

为什么要使用消息中间件
异步处理、应用解耦、流量削峰,主要作用是解决高并发的问题,设想一下服务器1秒钟一下有1亿次并发请求,那么相当于要创建1亿个线程,服务器的内存和CPU能不能扛得住呢(内存溢出和线程阻塞死机等问题);还有比如存一些用户搜素及日志记录等放在数据库会造成数据库资源浪费,放在硬盘操作效率又低,消息中间件就派上用场了。
一、RabbitMQ架构
RabbitMQ架构图
1.1 组件简介
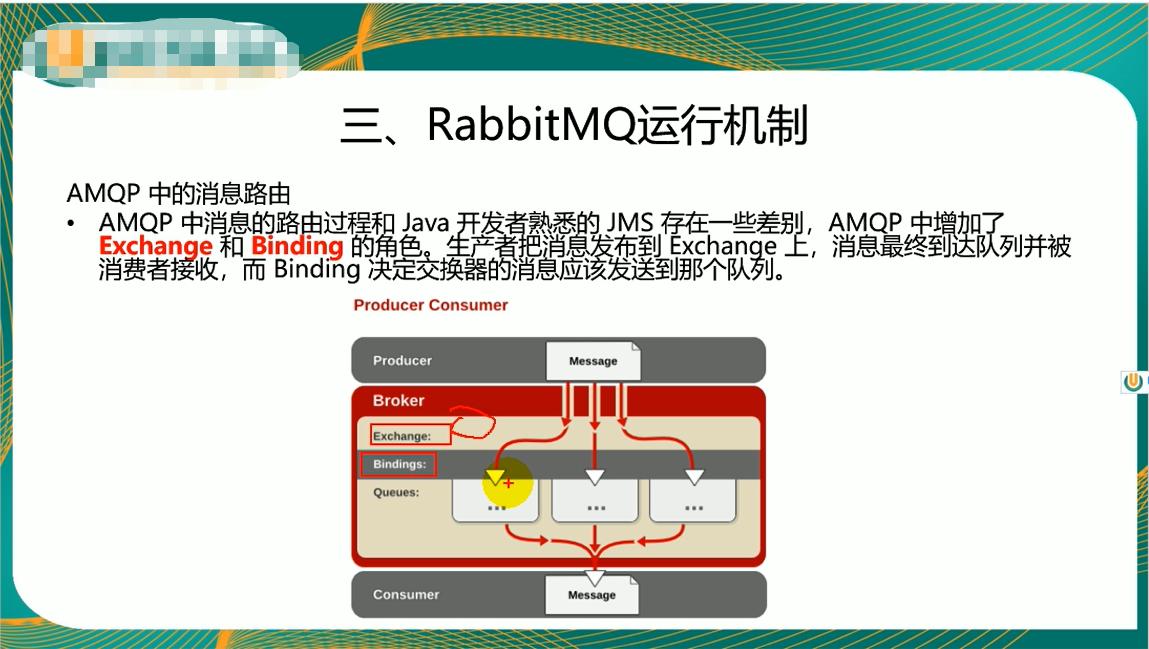
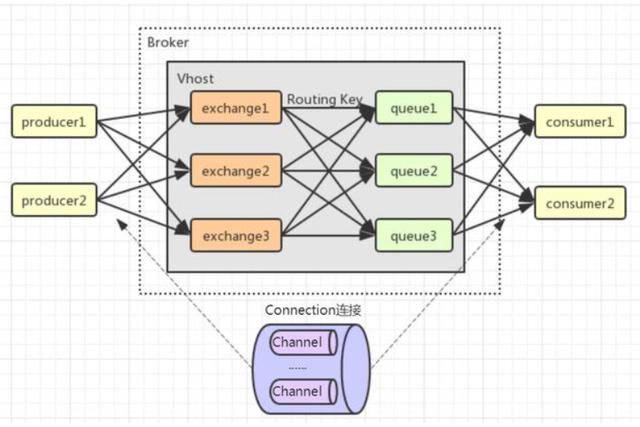
Broker核心:消息生产者和消费者都要和Broker建立Connection连接,Broker里包含了多个路由器Exchange。
Producer生产者:消息生产者将信息以及routing key路由键发送到指定路由器Exchange上。
Exchange路由器:路由器根据信息携带的routing key将消息发送到对应符合条件的Queue队列中。
Queue队列:路由和队列的对应关系需要事先进行设置,通过binding key指定绑定关系。
- master queue:每个队列都分为一个主队列和若干个镜像队列。
- mirror queue:镜像队列,作为master queue的备份。在master queue所在节点挂掉之后,系统把mirror queue提升为master queue,负责处理客户端队列操作请求。注意,mirror queue只做镜像,设计目的不是为了承担客户端读写压力。
Message:服务器和应用程序之间传送的消息,由properties和body组成。properties可以对消息进行修饰,比如消息的优先级、延迟等高级特性;body就是消息体内容。消息携带routing key,路由器会根据携带的路由关键字发送到不同队列Queue中。
