档案系统的简单操作
稍微了解档案系统后,得要知道如何查询整体档案系统的总容量与每个目录所占的容量。
磁盘与目录的容量
我们知道磁盘的整体资料是在 superblock 区块中,但是每个个别档案的容量则在 inode 当中记载的。
那在文字界面该如何交出这几个资料呢?
- df :列出档案系统的整体磁盘使用量;
- du :评估档案系统的磁盘使用量(常用在推估目录所占容量)
df
- 语法:
df [-ahiKHTm] [目录或档案] - 选项与参数:
- -a:列出所有的档案系统,包括系统特有的 /proc 等档案系统;
- -k:以 KBytes 的容量显示个档案系统;
- -m:以 MBytes 的容量显示个档案系统;
- -h:以人们较易阅读的GBytes,MBytes,KBytes 等格式自行显示;
- -H:以 M=1000K 取代 M=1024K 的进位方式;
- -T:连同该 partition 的 filesystem 名称(例如 xfs)也列出;
- -i:不用磁盘容量,而以 inode 的数量来显示;
範例一:將系統內所有的 filesystem 列出來!
[root@study ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/centos-root 10475520 3409408 7066112 33% /
devtmpfs 627700 0 627700 0% /dev
tmpfs 637568 80 637488 1% /dev/shm
tmpfs 637568 24684 612884 4% /run
tmpfs 637568 0 637568 0% /sys/fs/cgroup
/dev/mapper/centos-home 5232640 67720 5164920 2% /home
/dev/vda2 1038336 133704 904632 13% /boot
# 在 Linux 底下如果 df 沒有加任何選項,那麼預設會將系統內所有的
# (不含特殊記憶體內的檔案系統與 swap) 都以 1 Kbytes 的容量來列出來!
# 至於那個 /dev/shm 是與記憶體有關的掛載,先不要理他!
上述输出意思:
- Filesystem:代表该档案系统是在那个 partition,所以列出装置名称;
- 1k-blocks:说明底下的数字单位是 1KB,可以利用 -h 或 -m 来改变容量;
- Used:就是使用掉的磁盘空间;
- Available:也就是剩下的磁盘空间大小;
- Use%:就是磁盘的使用率,如果使用率高达 90% 以上时,需要注意下,免得容量不足造成系统问题。
- Mounted on:就是磁盘挂在的目录。
# 将容量结果以容易显示的格式显示出来
$ df -h
# 将系统内的所有的特殊档案格式及名称都列出来
$ df -aT
# 系统里面其实还是有很多特殊的档案系统存在的,那些比较特殊的档案系统几乎都是在内存中,例如 /proc 这个挂载点。
# 因此,这些特殊的档案系统都不会占用磁盘空间。
# 将 /etc 下的可用的磁盘容量以易读的容量格式显示
$ df -h /etc
# 这个例子有趣,在 df 后面加上目录或者是档案时,df 会自动的分析该目录或档案所在的 partition,并将该 partition 的容量显示出来,
# 所以,你就可以知道某个目录底下还有多少容量可以使用了。
# 将目前各个 partition 当中可用的 inode 数量列出
$ df -ih
# 这个例子主要列出可能的 inode 剩余量与总容量。
# 分析以下与第一个例子的对比会发现,通常 inode 的数量剩余的比 block 还要多。
由于 df 主要读取的资料几乎都是针对一整个档案系统,因此读取的范围主要是在 superblock 内的信息,所以这个指令显示结果的速度非常的快速。
在显示的结果中需要特别留意的就是那个根目录的剩余容量。因为我们所有的资料都是由根目录衍生出来的,因此当根目录的剩余容量剩下 0 时,那Linux可能就问题很大了。
另外需要注意的是,如果使用 -a 这个参数时,系统会出现 /proc 这个挂载点,但是里面的东西都是 0 ,不用紧张,因为 /proc 的东西都是 Linux 系统所需要载入的系统资料,而且是挂在【内存】当中的,所以没有占用任何磁盘空间。
至于那个 /dev/shm/ 目录,其实是利用内存虚拟出来的磁盘空间,通常是总内存的一半!由于是通过内存模拟出来的磁盘,因此在这个目录下建立任何资料时,存取速度是非常快递(在内存内工作),不过,也由于它是内存模拟出来的,因此这个档案系统的大小在每个主机上都不一样,而且建立的东西在下次开机时就会小时了,因为是在内存中嘛!
