前言
本文主要介绍darknet的使用过程,包括安装、训练、测试、部署等内容。
一、darknet简介
darknet是基于c和cuda的开源神经网络框架,快速且安装简易,支持cpu和gpu计算。
二、测试
$ cd ~/project $ git clone https://github.com/pjreddie/darknet yolov3 $ cd yolov3 $ vi Makefile $ make -j8 ### set TX2 to max performance mode $ sudo nvpmodel -m 0 $ sudo ~/jetson_clocks.sh ### download the pre-trained weights and run YOLOv3 $ wget https://pjreddie.com/media/files/yolov3.weights ### download video this YouTube video $ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights traffic.mp4 ### test V4L2 camera $ ./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights -c 1
根据个人的设备,修改Makefile文件,修改cuda的路径
$ vi Makefile GPU=1 CUDNN=1 OPENCV=1 ...... ARCH= -gencode arch=compute_53,code=[sm_53,compute_53] \ -gencode arch=compute_62,code=[sm_62,compute_62]
Note that CUDA architecture of TX2 is “62”, while TX1 “53”, RTX3080Ti is "86".
[net] # Testing ### 测试模式 # batch=1 # subdivisions=1 # Training ### 训练模式,每次前向的图片数目 = batch/subdivisions batch=64 subdivisions=16
根据test和train对应修改cfg/yolov3.cfg文件。
三、训练
1. 准备数据集;
使用lisa2coco128的数据集进行训练;
.
├── images
│ ├── train
│ └── valid
├── labels
│ ├── train
│ ├── valid
├── train.txt
└── valid.txt
train.txt、valid.txt分别是images中train、valid中的文件路径;
根据数据集的实际内容修改配置文件
1)cfg/lisa2coco128.data
classes= 7 train = /home/xxx/project/darknet_yolov3/lisa2coco128/train.txt valid = /home/xxx/project/darknet_yolov3/lisa2coco128/valid.txt names = data/lisa2coco128.names backup = backup
2) data/lisa2coco128.names
go
goForward
goLeft
stop
stopLeft
warning
warningLeft
2. 训练过程
1)YOLO配置文件的理解


[net] batch=64 每batch个样本更新一次参数。 subdivisions=8 如果内存不够大,将batch分割为subdivisions个子batch,每个子batch的大小为batch/subdivisions。 在darknet代码中,会将batch/subdivisions命名为batch。 height=416 input图像的高 width=416 Input图像的宽 channels=3 Input图像的通道数 momentum=0.9 动量 decay=0.0005 权重衰减正则项,防止过拟合 angle=0 通过旋转角度来生成更多训练样本 saturation = 1.5 通过调整饱和度来生成更多训练样本 exposure = 1.5 通过调整曝光量来生成更多训练样本 hue=.1 通过调整色调来生成更多训练样本 learning_rate=0.0001 初始学习率 max_batches = 45000 训练达到max_batches后停止学习 policy=steps 调整学习率的policy,有如下policy:CONSTANT, STEP, EXP, POLY, STEPS, SIG, RANDOM steps=100,25000,35000 根据batch_num调整学习率 scales=10,.1,.1 学习率变化的比例,累计相乘 [convolutional] batch_normalize=1 是否做BN filters=32 输出多少个特征图 size=3 卷积核的尺寸 stride=1 做卷积运算的步长 pad=1 如果pad为0,padding由 padding参数指定。如果pad为1,padding大小为size/2 activation=leaky 激活函数: logistic,loggy,relu,elu,relie,plse,hardtan,lhtan,linear,ramp,leaky,tanh,stair [maxpool] size=2 池化层尺寸 stride=2 池化步进 [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 ...... ...... ####### [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [route] the route layer is to bring finer grained features in from earlier in the network layers=-9 [reorg] the reorg layer is to make these features match the feature map size at the later layer. The end feature map is 13x13, the feature map from earlier is 26x26x512. The reorg layer maps the 26x26x512 feature map onto a 13x13x2048 feature map so that it can be concatenated with the feature maps at 13x13 resolution. stride=2 [route] layers=-1,-3 [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=125 region前最后一个卷积层的filters数是特定的,计算公式为filter=num*(classes+5) 5的意义是5个坐标,论文中的tx,ty,tw,th,to activation=linear [region] anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52 预选框,可以手工挑选, 也可以通过k means 从训练样本中学出 bias_match=1 classes=20 网络需要识别的物体种类数 coords=4 每个box的4个坐标tx,ty,tw,th num=5 每个grid cell预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num,且如果调大num后训练时Obj趋近0的话可以尝试调大object_scale softmax=1 使用softmax做激活函数 jitter=.2 通过抖动增加噪声来抑制过拟合 rescore=1 暂理解为一个开关,非0时通过重打分来调整l.delta(预测值与真实值的差) object_scale=5 栅格中有物体时,bbox的confidence loss对总loss计算贡献的权重 noobject_scale=1 栅格中没有物体时,bbox的confidence loss对总loss计算贡献的权重 class_scale=1 类别loss对总loss计算贡献的权重 coord_scale=1 bbox坐标预测loss对总loss计算贡献的权重 absolute=1 thresh = .6 random=0 random为1时会启用Multi-Scale Training,随机使用不同尺寸的图片进行训练。