1.2 Exchange和Queue绑定概念解析
绑定指的是在一个队列和一个路由器之间建立关系。绑定可以设置绑定键bindingkey,绑定键的含义及用处取决于路由器的类型,常见的路由键有以下三种:
1.2.1输出路由器(fanout exchange)
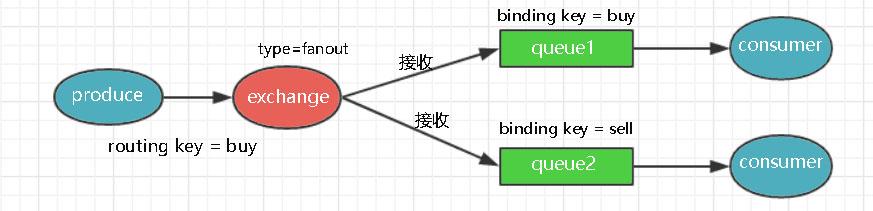
所有绑定到此exchange路由器的queue队列都可以接收消息,设置的路由键参数无效。如图3-1所示,虽然routing key与binding key匹配不上,但是因为路由器类型为fanout所以两个队列均可以收到信息。
1.2.2直接路由器(direct exchange)
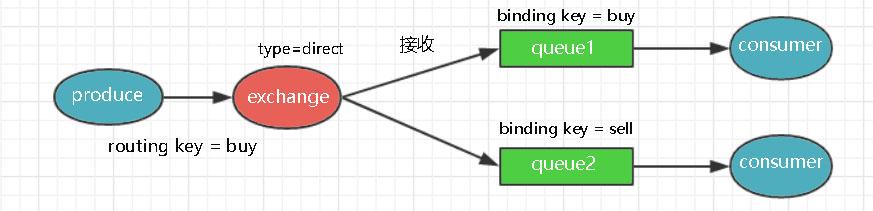
只有当消息的路由键routing key与队列的绑定键binding key完全匹配时,该消息才会进入该队列。如图3-2所示,消息携带的routingkey为"buy",当路由器类型为direct直接类型时则会根据routingkey与bindingkey进行匹配后将消息发到对应的队列里。(支持多重绑 定,既多个队列都绑定同一个bindingkey)。
1.2.3主题路由器(topic Exchange)
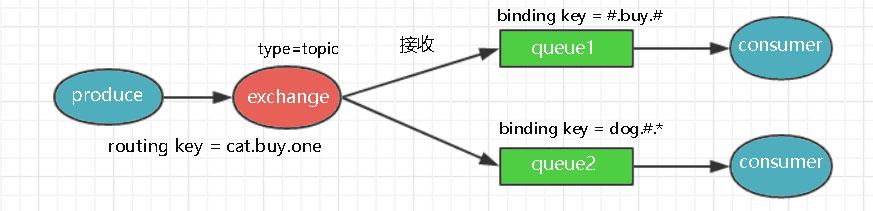
发送到topic路由器的消息路由键routing key必须是一些单词的集合,中间用点号.分开。这些单词通常会体现出消息的特征。一些有效的路由键示例:slow.green.Tortoise,quick.blue.cat。注意:路由键可以包含多个单词,总长度不能超过255个字节。
绑定键binding key也必须是这种形式。以特定路由键发送的消息将会发送到所有绑定键与之匹配的队列中。但绑定键有两种特殊的表示:
*(星号)仅代表一个单词
