }
28 list.remove(index);
29 //每次删除一个元素都需要重新构建队列
30 buildHeap();
31 }
32
33 //弹出队首元素,并把这个元素返回
34 public T pop(){
35 //由于优先队列的特殊性,第一个元素(索引为0)是不使用的
36 if (list.size() == 1){
37 return null;
38 }
39 T first = list.get(1);
40 list.remove(1);
41 buildHeap();
42 return first;
43
44 }
45
46 //加入一个元素到队列中
47 public void add(T object){
48 list.add(object);
49 buildHeap();
50 }
51
52 //维护最小堆
53 private List<T> minHeap(List<T> list, int position, int heapSize){
54 int left = 2 * position; //得到左孩子的位置
55 int right = left + 1; //得到右孩子的位置
56 int min = position; //min储存最小值的位置,暂时假定当前节点是最小节点
57 //寻找最小节点
58 if (left < heapSize && list.get(left).less(list.get(min))){
59 min = left;
60 }
61 if (right < heapSize && list.get(right).less(list.get(min))){
62 min = right;
63 }
64
65 if (min != position){
66 exchange(list, min, position); //交换当前节点与最小节点的位置
67 minHeap(list, min, heapSize); //重新维护最小堆
68 }
69 return list;
70 }
71
72 //交换元素位置
73 private List<T> exchange(List<T> list, int former, int latter){
74 T temp = list.get(former);
75 list.set(former, list.get(latter));
76 list.set(latter, temp);
77 return list;
78 }
79
80 //构建最小堆
81 public List<T> buildHeap(){
82 int i;
83 for (i = list.size() - 1; i > 0; i--){
84 minHeap(list, i, list.size());
85 }
86 return list;
87 }
88
89 }
最后是用一个类构建哈夫曼树
1 package com.huffman;
2
3 import java.util.ArrayList;
4 import java.util.HashMap;
5 import java.util.List;
6 import java.util.Map;
7
8 public class Huffman {
9 //优先队列
10 private PriorityQueue<Node> priorQueue;
11
12 //需要处理的文本
13 private String[] text;
14
15 //文本处理后的统计信息
16 private Map<String, Integer> statistics;
17
18 //huffman编码最终结果
19 private Map<String, String> result;
20
21 public Huffman(String text) {
22 this.text = text.split("\W+");
23 init();
24 }
25
26 private void init() {
27 statistics = new HashMap<String, Integer>();
28 result = new HashMap<String, String>();
29 }
30
31 //获取字符串统计信息,得到如"abc":3,"love":12等形式map
32 private void getStatistics() {
33 int count;
34 for (String c : text) {
35 if (statistics.containsKey(c)) {
36 count = statistics.get(c);
37 count++;
38 statistics.put(c, count);
39 } else {
40 statistics.put(c, 1);
41 }
42 }
43 }
44
45 //构建huffman树
46 private void buildTree() {
47 List<Node> list = new ArrayList<Node>();
48 list.add(new Node(2222, "123", 2222)); //因为优先队列的特殊性,添加这个不使用的节点
49 //把字符串信息储存到节点中,并把节点添加到arrayList中
50 for (String key : statistics.keySet()) {
51 Node leaf = new Node(statistics.get(key), key, statistics.get(key));
52 list.add(leaf);
53 }
54 Node tree = null; //用于储存指向huffman树根节点的指针
55 priorQueue = new PriorityQueue<Node>(list); //以上面节点为元素,构建优先队列
56 priorQueue.buildHeap();
57 Node first = null;
58 Node second = null;
59 Node newNode = null;
60 do {
61 first = priorQueue.pop(); //取出队首的元素,作为左孩子节点
62 second = priorQueue.pop(); //取出队首的元素,作为右孩子节点
63 newNode = first.add(second); //构建父节点
64 priorQueue.add(newNode); //把父节点添加到队列中
65 newNode.setLeftNode(first);
66 newNode.setRightNode(second);
67 tree = newNode; //把tree指向新节点
68 } while (priorQueue.size() > 2); //由于队列中有一个元素是不使用的,所以队列只剩最后一个元素(实际就是队列只有2个元素)时就该退出循环了。
69 //最后剩下一个节点是根节点,把它取出来,并拼装树
70 Node root = priorQueue.pop();
71 root.setCode("0");
72 root.setLeftNode(tree.getLeftNode());
73 root.setRightNode(tree.getRightNode());
74 tree = null;
75 setCodeNum(root); //遍历树,为每个节点编码
76 System.out.println("----------------------------");
77 System.out.println(result);
78 }
79
80 public void buildHuffman(){
81 getStatistics(); //收集统计信息
82 buildTree();
83 for (String c : statistics.keySet()) {
84 System.out.println(c + ":" + statistics.get(c));
85 }
86 }
87
88 //编码
89 private void setCodeNum(Node tree){
90 if(null == tree){
91 return;
92 }
93 Node left = tree.getLeftNode();
94 Node right = tree.getRightNode();
95 if (left !=null){
96 left.setCode("0" + tree.getCode()); //左孩子的码为0
97 if (statistics.containsKey(left.getStr())){
98 //如果节点在统计表里,把它添加到result中
99 result.put(left.getStr(), left.getCode());
100 }
101 }
102 if (right != null){
103 right.setCode("1" + tree.getCode()); //右孩子的码为1
104 if (statistics.containsKey(right.getStr())){
105 //如果节点在统计表里,把它添加到result中
106
107 result.put(right.getStr(), right.getCode());
108 }
109 }
110 setCodeNum(left); //递归
111 setCodeNum(right); //递归
112
113 }
114
115 }
注意:代码实现的提供主要是为了概要介绍哈夫曼编码的实现过程,部分代码逻辑并为深思,效率也略低,请大家只做参考,并多参考其他人的代码。
参考文章:
http://people.cs.pitt.edu/~kirk/cs1501/animations/Huffman.html
http://www.hightechdreams.com/weaver.php?topic=huffmancoding
延伸阅读:
http://www.hightechdreams.com/weaver.php?topic=huffmancoding
这个网站是由一群用它们的话说是为“对编程狂热或者有兴趣的人建立的”,提供了很多算法有关的互动的例子,以及一些小程序
http://www.siggraph.org/education/materials/HyperGraph/video/mpeg/mpegfaq/huffman_tutorial.html
这是一个建立哈夫曼树的简明教程
http://rosettacode.org/wiki/Huffman_codes
提供了多语言的哈夫曼树实现,包括c, c++, java, c#, python, lisp等。有兴趣的朋友可以参考下,看看国外的码农是怎么玩哈夫曼树的。