2) yolov3;
修改cfg/yolov3-lisa.cfg文件内容:
- 参数 filters 由下式计算:3*(5+classes),LISA数据集中 classs=7,则filters=36;
- 参数 class 改为实际的类别个数;
一般根据具体情况作适当修改即可,注意,训练的时候,Testing 的 batch 和 subdivisions 需要注释掉,learning_rate 是学习率,max_batches 是最大迭代训练次数,可根据训练集大小自行修改。
配置完成之后,开始编译训练;
make -j8
# 下载预训练模型 wget https://pjreddie.com/media/files/darknet53.conv.74 ./darknet detector train cfg/lisa2coco128.data cfg/yolov3-lisa.cfg darknet53.conv.74 -gpus 0
darknet53.conv.74作为预训练权重文件,因为只包含卷积层,所以可以从头开始训练。
xxx.weights作为预权重文件训练,因为包含所有层,相当于恢复快照训练,会从已经保存的迭代次数往下训练。如果cfg中迭代次数没改,所以不会继续训练,直接保存结束。
3) yolov3-tiny;
配置cfg/yolov3-tiny-lisa.cfg文件的过程与yolov3类似,配置完成之后,开始编译训练;
wget https://pjreddie.com/media/files/yolov3-tiny.weights # 获得训练好的yolov3-tiny的权重 ./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15 # 获得卷积层的权重用来训练自己的数据 # ./darknet detector train cfg/khadas_ai.data khadas_ai/yolov3-khadas_ai_tiny.cfg_train yolov3-tiny.conv.15 -dont_show ./darknet detector train cfg/lisa2coco128.data cfg/yolov3-tiny-lisa.cfg yolov3-tiny.conv.15 -gpus 0
重点之处:需先加载预训练模型,而官网没给tiny版的预训练模型,可以通过训练好的权重yolov3-tiny.weights获取到卷积层的权重;
训练的输出信息
Resizing 544 Loaded: 0.000085 seconds Region 16 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0 Region 23 Avg IOU: 0.805184, Class: 0.999658, Obj: 0.934649, No Obj: 0.001026, .5R: 0.964706, .75R: 0.682353, count: 85 Region 16 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0 Region 23 Avg IOU: 0.847954, Class: 0.999856, Obj: 0.922934, No Obj: 0.001046, .5R: 0.988764, .75R: 0.853933, count: 89 Train detector92421: 0.212829, 0.250515 avg, 0.001000 rate, 1.041044 seconds, 5914944 images Loaded: 0.000086 seconds Region 16 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0 Region 23 Avg IOU: 0.843607, Class: 0.999683, Obj: 0.911380, No Obj: 0.001049, .5R: 0.965517, .75R: 0.862069, count: 87 Region 16 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0 Region 23 Avg IOU: 0.828725, Class: 0.999607, Obj: 0.940976, No Obj: 0.001203, .5R: 0.980392, .75R: 0.784314, count: 102 Train detector92422: 0.260376, 0.251501 avg, 0.001000 rate, 0.975645 seconds, 5915008 images
解析1
Region xx: cfg文件中yolo-layer的索引; Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1; Class: 标注物体的分类准确率,越大越好,期望数值为1; obj: 越大越好,期望数值为1; No obj: 越小越好; .5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本 0.75R: 以IOU=0.75为阈值时候的recall; count: 正样本数目。
这些log在forward_yolo_layer(const layer l, network net) 函数末尾打印出。 yolo3一共3个yolo层,分别在第82,94,106层,所以该log的开头是按82,94,106来交替出现的。而yolov3-tiny的yolo层有2个,分别是16和23层。
解析2
Train detector 92422: 0.260376, 0.251501 avg, 0.001000 rate, 0.975645 seconds, 5915008 images
其中
92422: 指示当前训练的迭代次数 0.260376: 是总体的Loss(损失) 0.251501 avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。 0.001000 rate: 代表当前的学习率,是在.cfg文件中定义的。 0.975645 seconds:表示当前批次训练花费的总时间。 5915008 images: 这一行最后的这个数值是92422*64的大小,表示到目前为止,参与训练的图片的总量。
detection类
typedef struct detection{ box bbox; // bbox int classes; // 类别个数 float *prob; // 每个类别对应的概率 float *mask; float objectness; // 目标置信度 int sort_class; // 目标所属类别 } detection;