#(井号)代表任意个单词
二、RabbitMQ消息丢失场景及解决方案
2.1、为什么会丢失消息
rabbitmq在整个消息流转过程中,生产者,rabbitmq服务,消费者由于突然终止或者发生异常,消息无法正常送达下一步,导致消息丢失。
2.2、消息丢失场景
2.2.1、生产者发送消息到RabbitMQ Server消息丢失场景
2.2.1.1、中途网络异常等原因导致消息没有进入Broker
解决方法:
(1)发送方确认机制confirm:
可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你说这个消息ok了。如果rabbitmq没能处理这个消息,
会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息id的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。事务机制和cnofirm机制最大的不同在于,
事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息rabbitmq接收了之后会异步回调你一个接口通知你这个消息接收到了。
所以一般在生产者这块避免数据丢失,都是用confirm机制的。
Confirm的三种实现方式:
方式一:channel.waitForConfirms()普通发送方确认模式;
方式二:channel.waitForConfirmsOrDie()批量确认模式;
方式三:channel.addConfirmListener()异步监听发送方确认模式;(掌握)
方式一:普通Confirm模式

看代码可以知道,我们只需要在推送消息之前,channel.confirmSelect()声明开启发送方确认模式,再使用channel.waitForConfirms()等待消息被服务器确认即可。
