上一篇文章:《数据质量检查-理论篇》主要介绍了数据质量检查的基本思路与方法,本文作为补充,从实战角度出发,总结一套基于Python的数据质量检查模板。
承接上文,仍然从重复值检查、缺失值检查、数据倾斜检查、异常值检查四方面进行描述。
1.环境介绍
版本:python2.7
工具:Spyder
开发人:hbsygfz
2.数据集介绍
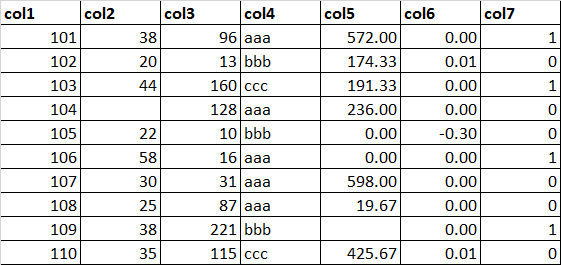
数据集:dataset.xlsx
3.代码实现
3.1 导入相关库
import pandas as pd
###3.2 读取数据集
dataset = pd.read_excel("/labcenter/python/dataset.xlsx")
discColList = ['col4','col7']
contColList = ['col1','col2','col3','col5','col6']
###3.3 重复值检查 主要统计指标:重复记录数、字段唯一值数。
### (1)重复记录数
def dupRowsCheck(df):
dupRows = df.duplicated().sum()
return dupRows
### (2)字段唯一值数
def uiqColValCheck(df):
# 记录数,变量数
m,n = df.shape
uiqDf = pd.DataFrame(index=df.columns,columns=['rows','uiqCnt'])
uiqDf['rows'] = m
for j in range(n):
ser = df.iloc[:,j]
name = df.columns[j]
uiqCnt = len(ser.unique())
uiqDf.loc[name,'uiqCnt'] = uiqCnt
return uiqDf
执行与结果:
dupRowsCheck(dataset)
Out[95]: 0
uiqColValCheck(dataset)
Out[96]:
rows uiqCnt
col1 10 10
col2 10 9
col3 10 10
col4 10 3
col5 10 9
col6 10 5
col7 10 2
###3.4 缺失值检查 主要统计指标:字段空值记录数。
def missingCheck(df):
# 记录数,变量数
m,n = df.shape
rowsSer = pd.Series(index=df.columns)
rowsSer.name = 'rows'
# 空值记录数
nullCntSer = df.isnull().sum()
nullCntSer.name = 'nullCnt'
# 合并结果
missDf = pd.concat([rowsSer,nullCntSer],axis=1)
missDf['rows'] = m
return missDf
执行与结果:
missingCheck(dataset)
Out[97]:
rows nullCnt
col1 10 0
col2 10 1
col3 10 0
col4 10 0
col5 10 1
col6 10 0
col7 10 0
###3.5 数据倾斜检查 主要统计指标:记录数、类别个数、最大类别记录数、最大类别记录数占比。
def skewCheck(df,discList,contList,bins):
# 离散型变量类别统计
new_df1 = df[discList]
skewDf1 = pd.DataFrame(index=discList,columns=['rows','classCnt','mostClassCnt','mostClassRio'])
m1,n1 = new_df1.shape
for j in range(n1):
ser = new_df1.iloc[:,j]
name = new_df1.columns[j]
freqSer = pd.value_counts(ser)
skewDf1.loc[name,'rows'] = m1
skewDf1.loc[name,'classCnt'] = len(freqSer)
skewDf1.loc[name,'mostClassCnt'] = freqSer[0]
skewDf1.loc[name,'mostClassRio'] = freqSer[0] * 1.00 / m1
# 连续型变量分箱统计
new_df2 = df[contList]
skewDf2 = pd.DataFrame(index=contList,columns=['rows','classCnt','mostClassCnt','mostClassRio'])
m2,n2 = new_df2.shape
for j in range(n2):
ser = new_df2.iloc[:,j]
name = new_df2.columns[j]
freqSer = pd.value_counts(pd.cut(ser,bins))
skewDf2.loc[name,'rows'] = m2
skewDf2.loc[name,'classCnt'] = len(freqSer)
skewDf2.loc[name,'mostClassCnt'] = freqSer[0]
skewDf2.loc[name,'mostClassRio'] = freqSer[0] * 1.00 / m2
# 合并结果
skewDf = pd.concat([skewDf1,skewDf2],axis=0)
return skewDf
执行与结果:
skewCheck(dataset,discColList,contColList,4)