du
- 语法:
du [-ahskm] 档案或目录名称 - 选项与参数:
- -a:列出所有的档案与目录容量,因为预设仅统计目录底下的档案量而已。
- -h:以人们较易读的容量格式(G/M)显示;
-s:列出总量而已,而不列出每个个别的目录占用容量;- -S:不包括目录下的总计,与 -s 有点差别;
- -k:以 KBytes 列出容量显示;
- -m:以 MBytes 列出容量显示。
# 列出目前目录下的所有档案容量
$ du
# 每个目录都会列出来,包括隐藏档,最后还会给出总量。
# 直接输入 du 没有加任何选项时,则 du 会分析【目前所在目录】的档案与目录所占用的空间。但实际显示时仅会显示目录容量(不含档案),
# 因此目录有很多档案没有被列出来,所以全部的目录相加不会等于 . 的容量哦,此外,输出的数值资料为 1K 大小的容量单位。
# 同上例,但是将档案的内容也列出来
$ du -a
# 检查根目录下每个目录所占用的容量
$ du -sh /*
# 这个用法是非常实用的功能,利用通配符 * 来代表每个目录,如果想要检查某个目录下哪个次级目录的容量最大,可以用这个方法找出来。
# 值得注意的是,如果是刚装好的Linux,最大的应该是 /usr. 而 /proc 虽然有列出容量,但是哪个容量是在内存中,不占硬盘空间。
# 至于 /proc 会列出一堆【no such file or directory】的错误,是因为内存内的程序执行结束就会消失,因此会有些找不到,是正确的。
与 df 不一样的是, du 这个指令其实会直接到档案系统内取搜索所有的档案资料,所以查找 / 的时候肯定会有一小点点耽误时间。
另外,默认容量是以 KB 来设计的,如果你想要知道 M 就加上 -m 这个参数就好了。不过感觉用的比较多的还是 -h 这个人性化的参数。如果指向知道目录占了多少容量的话,使用 -s 就好了。
至于 -S 这个选项部分,由于 du 预设会将所有档案的大小均列出,因此假设你在 /etc 底下使用 du 时,所有档案大小,包括 /etc 底下的次目录容量也会被计算一次。然后最终的容量(/etc)也会加总一次,因此很多朋友误会 du 分析的结果不太对劲。所以喽,如果你想要列出某目录下的全部资料,或许也可以加上 -S 的选项,减少次目录的加总哦。
du -sh ./*列出当前目录下所有子目录的信息,容量按照人性化的方式输出。du -h ./*列出当前目录下所有目录(包括子目录、孙目录、孙孙目录),容量按照人性化方式输出。(但是,列出的子目录的容量是包含孙目录和子目录当中的文档的容量的)du -Sh ./列出当前目录下所有目录(包括子目录......),容量按人性化方式输出,但是,如果你的子目录只包含一个孙目录,那么子目录的空间显示是 4K。
[22:09:23] hare@hare-pc /boot (0)
> du -h ./* 22:09:23
2.3M ./grub/fonts
2.9M ./grub/themes/starfield
2.9M ./grub/themes
2.5M ./grub/i386-pc
7.6M ./grub
29M ./initramfs-4.19-x86_64-fallback.img
8.3M ./initramfs-4.19-x86_64.img
2.5M ./intel-ucode.img
4.0K ./linux419-x86_64.kver
152K ./memtest86+
5.7M ./vmlinuz-4.19-x86_64
[22:09:30] hare@hare-pc /boot (0)
> du -Sh ./ 22:09:30
152K ./memtest86+
2.3M ./grub/fonts
2.9M ./grub/themes/starfield
4.0K ./grub/themes
2.5M ./grub/i386-pc
20K ./grub
45M ./
[22:09:42] hare@hare-pc /boot (0)
> du -sh ./* 22:09:42
7.6M ./grub
29M ./initramfs-4.19-x86_64-fallback.img