方式二:批量Confirm模式

以上代码可以看出来channel.waitForConfirmsOrDie(),使用同步方式等所有的消息发送之后才会执行后面代码,只要有一个消息未被确认就会抛出IOException异常。相比普通confirm模式,批量可以极大提升confirm效率,
但是一旦出现confirm返回false或者超时的情况时,客户端需要将这一批次的消息全部重发,这会带来明显的重复消息数量,并且当消息经常丢失时,批量confirm性能应该是不升反降的。
方式三:异步Confirm模式(掌握)

异步模式的优点,就是执行效率高,不需要等待消息执行完,只需要监听消息即可,性能会大幅度提升,发送完毕之后,可以继续发送其他消息。
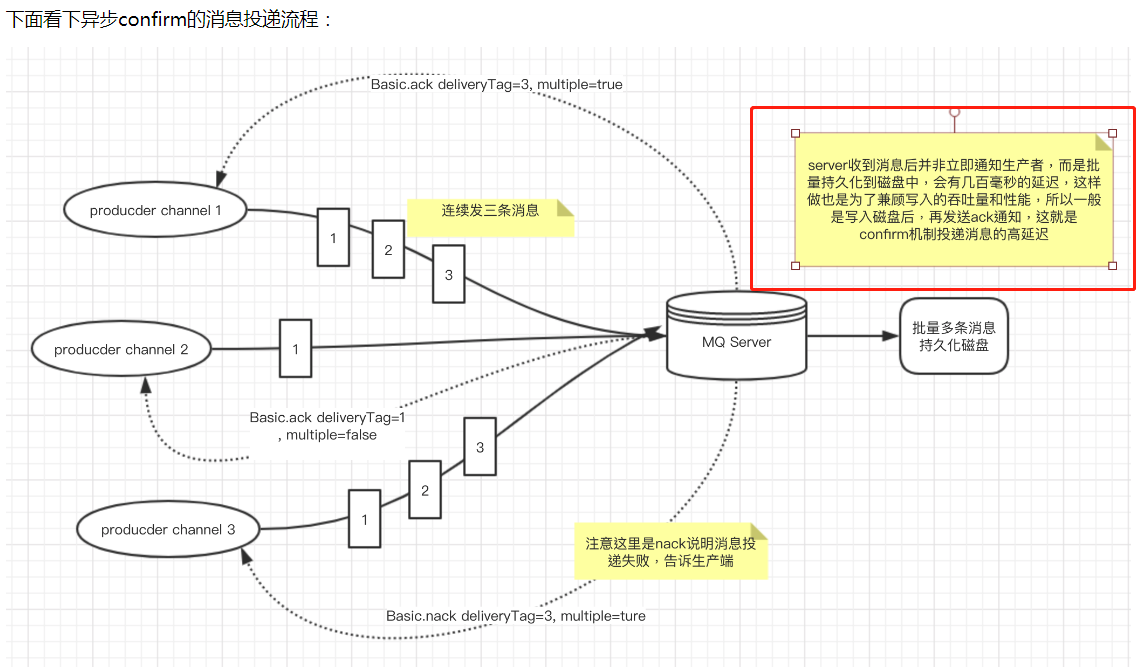
解释下这张图片:
channel1 连续发类1,2,3条消息到RabbitMQ-Server,RabbitMQ-Server通知返回一条通知,里面包含回传给生产者的确认消息中的deliveryTag包含了确认消息的序号,此外还有一个参数multiple=true,
表示到这个序号之前的所有消息都已经得到了处理。
channel3 发送的消息失败了,生产端需要对投递消息重新投递,需要额外处理代码。 那么生产端需要做什么事情呢?因为是异步的,生产端需要存储消息然后根据server通知的消息,确认如何处理,于是我们面临的问题是:
第一:发送消息之前把消息存起来
第二:监听ack 和 nack 并做响应处理
那么怎么存储呢?我们分析下,可以使用SortedMap 存储,保证有序,但是有个问题高并发情况下,每秒可能几千甚至上万的消息投递出去,消息的ack要等几百毫秒的话,放内存可能有内存溢出的风险。所以建议采用KV存储,
KV存储承载高并发能力高,性能好,但是要保证KV 高可用。
(2)事务机制
