本章开始我们正式进入到实战项目开发过程,如何从需求分析获得的实体数据转到模型设计中来,变成Django项目中得模型层。当然,第一步还是在VS2019 IDE环境重创建一个工程项目,本文我们把工程名称命名为IndDemo,如下图:
VS2019创建的Django项目结构如下图
现在按F5调试程序,又来到Django熟悉的欢迎页面了。
接下来让开始这趟实战之旅吧!
1.1. 实体关系图
从上一章需求涉及到的实体,来构建我们的实体关系图吧,这里的步骤也相当于早期开发设计的表结构设计,只是如前面章节说的有了ORM机制后,我们讨论采用对象模型来设计和讨论实体可能更适合于实际的场景讨论,便于团队在同一个频道下沟通,当然这里实质上与表设计没有太多本质的区别,但是多对多等中间表在实体关系图中就看不到了,表结构设计时就不能忽略这个中间表的存在。产品经理更专注于需求而不是数据库存储结构是不是更符合专业分工?开发人员也不用大费周章来折腾表结构的优化了。嗯,这些可以丢给DBA来优化吧。
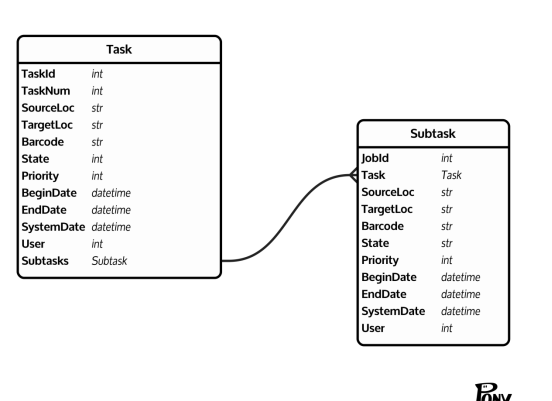
本图采用网址ponyorm网站在线绘制,网址:https://editor.ponyorm.com/.
1.2. Django model层
为了便于对照学习和理解,我们新增一个新的APP 命名为:Task来专门处理这个业务,不修改默认的APP里的代码,也便于过程中可以通过这个默认APP功能,参照它的结构和语法等。
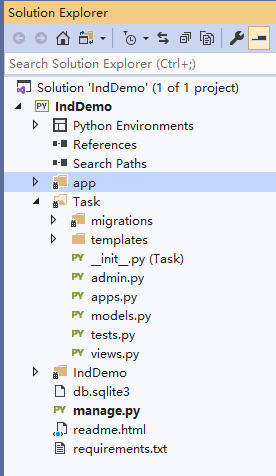
现在我们的工程目录结构如下:
打开Task.models.py文件编写我们实体关系图的模型代码吧,作者本人比较习惯“大驼峰”命名法也就是首字母都大写的模式TaskNum,后面很多命名都会采用这个方式,不采用python主流的蛇形命名法的task_num方式,纯属个人习惯。我们依据设计我们开始构建我们的model代码如下:
from django.db import models from django.contrib.auth.models import User PRIORITY=((1,u'正常'),(2,u'急'),(3,u'紧急')) class Task(models.Model): TASK_STATE=((1,u'未处理'),(4,u'处理成功'),(5,u'执行中'),(99,u'完成'),(-1,u'已取消')) TaskId = models.AutoField(primary_key=True, db_column='task_id') TaskNum = models.IntegerField(u'任务号', null=False, db_column='task_num') Source = models.CharField(u'源地址', null=False, max_length=50, db_column='source') Target = models.CharField(u'目标地址', null=False, max_length=50, db_column='target') Barcode = models.CharField(u'容器条码', null=False, max_length=50, db_column='barcode') State = models.IntegerField(u'状态', choices=TASK_STATE, null=False, db_column='state') Priority = models.IntegerField(u'优先级', choices=PRIORITY, null=True, db_column='priority') BeginDate = models.DateTimeField(u'开始时间',null=True, db_column='begin_date') EndDate = models.DateTimeField(u'结束时间',null=True, db_column='end_date') SystemDate = models.DateTimeField(u'系统时间', null=False, auto_now_add=True, db_column='system_date') User = models.ForeignKey(User, verbose_name="操作员", on_delete=models.CASCADE,db_column='user_id') class Meta: db_table = 'task_task' ordering = ['-Priority','TaskId'] verbose_name = verbose_name_plural = "任务" def __str__(self): return str(self.TaskNum) class Job(models.Model): JOB_STATE=((1,u'新作业'),(2,u'下达执行'), (99,u'完成'),(-1,u'已取消')) JobId = models.AutoField(primary_key=True, db_column='job_id') Task = models.ForeignKey('Task', verbose_name="任务", blank=True, on_delete=models.CASCADE) TaskNum = models.IntegerField(u'任务号', null=False, db_column='task_num') OrderNo = models.IntegerField(u'顺序号', null=False, db_column='order_no') Source = models.CharField(u'源地址', null=True, max_length=50, db_column='source') Target = models.CharField(u'目标地址', null=True, max_length=50, db_column='target') Executor = models.CharField(u'执行器', null=False,blank=True, max_length=50, db_column='executor') State = models.IntegerField(u'状态', choices=JOB_STATE, null=False, db_column='state') Priority = models.IntegerField(u'优先级', choices=PRIORITY, null=True, db_column='priority') BeginDate = models.DateTimeField(u'开始时间',null=True, db_column='begin_date') EndDate = models.DateTimeField(u'结束时间',null=True, db_column='end_date') SystemDate = models.DateTimeField(u'系统时间', null=False, auto_now_add=True, db_column='system_date') Barcode = models.CharField(u'条码', null=False, max_length=50, db_column='barcode') User = models.ForeignKey(User, verbose_name="操作员", on_delete=models.CASCADE,db_column='user_id') class Meta: db_table = 'task_job' ordering = ['JobId'] verbose_name = verbose_name_plural = "作业" def __str__(self): return str(self.TaskNum) +'-'+str(self.OrderNo)
1.3. make migrations创建数据库迁移
首先,我们在项目的settings.py文件里登记我们新增加的APP,代码如下:
INSTALLED_APPS = [ 'app', 'Task', # Add your apps here to enable them 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]
然后,在IDE通过菜单就可以创建新建model产生的数据库迁移,如下图:
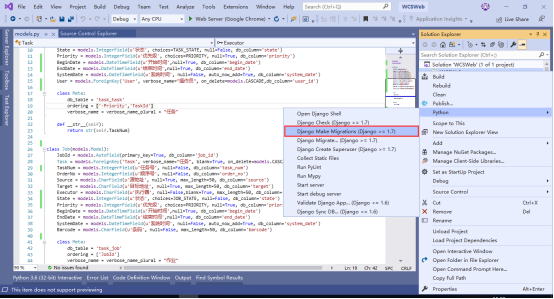
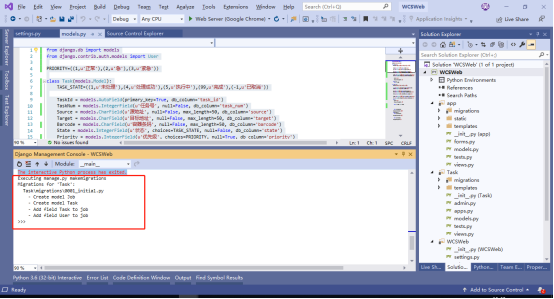
1.4. migrate 迁移数据库
同样在IDE窗口可以直接执行迁移命令,执行完数据迁移命令,工程默认链接的SQLite数据库就包含这次我们创建的数据表了。

通过数据库工具查看数据文件里面的表创建情况。
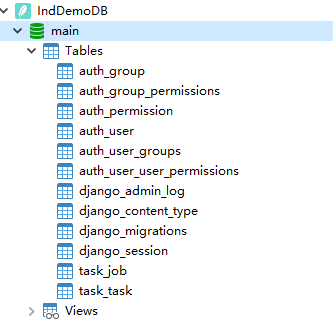
1.5. Create Superuser
由于我们的model Task中定义了User这个引用django.contrib.auth.models.User的外键非空属性,我们需要创建一个Django Admin的超级用户,才能正常的保存Task 模型。
按照命令提示创建好超级用户我们就可以通过ORM操作数据库了。
1.6. Django ORM操作
Django ORM提供了诸多的API接口,详情请参考官网文档或网上教程,笔者的项目实战也是遇到某类问题了,也是大量通过搜索引擎来找到相关的使用方法来改进功能代码的。 实战项目使用到ORM的操作很多,未来我们会逐步的使用到时,会进一步说明。本章节只举一些常用的例子。
通过ORM我们可以不关心数据库表结构,采用ORM机制就可以CRUD表里的数据了,数据将按照对象的方式的方式返回。
1.返回所有的Task对象
>>> from Task.models import Task >>> Task.objects.all() <QuerySet []>
2.新增Task对象
>>> a=Task(None,'1001','121','1-1-1001','2002001',1,1,None,None,None,1) >>> a.save() >>> Task.objects.all() <QuerySet [<Task: 1001>]>
