目录
- 1、Ceph简介
- 2、Ceph的特点
- 3、Ceph的缺点
- 4、架构与组件
- 5、部署
- 5.1 设置主机名、配置时间同步
- 5.2 配置添加清华源
- 5.3 初始化ceph用户
- 5.4 设置免密登录
- 5.5 校验源是否生效
- 5.6 初始化ceph的配置文件
- 5.7 选择性安装ceph-common
- 5.8 初始化ceph-node节点
- 5.9 对mon节点进行初始化:
- 5.10 分发admin的密钥
- 5.11 配置mgr节点
- 5.12 推动证书给部署节点
- 5.13 列出 ceph node 节点磁盘
- 5.14 擦除磁盘:
- 5.15 添加主机的磁盘osd:
- 5.16 禁用非安全模式通信
- 5.17 mon服务器的高可用:
- 5.18 mgr服务器的高可用:
- 5.19 osd添加
- 5.20 模拟osd下线
- 5.21 模拟osd 上线
- 5.22 客户端使用块存储
- 5.23 取消映射块设备
- 5.24 删除块设备,执行以下命令
1、Ceph简介
Ceph提供了对象、块、和文件存储功能,同时在扩展性上又可支持数以千计的客户端访问到PB级EB级甚至更多的数据。它不但适应非结构化数据,并且客户端可以同时使用当前及传统的对象接口进行数据存取,被称为是存储的未来!
2、Ceph的特点
- 高可用:Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以分隔故障域, 可以忍受多种故障场景并自动尝试并行修复。同时支持强一致副本,而副本又能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自管理、自动修复。无单点故障,有很强的容错性;
- 高扩展性:Ceph不同于swift,客户端所有的读写操作都要经过代理节点。一旦集群并发量增大时,代理节点很容易成为单点瓶颈。Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,它的性能会随着磁盘数量的增加而线性增长;
- 特性丰富:Ceph支持三种调用接口:对象存储,块存储,文件系统挂载。三种方式可以一同使用。Ceph统一存储,虽然Ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口;
- 统一的存储:能同时提供对象存储、文件存储和块存储;
- CRUSH算法:Ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。CRUSH在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。Ceph会将CRUSH规则集分配给存储池。当Ceph客户端存储或检索存储池中的数据时,Ceph会自动识别CRUSH规则集、以及存储和检索数据这一规则中的顶级bucket。当Ceph处理CRUSH规则时,它会识别出包含某个PG的主OSD,这样就可以使客户端直接与主OSD进行连接进行数据的读写。
3、Ceph的缺点
- 需要比较强的技术能力和运维能力
- 数据一致性问题。对于ORACLE RAC这一类对数据一致性要求比较高的应用场景,分布式存储的性能可能就稍弱了,因为分布式的结构,数据同步是一个大问题,虽然现在技术一致在进步,但是也不如传统存储设备数据存储方式可靠。
- 稳定性问题,分布式存储非常依赖网络环境和带宽,如果网络发生抖动或者故障,都可能会影响分布式存储系统运行。例如,一旦发生IP冲突,那么整体分布式存储可能都无法访问。传统存储一般使用专用SAN或IP网络,稳定性方面,更可靠一些。
4、架构与组件
官网地址是:https://docs.ceph.com/en/nautilus/architecture/
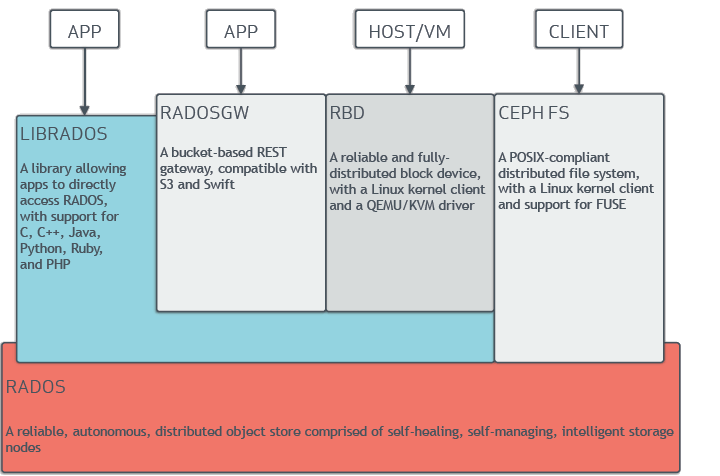
4.1、组件介绍
- Ceph的底层是RADOS,RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现。RADOS采用C++开发,所提供的原生Librados API包括C和C++两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
- RADOS向外界暴露了调用接口,即LibRADOS,应用程序只需要调用LibRADOS的接口,就可以操纵Ceph了。这其中,RADOS GW用于对象存储,RBD用于块存储,它们都属于LibRADOS;CephFS是内核态程序,向外界提供了POSIX接口,用户可以通过客户端直接挂载使用。
- RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
- CEPHFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所以无需调用用户空间的librados库。它通过内核中的net模块来与Rados进行交互。
- RBD块设备。对外提供块存储。可以像磁盘一样被映射、格式化已经挂载到服务器上。支持snapshot
4.2、存储过程

- 无论使用哪种存储方式(对象、块、挂载),存储的数据都会被切分成对象(Objects)。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。ino即是文件的File ID,用于在全局唯一标示每一个文件,而ono则是分片的编号。比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。Oid的好处是可以唯一标示每个不同的对象,并且存储了对象与文件的从属关系。由于ceph的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高。 但是对象并不会直接存储进OSD中,因为对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。这么多对象光是遍历寻址,速度都是很缓慢的;并且如果将对象直接通过某种固定映射的哈希算法映射到osd上,当这个osd损坏时,对象无法自动迁移至其他osd上面(因为映射函数不允许)。为了解决这些问题,ceph引入了归置组的概念,即PG
- PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。 对象时如何映射进PG的?还记得OID么?首先使用静态hash函数对OID做hash取出特征码,用特征码与PG的数量去模,得到的序号则是PGID。由于这种设计方式,PG的数量多寡直接决定了数据分布的均匀性,所以合理设置的PG数量可以很好的提升CEPH集群的性能并使数据均匀分布
- 最后PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
5、部署
本次使用的虚拟机部署(Ubuntu18.04)Ceph版本为目前最新的P版本
规划的主机如下
5.1 设置主机名、配置时间同步
172.31.1.100 ceph-deploy.example.local ceph-deploy #部署节点
172.31.1.101 ceph-mon1.example.local ceph-mon1
172.31.1.102 ceph-mon2.example.local ceph-mon2
172.31.1.103 ceph-mon3.example.local ceph-mon3