事务的实现主要是对信道(Channel)的设置,主要的方法有三个:
channel.txSelect()声明启动事务模式;
channel.txComment()提交事务;
channel.txRollback()回滚事务;

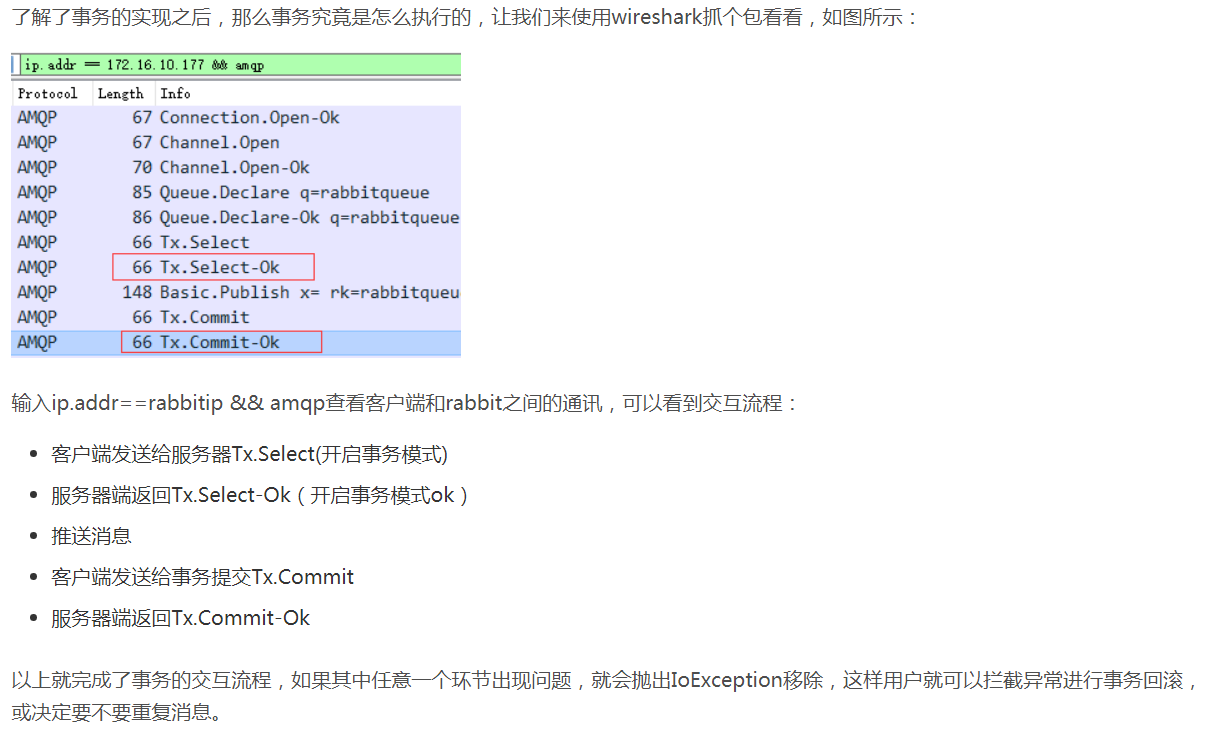
但是,很少有人这么干,因为事务是同步操作,一条消息发送之后会使发送端阻塞,以等待RabbitMQ Server的回应,之后才能继续发送下一条消息,
生产者生产消息的吞吐量和性能都会大大降低。
那么,既然已经有事务了,没什么还要使用发送方确认模式呢,原因是因为事务的性能是非常差的。事务性能测试:
事务模式,结果如下:
事务模式,发送1w条数据,执行花费时间:14197s
事务模式,发送1w条数据,执行花费时间:13597s
事务模式,发送1w条数据,执行花费时间:14216s
非事务模式,结果如下:
非事务模式,发送1w条数据,执行花费时间:101s
非事务模式,发送1w条数据,执行花费时间:77s
非事务模式,发送1w条数据,执行花费时间:106s
2.2.1.2、消息routing_key不存在,生产者发送消息到exchange后,发送的路由和queue没有对应的绑定,这样默认消息会被扔掉。
解决方法:
(1)设置mandatory=True。交换器无法根据自身的类型和路由键找到一个符合条件的队列时,RabbitMQ 会调用Basic.Return 命令将消息返回给生产者,mandatory=False,直接丢弃。
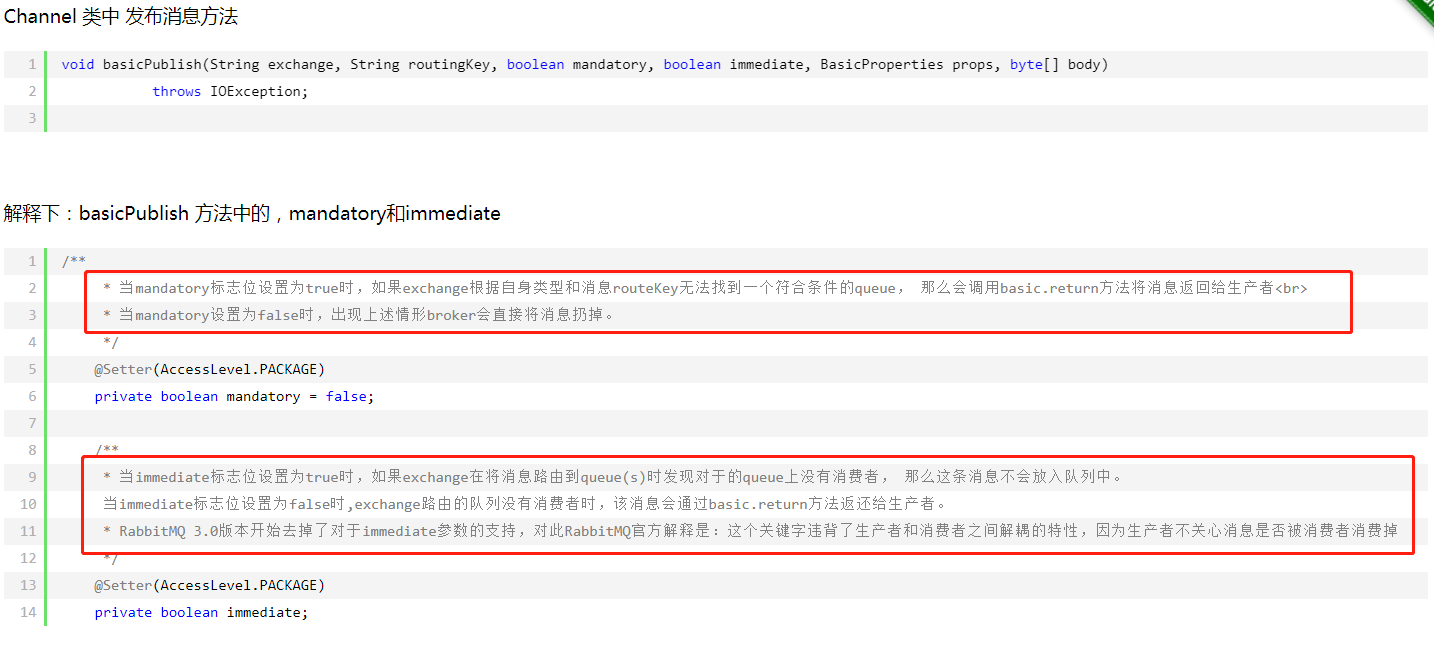
所以为了保证消息的可靠性,需要设置发送消息代码逻辑。如果不单独形式设置mandatory=false使用mandatory 设置true的时候有个关键点要调整,生产者如何获取到没有被正确路由到合适队列的消息呢?