通过数据库工具也能看到这条新创建的Task

3.通过TaskId获取Task对象
>>> Task.objects.filter(pk=1)
<QuerySet [<Task: 1001>]>
>>> Task.objects.get(TaskId=1)
<Task: 1001>
注意上面get方法的两个不同的属性
4.通过dict对象创建Task对象,这个模式后面用在以Json格式从前台提交数据会非常方便
>>>data={"TaskNum":"1002","Source":"122","Target":"1-1-1002","Barcode":"2002002","State":1,"Priority":1,"User_id":1}
>>> model=Task(**data)
>>> model.save()
>>> Task.objects.all()
<QuerySet [<Task: 1001>, <Task: 1002>]>
注意:User外键对象必须通过_id赋值"User_id":1,通常在变量前加一个星号(*)表示这个变量是元组/列表,加两个星号表示这个参数是字典。
5.匹配条件
>>> Task.objects.filter(TaskNum='1001') <QuerySet [<Task: 1001>]>
6.不匹配条件
>>> Task.objects.exclude(TaskNum='1001') <QuerySet [<Task: 1002>]>
7.获取单条数据(主键唯一)
>>> Task.objects.get(pk=1) <Task: 1001> >>> Task.objects.get(TaskId=1) <Task: 1001>
8.大于 __gt
>>> Task.objects.filter(pk__gt=1)
<QuerySet [<Task: 1002>]>
9.大于等于 __gte
>>> Task.objects.filter(pk__gte=1)
<QuerySet [<Task: 1001>, <Task: 1002>]>
10.小于 __lt
>>> Task.objects.filter(pk__lt=2)
<QuerySet [<Task: 1001>]>
11.小于等于 __lte
>>> Task.objects.filter(pk__lte=2)
<QuerySet [<Task: 1001>, <Task: 1002>]>
12.大于和小于, 1 < TaskId < 5
>>> Task.objects.filter(pk__gt=1,pk__lt=5)
<QuerySet [<Task: 1002>]>
13.包含 __in []
>>> Task.objects.filter(pk__in=[1,2,3,4,5])
<QuerySet [<Task: 1001>, <Task: 1002>]>
14.不包含,not in
>>> Task.objects.exclude(pk__in=[2,3,4,5])
<QuerySet [<Task: 1001>]>
15.为空:isnull=True
>>> Task.objects.filter(BeginDate__isnull=True)
<QuerySet [<Task: 1001>, <Task: 1002>]>
16.匹配,大小写敏感 __contains
>>> Task.objects.filter(Barcode__contains="2001") <QuerySet [<Task: 1001>]>
17.匹配,大小写不敏感 __icontains
>>> Task.objects.filter(Barcode__icontains="2001") <QuerySet [<Task: 1001>]>
18.范围,__range
>>> Task.objects.filter(pk__range=[2,6])
<QuerySet [<Task: 1002>]>
19.排序,order by
>>> Task.objects.all().order_by('pk') <QuerySet [<Task: 1001>, <Task: 1002>]>
20.倒排序,order by
>>> Task.objects.all().order_by('-pk') <QuerySet [<Task: 1002>, <Task: 1001>]>
更多的ORM查询操作查阅官网文档,上面是业务编程过程用得比较多的一些过滤查询方法。
1.7. 小节
本章我们着重在通过构建实体和实体关系图,实体的属性通常来自业务需求分析和设计时增加的一些必要的字段,如:时间戳、创建对象的用户等就是为了便于查找、定位、过滤数据,以及业务管理上考虑必要增加的一些多出来的实体属性。这里笔者由于历史习惯,表字段命名又采用蛇形命名法,所以增加了一个强制字段名称的属性db_column='user_id'都是个人习惯缘故,如果全部采用蛇形命名法这个属性就可以去掉了。完成了model的构建后,我们就可以进行展开业务逻辑的开发了。
下一章我们讲讲Django后台开发的利器 Django Admin,来快速的构建一个后台管理框架,你会发现Django给我们省了好多好多事情。