8.3M ./initramfs-4.19-x86_64.img
2.5M ./intel-ucode.img
4.0K ./linux419-x86_64.kver
152K ./memtest86+
5.7M ./vmlinuz-4.19-x86_64
实体链接与符号链接:ln
在 Linux 底下的链接档有两种,一种是类似 Windows 的快捷方式的档案,可以让你快速的链接到目标档案或目录;另一种则是通过档案系统的 inode 连接来产生新档名,热不是产生新档案,这种称为实体链接(hard link)。
hard link(实体链接,硬式链接或实际链接)
在前一小节当中,了解的信息有:
- 每个档案都会占用一个 inode,档案内容由 inode 的记录来指向;
- 想要读取该档案,必须要经过目录记录的档名来指向到正确的 inode 号码才能读取。
也就是说,其实档名只与目录有关,但是档案内容则与 inode 有关。那么,有没有可能有多个档名对应到同一个 inode 号码呢?有的,这就是 hard link 的由来。
所以简单的说:hard link 只是在某个目录下新增一笔档名链接到某 inode 号码的关联记录而已。
例如:假设我系统有个 /root/crontab 它是 /etx/crontab 的实体链接,也就是说这两个档名链接到同一个 inode,自然这两个档名的所有相关信息都一模一样(除了档名之外)。
[root@study ~]# ll -i /etc/crontab
34474855 -rw-r--r--. 1 root root 451 Jun 10 2014 /etc/crontab
[root@study ~]# ln /etc/crontab . <==建立實體連結的指令
[root@study ~]# ll -i /etc/crontab crontab
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 crontab
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
可以发现两个档名都链接到 34474855 这个 inode,并且除了【档名】他们的其他属性都一模一样。而且第二位栏由原来的 1 变成了 2 了。这个位栏为【链接】,意义为:【有多少个档名链接到这个 inode 号码】的意思。
如果将读取到正确资料的方式画成示意图,类似:
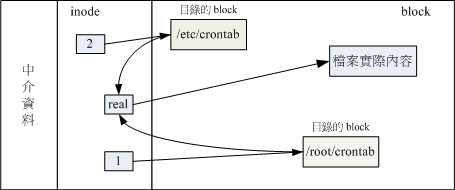
上图意思是,你可以通过 1 或 2 的目录的 inode 指定的 block 找到两个不同的档名,而不管使用那个档名都可以指到 real 那个 inode 去读取到最终资料。
这样做有什么好处呢?最大的好处就是【安全】。
如果你将任何一个【档名】删除,其实 inode 与 block 都还是存在的!此时你可以通过另一个【档名】来读取到正确的档案资料,此外,不论你使用哪个【档名】来编辑,最终的结果都会写入到相同的 inode 与 block 中,因此均能进行资料的修改。
一般来说,使用 hard link 设置链接档时,磁盘的空间与 inode 的数目都不会改变。
hard link 只是在某个目录下的 block 多写入一个关联资料而已,既不会增加 inode 也不会耗用 block 数量。
Tips:hard link 的制作中,其实还是可能会改变系统的 block 的,那就是当你新增这个资料却刚好目录的 block 填满了,就可能会新加一个 block 来记录这个档名关联性,而导致磁盘空间的变化。不过,一般 hard link 所用掉的关联资料量很小,所以通常不会改变 inode 与粗盘空间大小的。
由上图我们可知道,事实上 hard link 应该仅能在单一系统中进行的,应该是不能够跨档案系统才对!因为上图就是在统一个 filesystem 上,所以 hard link 是有限制的:
- 不能跨 filesystem;
- 不能 link 目录。
不能跨 Filesystem 还好理解,
不能 hard link 到目录又是怎么回事呢?