172.31.1.104 ceph-mgr1.example.local ceph-mgr1
172.31.1.105 ceph-mgr2.example.local ceph-mgr2
172.31.1.106 ceph-node1.example.local ceph-node1
172.31.1.107 ceph-node2.example.local ceph-node2
172.31.1.108 ceph-node3.example.local ceph-node3
echo "*/5 * * * * /usr/sbin/ntpdate ntp.aliyun.com &> /dev/null" | crontab
5.2 配置添加清华源
#allnode sudo wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
#allnode sudo echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
5.3 初始化ceph用户
#deploy-node groupadd -r -g 2023 magedu && useradd -r -m -s /bin/bash -u 2023 -g 2023 magedu && echo magedu:123456 | chpasswd
#all-node groupadd -r -g 2021 ceph && useradd -r -m -s /bin/bash -u 2021 -g 2021 ceph && echo ceph:123456 | chpasswd
#deploy-node echo "magedu ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
5.4 设置免密登录
root@ceph-deploy:~# su - magedu
magedu@ceph-deploy:~$ ssh-keygen
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.100
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.101
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.102
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.103
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.104
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.105
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.106
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.107
magedu@ceph-deploy:~$ ssh-copy-id magedu@172.31.1.108
5.5 校验源是否生效
root@ceph-deploy:~# apt-cache madison ceph-deploy #查看添加的清华源是否生效,如果出现报错无法识别清华源需执行以下操作
sudo gpg --keyserver keyserver.ubuntu.com --recv E84AC2C0460F3994
sudo gpg --export --armor E84AC2C0460F3994 | sudo apt-key add -
sudo apt-get update
root@ceph-deploy:~# sudo apt install ceph-deploy
root@ceph-deploy:~# su - magedu
magedu@ceph-deploy:~$ mkdir ceph-cluster
magedu@ceph-deploy:~$ cd ceph-cluster/
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy --help
5.6 初始化ceph的配置文件
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy new --cluster-network 172.31.1.0/24 --public-network 192.168.43.0/24 ceph-mon1
5.7 选择性安装ceph-common
#allnode apt install -y ceph-common
# apt install ceph-mon #在mon节点安装,使用root或者具备sudo权限的普通用户
# apt install ceph-mgr #在mgr节点安装
5.8 初始化ceph-node节点
在添加 osd 之前,对node节点安装基本环境: (以下俩条2选一执行)
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 #这留一个ceph-node3一会添加
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node1 #擦除磁盘之前通过 deploy 节点对 node 节点执行安装 ceph 基本运行环境
5.9 对mon节点进行初始化:
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy mon create-initial
5.10 分发admin的密钥
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-mon1 ceph-node1 ceph-node2
#allnode chown -R ceph.ceph /etc/ceph/*
5.11 配置mgr节点
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr1
5.12 推动证书给部署节点
magedu@ceph-deploy:~/ceph-cluster$ apt install ceph-common
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-deploy #推送证书 给自己
root@ceph-deploy:~# chown -R magedu.magedu /etc/ceph/*
magedu@ceph-deploy:~/ceph-cluster$ ceph -s #这里就能看到集群状态了
5.13 列出 ceph node 节点磁盘
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list ceph-node1
5.14 擦除磁盘:
ceph-deploy disk zap ceph-node1 /dev/sdb
ceph-deploy disk zap ceph-node1 /dev/sdc
ceph-deploy disk zap ceph-node2 /dev/sdb
ceph-deploy disk zap ceph-node2 /dev/sdc