Out[98]:
rows classCnt mostClassCnt mostClassRio
col4 10 3 5 0.5
col7 10 2 6 0.6
col1 10 4 3 0.3
col2 10 4 3 0.3
col3 10 4 4 0.4
col5 10 4 3 0.3
col6 10 4 1 0.1
###3.6 异常值检查 主要统计指标:最大值、最小值、平均值、标准差、变异系数、大于平均值+3倍标准差的记录数、小于平均值-3倍标准差记录数、大于上四分位+1.5倍的四分位间距记录数、小于下四分位-1.5倍的四分位间距记录数、正值记录数、零值记录数、负值记录数。
### (1)异常值统计
def outCheck(df,contList):
new_df = df[contList]
resDf = new_df.describe()
resDf.loc['cov'] = resDf.loc['std'] / resDf.loc['mean'] #计算变异系数
resDf.loc['mean+3std'] = resDf.loc['mean'] + 3 * resDf.loc['std'] #计算平均值+3倍标准差
resDf.loc['mean-3std'] = resDf.loc['mean'] - 3 * resDf.loc['std'] #计算平均值-3倍标准差
resDf.loc['75%+1.5dist'] = resDf.loc['75%'] + 1.5 * (resDf.loc['75%'] - resDf.loc['25%']) #计算上四分位+1.5倍的四分位间距
resDf.loc['25%-1.5dist'] = resDf.loc['25%'] - 1.5 * (resDf.loc['75%'] - resDf.loc['25%']) #计算下四分位-1.5倍的四分位间距
# 3segma检查
segmaSer1 = new_df[new_df > resDf.loc['mean+3std']].count() #平均值+3倍标准差
segmaSer1.name = 'above3SegmaCnt'
segmaSer2 = new_df[new_df < resDf.loc['mean-3std']].count() #平均值-3倍标准差
segmaSer2.name = 'below3SegmaCnt'
# 箱线图检查
boxSer1 = new_df[new_df > resDf.loc['75%+1.5dist']].count() #上四分位+1.5倍的四分位间距
boxSer1.name = 'aboveBoxCnt'
boxSer2 = new_df[new_df < resDf.loc['25%-1.5dist']].count() #下四分位-1.5倍的四分位间距
boxSer2.name = 'belowBoxCnt'
# 合并结果
outTmpDf1 = pd.concat([segmaSer1,segmaSer2,boxSer1,boxSer2],axis=1)
outTmpDf2 = resDf.loc[['max','min','mean','std','cov']]
outDf = pd.concat([outTmpDf2.T,outTmpDf1],axis=1)
return outDf
### (2)正负分布检查
def distCheck(df,contList):
new_df = df[contList]
distDf = pd.DataFrame(index=contList,columns=['rows','posCnt','zeroCnt','negCnt'])
m,n = new_df.shape
for j in range(n):
ser = new_df.iloc[:,j]
name = new_df.columns[j]
posCnt = ser[ser>0].count()
zeroCnt = ser[ser==0].count()
negCnt = ser[ser<0].count()
distDf.loc[name,'rows'] = m
distDf.loc[name,'posCnt'] = posCnt
distDf.loc[name,'zeroCnt'] = zeroCnt
distDf.loc[name,'negCnt'] = negCnt
return distDf
执行与结果:
outCheck(dataset,contColList)
Out[101]:
max min mean std cov above3SegmaCnt below3SegmaCnt aboveBoxCnt belowBoxCnt
col1 110.0000 101.0 105.500000 3.027650 0.028698 0 0 0 0
col2 58.0000 20.0 34.444444 11.959422 0.347209 0 0 1 0
col3 221.0000 10.0 87.700000 71.030588 0.809927 0 0 0 0
col5 598.0000 0.0 246.333333 235.303647 0.955225 0 0 0 0
col6 0.0115 -0.3 -0.027740 0.095759 -3.452026 0 0 2 1
distCheck(dataset,contColList)
Out[102]:
rows posCnt zeroCnt negCnt
col1 10 10 0 0
col2 10 9 0 0
col3 10 10 0 0
col5 10 7 2 0
col6 10 3 6 1