因为如果使用 hard link 连接到目录时,连接的新目录就要多出一个 . 和 .. ,就会导致父母了也多出一个新的链接计算,如果多重处理时,很可能会导致目录搜索时的错误循环问题,导致一个名为死结(打了死结,一致在里面转不出来)的困境。
同时,如果是在不同的目录底下建立目录的 hard link 时,将可能会导致【同一个目录会有好几个父目录】的存在,因此,hard link 一个目录不是做不到,而是建议不要这样做,避免产生系统错乱的困扰啊。
Symbolic Link(符号链接,即捷径)
相对于 hard link,Symbolic link 可就好理解多了,基本上,Symbolic link 就是在建立一个独立的档案,而这个档案会让资料的读取指向他 link 的那个档案的档名,由于只是利用档案来做为指向的动作,所以,当来源档案被删除之后,symbolic link 的档案会【开不了】,会一致说【无法开启某档案】。实际上就是找不到原始【档名】而已啦。
例如:
[root@study ~]# ln -s /etc/crontab crontab2
[root@study ~]# ll -i /etc/crontab /root/crontab2
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
53745909 lrwxrwxrwx. 1 root root 12 Jun 23 22:31 /root/crontab2 -> /etc/crontab
可以看到两个档案指向不同的 inode 号码,当然就是两个独立的档案存在,而且链接档的重要内容就是它会协商目标档案的【档名】,为什么链接档大小为 12bytes呢?因为箭头(-->)右边的档名【/etc/crontab】共有 12 个英文,每个应为占用一个 bytes,所以档案大小就是 12bytes了。
如图:
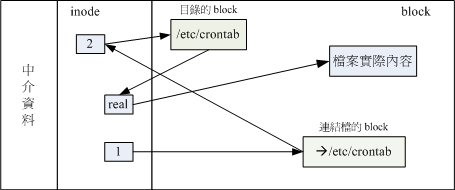
1 号 inode 读取到的链接档的内容仅有档名,根据档名链接到正确的目录取取得目标档案的 inode,最终就能够读取到正确的资料了。可以发现,如果目标档案(/etc/crontab)被删除了,那么整个环节就会无法继续下去,所以就会发生无法通过链接读取的问题了。
需要特别留意,这个Symbolic link 与 Windows 的快捷方式可以画等号,由 Symbolic link 所建立的档案为一个独立的新的档案,所以会占用掉 inode 与 block 哦。
- 语法:
ln [-sf] 来源档 目标档 - 选项与参数:
- -s:如果不加任何参数就进行链接,那就是 hard link ,至于 -s 就是 symbolic link
- -f:如果目标档存在时,就主动的将目标档直接移除后再建立。
範例一:將 /etc/passwd 複製到 /tmp 底下,並且觀察 inode 與 block
[root@study ~]# cd /tmp
[root@study tmp]# cp -a /etc/passwd .
[root@study tmp]# du -sb ; df -i .
6602 . <==先注意一下這裡的容量是多少!
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/mapper/centos-root 10485760 109748 10376012 2% /
# 利用 du 與 df 來檢查一下目前的參數~那個 du -sb 是計算整個 /tmp 底下有多少 bytes 的容量啦!
範例二:將 /tmp/passwd 製作 hard link 成為 passwd-hd 檔案,並觀察檔案與容量
[root@study tmp]# ln passwd passwd-hd
[root@study tmp]# du -sb ; df -i .
6602 .
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/mapper/centos-root 10485760 109748 10376012 2% /
# 仔細看,即使多了一個檔案在 /tmp 底下,整個 inode 與 block 的容量並沒有改變!
[root@study tmp]# ls -il passwd*
2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd
2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd-hd
# 原來是指向同一個 inode 啊!這是個重點啊!另外,那個第二欄的連結數也會增加!
範例三:將 /tmp/passwd 建立一個符號連結
[root@study tmp]# ln -s passwd passwd-so
[root@study tmp]# ls -li passwd*
2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd
2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd-hd
2668898 lrwxrwxrwx. 1 root root 6 Jun 23 22:40 passwd-so -> passwd
# passwd-so 指向的 inode number 不同了!這是一個新的檔案~這個檔案的內容是指向
# passwd 的。passwd-so 的大小是 6bytes ,因為 『passwd』 這個單字共有六個字元之故
[root@study tmp]# du -sb ; df -i .
6608 .
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/mapper/centos-root 10485760 109749 10376011 2% /
# 呼呼!整個容量與 inode 使用數都改變囉~確實如此啊!
範例四:刪除原始檔案 passwd ,其他兩個檔案是否能夠開啟?
[root@study tmp]# rm passwd
[root@study tmp]# cat passwd-hd
.....(正常顯示完畢!)
