对于喜欢电影的人来说各种电影资源必不可少,但每次自己搜索都比较麻烦,索性用python自己写一个自动搜索的脚本。
这里我只分享我的思路,具体如何实现参考代码,要想实现搜索功能先要抓包分析如何发送数据,这里我用的是burp,
这是电影网站搜索框,

输入电影名抓取数据报:
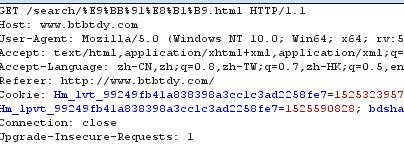
数据一get方式提交,并且进行了url编码,%E9%BB%91%E8%B1%B9进行url解码后正是“黑豹”两个字
python中用于处理url编码的是urllib中的quote模块
name=黑豹
uname=quote(name)
所以我们提交数据的地址为:url='http://www.btbtdy.com/search/'+uname+'.html'
之后就得到这个界面:

我们只需要拿到最顶端的那个连接就行,直接用beautifulsoup进行匹配也可以用re正则匹配,找到“黑豹"两个字的herf属性即可
最后得到的数据为”/btdy/dy7706.html",与原网址进行拼接记得到我们要找电影资源的主页面为:
http://www.btbtdy.com/btdy/dy7706.html
到达主页面后,如果你直接用以前的办法直接用正则或其他的办法去匹配磁力链接的话是不行的,因为这是一个动态的页面,
思路依旧是抓包分析,可以看出主页面提交后有提交多个其他的请求,其中有也个请求是这样的:
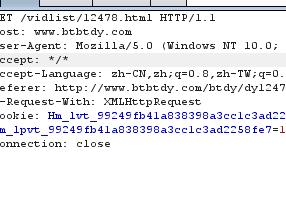
在网页上访问后是这样的:

这才是我们要找的网页,只有在这个网页上才能找到真正的资源
上代码:(代码还没有进行异常处理)
1 import requests 2 from bs4 import BeautifulSoup 3 4 from urllib.parse import quote 5 import time 6 import re 7 import threading 8 9 head = { 10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 11 'Referer':'http://www.btbtdy.com/' 12 } 13 14 print('-----------------------------') 15 name=input('请输入需要查找的电影:') 16 print('-----------------------------') 17 uname=quote(name) 18 19 def pyhead(): 20 21 url='http://www.btbtdy.com/search/'+uname+'.html' 22 23 return url 24 25 def gethtml(url): 26 27 link=url 28 html=requests.get(link,head) 29 time.sleep(5) 30 soup = BeautifulSoup(html.text, "lxml") 31 html = html.content.decode('utf-8') 32 sorry="对不起,没有找到任何记录," 33 sodiv=soup.find('div',class_="list_so") 34 if sorry in str(sodiv): 35 print("网站没有资源") 36 else: 37 title=soup.find_all('a',class_="so_pic") 38 r=r'href="(.+?)" ' 39 title=re.findall(r,str(title[0])) 40 print("网址为:http://www.btbtdy.com"+title[0]) 41 return title 42 43 def gethtml2(title): 44 dr=r'btdy/dy(.+?).html' 45 dtit=re.findall(dr,title[0]) 46 url2='http://www.btbtdy.com/vidlist/'+dtit[0]+'.html' 47 dhtml=requests.get(url2,head) 48 time.sleep(5) 49 dsoup=BeautifulSoup(dhtml.text,'lxml') 50 return dsoup 51 52 def getdhtml(dsoup): 53 ddiv=dsoup.find_all('div',class_="p_list") 54 for model in ddiv: 55 h="<h2>720p下载地址</h2>" 56 h2="<h2>1080p下载地址</h2>" 57 h3="<h2>下载地址一</h2>" 58 if h in str(model): 59 print("720p:"' ') 60 r='<a class="d1" href="(.+?)">磁力</a>' 61 dlink=re.findall(r,str(model)) 62 for pdlink in dlink: 63 print(str(pdlink)+' ') 64 if h2 in str(model): 65 print("1080p:"' ') 66 r='<a class="d1" href="(.+?)">磁力</a>' 67 dlink=re.findall(r,str(model)) 68 for pdlink in dlink: 69 print(str(pdlink)) 70 if h3 in str(model): 71 print("磁力连接:"' ') 72 r='<a class="d1" href="(.+?)">磁力</a>' 73 dlink=re.findall(r,str(model)) 74 for pdlink in dlink: 75 print(str(pdlink)+' ') 76 77 78 def start(): 79 url=pyhead() 80 title=gethtml(url) 81 dsoup=gethtml2(title) 82 getdhtml(dsoup) 83 if __name__ == '__main__': 84 go=threading.Thread(start()) 85 go.start()