通过调用channel.addReturnListener来添加ReturnListener监听器实现,只要发送的消息,没有路由到具体的队列,ReturnListener就会收到监听消息。

(2)利用备份交换机(alternate-exchange):实现没有路由到队列的消息
此时有人问了,不想复杂化生产者的编程逻辑,又不想消息丢失,那么怎么办? 还好RabbitMQ提供了一个叫做alternate-exchange东西,翻译下就是备份交换器,这个干什么用呢?
很简单,它可以将未被路由的消息存储在另一个exchange队列中,再在需要的时候去处理这些消息。那如何实现呢?简单一点可以通过webui管理后台设置,当你新建一个exchange业务的时候,
可以给它设置Arguments,这个参数就是 alternate-exchange,其实alternate-exchange就是一个普通的exchange,类型最好是fanout 方便管理

2.2.2、RabbitMQ Server中存储的消息丢失场景,可能引起消息丢失的异常:服务异常退出重启后,exchange,queue,message丢失
解决方法:
持久化
消息持久化,队列持久化,交换器持久化
队列持久化:定义队列时,设置队列的durable=True。服务重启后,队列不会丢失。
交换器持久化:定义交换器时,设置durable=True。服务重启后,交换器元数据不会丢失。
消息持久化: 将投递模式设置为2即可。服务重启后,队列里的消息不会丢失。
高可用 设置 镜像队列
为了防止rabbitmq自己弄丢了数据,这个你必须开启rabbitmq的持久化,就是消息写入之后会持久化到磁盘,哪怕是rabbitmq自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,
rabbitmq还没持久化,自己就挂了,可能导致少量数据会丢失的,但是这个概率较小。设置持久化有两个步骤,第一个是创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,
但是不会持久化queue里的数据;第二个是发送消息的时候将消息的deliveryMode设置为2,就是将消息设置为持久化的,此时rabbitmq就会将消息持久化到磁盘上去。必须要同时设置这两个持久化才行,rabbitmq哪怕是挂了,
再次重启,也会从磁盘上重启恢复queue,恢复这个queue里的数据。而且持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack了,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,
数据丢了,生产者收不到ack,你也是可以自己重发的。若生产者那边的confirm机制未开启的情况下,哪怕是你给rabbitmq开启了持久化机制,也有一种可能,就是这个消息写到了rabbitmq中,但是还没来得及持久化到磁盘上,
结果不巧,此时rabbitmq挂了,就会导致内存里的一点点数据会丢失。
2.2.3、消费端的消息丢失场景,可能引起消息丢失的异常:消费端取到消息后进程退出,重启
解决方法:
ack机制,设置autoAck=False,关闭自动ack, 真正处理完成后,手动发送完成确认。如果没有ack确认且当前消费者链接断开,任务会重新进入队列。主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了比如重启了,
那么就尴尬了,RabbitMQ认为你都消费了,这数据就丢了。或者消费者拿到数据之后挂了,这时候需要MQ重新指派另一个消费者去执行任务,这个时候得用RabbitMQ提供的ack机制,也是一种处理完成发送回执确认的机制。
如果MQ等待一段时间后你没有发送过来处理完成那么RabbitMQ就认为你还没处理完,这个时候RabbitMQ会把这个消费分配给别的consumer去处理,消息是不会丢的。
PS: ack使用导致异常
(1).autoAck=True 消息丢失 改为False,手动ack时,如果忘记ack,导致大量任务都处于Unacked状态,造成队列堆积,直至消费者断开才会重新回到队列。
解决方法:及时ack,确保异常时ack或者拒绝消息.。
(2).启用消息拒绝或者发送nack后导致死循环,如果在消息处理异常时,直接拒绝消息,消息会重新进入队列。这时候如果消息再次被处理时又被拒绝 。这样就会形成死循环。
解决方法:开启死信队列 并设置nack,reject的requeue=False。这时当消息被拒绝或者nack时会被送入死信队列。(消息过期,nack,reject,队列最大长度 这些情况,如果开启了死信队列,消息都会进入死信队列)。
分析死信队列上的异常情况可以用来改善和优化系统。