测试代码流程图
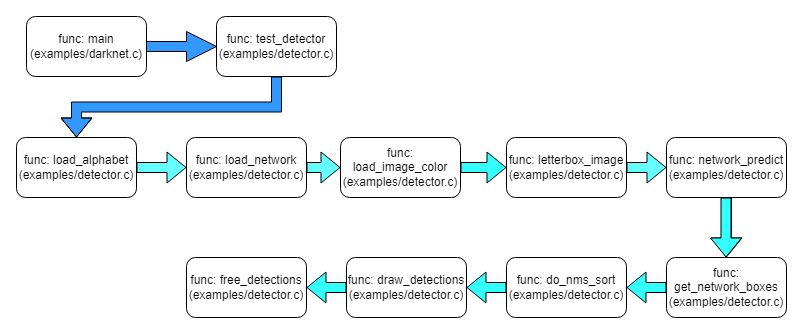
添加图像序列的测试过程
char * GetFilename(char *p) { static char name[128] = {""}; char *q = strrchr(p, '/') + 1; strcpy(name, q); return name; } // image path txt. void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen) { list *options = read_data_cfg(datacfg); char *name_list = option_find_str(options, "names", "data/names.list"); char **names = get_labels(name_list); image **alphabet = load_alphabet(); network *net = load_network(cfgfile, weightfile, 0); set_batch_network(net, 1); srand(2222222); float nms=.45; list *plist = get_paths(filename); char **paths = (char **)list_to_array(plist); double time; printf("Start Testing!\n"); int m = plist->size; if(access("/home/nvidia/project/CAP/yolov3/data/output", 0) == -1) { if(mkdir("/home/nvidia/project/CAP/yolov3/data/output", 0777)) { printf("Create file Failed!!!"); } } for(int i=0; i<m; ++i) { char *path = paths[i]; printf("paths[%d]: %s\n", i, paths[i]); image im = load_image_color(path, 0, 0); image sized = letterbox_image(im, net->w, net->h); layer l = net->layers[net->n-1]; float *X = sized.data; time = what_time_is_it_now(); network_predict(net, X); printf("%s: Predicted in %f seconds.\n", path, what_time_is_it_now()-time); int nboxes = 0; detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes); if (nms) do_nms_sort(dets, nboxes, l.classes, nms); for (int k=0; k< nboxes; k++) { box b = dets[k].bbox; printf("det[%d].bbox: x=%f, y=%f, w=%f, h=%f\n", k, b.x, b.y, b.w, b.h); for(int j=0; j<l.classes; j++) { printf("prob: %d, %f, %s\n", j, dets[k].prob[j]*100, names[j]); } } draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes); free_detections(dets, nboxes); if(outfile){ save_image(im, outfile); } else{ char b[128]; sprintf(b, "/home/nvidia/project/CAP/yolov3/data/output/%s", GetFilename(path)); save_image(im, b); printf("save %s successfully!! \n", GetFilename(path)); #ifdef OPENCV make_window("predictions", 512, 512, 0); show_image(im, "predictions", 1); #endif } free_image(im); free_image(sized); } // for loop. return; }
测试命令
./darknet detector test cfg/lisa2coco128.data cfg/yolov3-tiny-lisa.cfg weights/yolov3-tiny-lisa_10000.weights data/test.txt
test.txt表示测试图像序列文件的路径;注意文件名称的char类型的大小是否太小而导致出错;
五、优化经验
什么时候停止训练
-
avg loss不再下降的时候
-
通常每个类需要2000-4000次迭代训练即可
-
防止过拟合:需要在Early stopping point停止训练
使用以下命令:darknet.exe detector map...建议训练的时候带上-map,可以画图
-
数据集最好每个类有2000张图片,至少需要迭代2000*类的个数
-
数据集最好有没有标注的对象,即负样本,对应空的txt文件,最好有多少样本就设计多少负样本。
- 数据集添加跟正样本数量一样多的负样本
- 数据集每个类至少2000张,训练迭代次数2000*classes个数
- 设置自己数据集的anchor
六、yolov3论文阅读
优点:速度快,精度提升,小目标检测有改善;
不足:中大目标有一定程度的削弱,遮挡漏检,速度稍慢于yoloV2。
v2: anchors[k-means]+多尺度+跨尺度特征融合
v3: anchors[k-means]+多尺度+跨尺度特征融合
v2,v3两者都是有上面的共同特点,简单的多尺度不是提升小目标的检测的关键。
v2: 32x的下采样,然后使用anchor进行回归预测box
问题:较大的下采样因子,通常可以带来较大的感受野,这对于分类任务是有利,但会损害目标检测和定位【小目标在下采样过程中消失,大目标边界定位不准】
v3: 针对这个问题,进行了调整。就是在网络的3个不同的尺度进行了box的预测。【说白了就是FPN的思想】在下采样的前期就进行目标的预测,这样就可以改善小目标检测和定位问题。
不理解的话,稍微看一下FPN,就明白了。这个才是v3提升小目标的关键所在。
参考
2. yolov3_TX2;
4. yolo_homepage;
7. darknet代码解析;
8. darknet - Tiny YOLOv3 test and training (测试 and 训练);
9. yolov3批量测试并存在自己定义的路径(linux,Joseph Redmon,c版本);
10. YOLOv3:Darknet代码解析系列;
11. 目标检测:YOLOv3: 训练自己的数据;
12. Darknet 评估训练好的网络的性能;
13. Darknet YOLOv3-tiny ubuntu配置,训练自己数据集(行人检测)及调参总结;
14. Darknet YOLO 训练问题集锦;
15. 理解YOLOv2训练过程中输出参数含义;
16. Yolov3模型框架darknet研究(十二)学会看懂darknet训练log;
17. darknet源码剖析(四)do_nms_sort详解;
18. darknet优化经验;
完