[root@study tmp]# cat passwd-so
cat: passwd-so: No such file or directory
[root@study tmp]# ll passwd*
-rw-r--r--. 1 root root 2092 Jun 17 00:20 passwd-hd
lrwxrwxrwx. 1 root root 6 Jun 23 22:40 passwd-so -> passwd
# 怕了吧!符號連結果然無法開啟!另外,如果符號連結的目標檔案不存在,
# 其實檔名的部分就會有特殊的顏色顯示喔!
注意**使用 ln 如果不加任何参数的化,那么就是 hard link **.增加 hard link 后,ll 时显示的 link 那一栏的属性就会增加,如果砍掉源文档,那么 hard link 会跟原档案相同,但是 symbolic link 就会找不到该档案了。
使用 ln 的 -s 参数,就做成了 symbolic link 就是 Windows里面的快捷方式,修改symbolic link 档案时,就是修改【原档案】。
此外,如果你做了ls -s /bin /root/bin这样的链接,那么如果进入 /root/bin 这个目录下,【请注意,该目录其实是 /bin 这个目录,因为你做成了链接档。】,所以,如果你将 /root/bin 中的资料杀掉了,那么 /bin 里面的资料也就不见了,千万注意。
基本上, Symbolic link 的用途比较广泛,所以要特别留意 symbolic link 的用法。未来一定会常常用到的。
关于目录的 link 数量
当我们以 hard link 进行【档案的链接】时,ls -l 所显示的第二栏位会增加 1 才对,如果建立目录时,它预设的 link 数量会是多少?一个【空目录】里面至少会存在. 与 .. 这两个目录,那么,当我们建立一个新目录名称 /tmp/testing 时,基本会有三个东西:
- /tmp/testing
- /tmp/testing/.
- /tmp/testing/..
其中 /tmp/testing 与 /tmp/testing/. 其实是一样的!都代表该目录,而 /tmp/testing/.. 则代表了 /tmp 这个目录。
所以说,当我们建立一个新的目录时,【新的目录的 link 数为 2 ,而上层目录的 link 数则会增加 1】。
磁盘的分割、格式化、检验与挂载
对于一个系统管理者(root)而言,磁盘的管理是相当重要的一环,尤其近来磁盘已经渐渐地被当成是消耗品了。如果我们想要在系统里面新增一颗磁盘时,应该有那些动作呢:
- 对磁盘进行分割,以建立可用的 partition;
- 对该 partition 进行格式化(format),以建立系统可用的 filesystem;
- 若想要仔细一点,则可对刚刚建立好的 filesystem 进行检查;
- 在 Linux 系统上,需要建立挂载点(即目录),并将他挂载上来;
当然在上述过程中,还需要考虑很多,例如磁盘分割槽(partition)需要定多大?是否加入 journal 的功能? inode 与 block 的数量应该如何规划等等问题。但是这些问题的决定,都需要与你的主机用途来加以考量的,至于更详细的设定,则需要自己后面的经验积累了。
观察磁盘分割状态
由于目前磁盘分割主要有 MBR 以及 GPT 两种格式,这两种格式所使用的分割工具不太一样,当然可以使用 parted 这个通通支持的工具来处理,不过,我们还是比较习惯使用 fdisk 或者是 gdisk 来处理分割。
因此,我们自然就得要去找一下目前系统有的磁盘有那些?这些磁盘是 MBR 还是 GPT 等等,这样才能处理。
lsblk 列出系统上的所有磁盘列表
lsblk 可以看成是【list block device】的缩写,就是列出所有储存装置的意思,这个工具真的很好用。
- 语法:
lsblk [-dfimpt] [device] - 选项与参数:
- -d:仅列出磁盘本身,并不会列出该磁盘的分割资料
- -f:同时列出该磁盘内的档案系统名称;
- -i:使用 ASCII 的线段输出,不要使用复杂的编码(在某些环境下很有用);
- -m:同时输出该装置在 /dev 底下的权限资料(rwx的资料);
- -p:列出该装置的完整档名!而不是仅列出最后的名字而已;
- -t:列出该磁盘装置的详细资料,包括磁盘伫列机制、预读写资料量大小等。
範例一:列出本系統下的所有磁碟與磁碟內的分割資訊
[root@study ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 40G 0 disk # 一整顆磁碟
|-vda1 252:1 0 2M 0 part
|-vda2 252:2 0 1G 0 part /boot
`-vda3 252:3 0 30G 0 part
|-centos-root 253:0 0 10G 0 lvm / # 在 vda3 內的其他檔案系統
|-centos-swap 253:1 0 1G 0 lvm [SWAP]
`-centos-home 253:2 0 5G 0 lvm /home
上面,目前的系统主要有个 sr0 以及一个 vda 的装置,而 vda 的装置底下又有三个分割,其中 vda3 甚至还有因为 LVM 产生的档案系统,相当完整吧,输出信息主要有:
- NAME:就是装置的档名,会省略 /dev 等前导目录!
- MAJ:MIN:其实核心认识的装置都是通过这两个代码来熟悉的,分别是 主要:次要 装置代码!
- RM:是否为可卸载装置(removable device),如光盘、USB磁盘等等;
- SIZE:容量
- RO:是否为只读装置
- TYPE:是磁盘(disk)、分隔槽(partition)还是只读记忆体(rom)等输出
- MOUTPOINT:挂载点喽。
範例二:僅列出 /dev/vda 裝置內的所有資料的完整檔名
[root@study ~]# lsblk -ip /dev/vda
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
/dev/vda 252:0 0 40G 0 disk
|-/dev/vda1 252:1 0 2M 0 part
|-/dev/vda2 252:2 0 1G 0 part /boot
`-/dev/vda3 252:3 0 30G 0 part
|-/dev/mapper/centos-root 253:0 0 10G 0 lvm /
|-/dev/mapper/centos-swap 253:1 0 1G 0 lvm [SWAP]
`-/dev/mapper/centos-home 253:2 0 5G 0 lvm /home # 完整的檔名,由 / 開始寫
blkid 列出装置的 UUID 等参数
虽然 lsblk 已经可以使用 -f 来列出档案系统与装置的 UUID 资料,不过习惯性的使用 blkid 来找出装置的 UUID。
UUID:全域唯一识别码(universally unique identifier),Linux 会将系统内所有的装置都给予一个独一无二的识别码,这个识别码就可以拿出来作为挂载或者是使用这个装置/档案系统之用了。
直接输入blkid后,每一行代表一个档案系统,主要列出装置名称,UUID名称一级档案系统的类型(TYPE)这对于管理员来说,相当有帮助!对于系统上面的档案系统观察来说,真的是一目了然。
如果输入 blkid没有任何信息输出,需要查看一下你的权限哦,很多时候都是因为权限不足,但是它并不会提示你。
parted 列出磁盘的分割表类型与分割信息
通过上面指令了解系统的所有装置,通过 blkid 知道所有档案系统,但还是不清楚磁盘的分割类型。
这时可以通过简单的 parted 来输出,这里简单的利用,后面学详细指令。
[root@study ~]# parted device_name print
範例一:列出 /dev/vda 磁碟的相關資料
[root@study ~]# parted /dev/vda print
Model: Virtio Block Device (virtblk) # 磁碟的模組名稱(廠商)
Disk /dev/vda: 42.9GB # 磁碟的總容量
Sector size (logical/physical): 512B/512B # 磁碟的每個邏輯/物理磁區容量
Partition Table: gpt # 分割表的格式 (MBR/GPT)
Disk Flags: pmbr_boot
Number Start End Size File system Name Flags # 底下才是分割資料
1 1049kB 3146kB 2097kB bios_grub
2 3146kB 1077MB 1074MB xfs
3 1077MB 33.3GB 32.2GB lvm
这个磁盘是 GPT 的分割格式哦,这样就会看磁盘分割喽。
小哥因为嫌麻烦,在之前Windows系统上直接装的manjaro,所以自己的机器就是 msdos 哈哈,有点意思啊。
磁盘分割:gdisk/fdisk
磁盘分割:【MBR 分割表用 fdisk 分割,GPT 分割表用 fdisk 分割】里面命令都有操作说明,无需死记。
gdisk
hare
2020.3.14