# 以下未执行初始化过的就不能执行磁盘格式化
ceph-deploy disk zap ceph-node3 /dev/sdb
ceph-deploy disk zap ceph-node3 /dev/sdc
5.15 添加主机的磁盘osd:
osd的id从0开始顺序使用 0-1
ceph-deploy osd create ceph-node1 --data /dev/sdb
ceph-deploy osd create ceph-node1 --data /dev/sdc
2-3
ceph-deploy osd create ceph-node2 --data /dev/sdb
ceph-deploy osd create ceph-node2 --data /dev/sdc
4-5
ceph-deploy osd create ceph-node3 --data /dev/sdb
ceph-deploy osd create ceph-node3 --data /dev/sdc
magedu@ceph-deploy:~/ceph-cluster$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.03918 root default
-3 0.01959 host ceph-node1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-5 0.01959 host ceph-node2
2 hdd 0.00980 osd.2 up 1.00000 1.00000
3 hdd 0.00980 osd.3 up 1.00000 1.00000
5.16 禁用非安全模式通信
magedu@ceph-deploy:~/ceph-cluster$ ceph config set mon auth_allow_insecure_global_id_reclaim false
magedu@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: cce50457-e522-4841-9986-a09beefb2d65
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-mon1 (age 30m)
mgr: ceph-mgr1(active, since 20m)
osd: 4 osds: 4 up (since 4m), 4 in (since 4m); 1 remapped pgs
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 20 MiB used, 40 GiB / 40 GiB avail
pgs: 1 active+clean
magedu@ceph-deploy:~/ceph-cluster$ ceph health
HEALTH_OK
5.17 mon服务器的高可用:
mon_node apt install ceph-mon
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy mon add ceph-mon2
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy mon add ceph-mon3
magedu@ceph-deploy:~/ceph-cluster$ ceph quorum_status --format json-pretty
5.18 mgr服务器的高可用:
mon_node apt install ceph-mgr
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr2
magedu@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: cce50457-e522-4841-9986-a09beefb2d65
health: HEALTH_WARN
clock skew detected on mon.ceph-mon2, mon.ceph-mon3
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 11m)
mgr: ceph-mgr1(active, since 35m), standbys: ceph-mgr2
osd: 4 osds: 4 up (since 18m), 4 in (since 18m); 1 remapped pgs
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 20 MiB used, 40 GiB / 40 GiB avail
pgs: 1 active+clean
5.19 osd添加
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node3
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node3 /dev/sdb
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node3 /dev/sdc
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdb
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdc
5.20 模拟osd下线
magedu@ceph-deploy:~/ceph-cluster$ ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.00980 1.00000 10 GiB 5.4 MiB 296 KiB 0 B 5.1 MiB 10 GiB 0.05 1.01 1 up
1 hdd 0.00980 1.00000 10 GiB 5.4 MiB 296 KiB 0 B 5.1 MiB 10 GiB 0.05 1.01 0 up
2 hdd 0.00980 1.00000 10 GiB 5.4 MiB 296 KiB 0 B 5.1 MiB 10 GiB 0.05 1.00 0 up
3 hdd 0.00980 1.00000 10 GiB 5.4 MiB 296 KiB 0 B 5.1 MiB 10 GiB 0.05 1.00 1 up
4 hdd 0.00980 1.00000 10 GiB 5.3 MiB 296 KiB 0 B 5 MiB 10 GiB 0.05 0.99 0 up
5 hdd 0.00980 1.00000 10 GiB 5.2 MiB 296 KiB 0 B 4.9 MiB 10 GiB 0.05 0.98 1 up
TOTAL 60 GiB 32 MiB 1.7 MiB 0 B 30 MiB 60 GiB 0.05
MIN/MAX VAR: 0.98/1.01 STDDEV: 0
1. 停用设备:ceph osd out {osd-num}
magedu@ceph-deploy:~/ceph-cluster$ ceph osd out 0
marked out osd.0.
2. 停止进程:sudo systemctl stop ceph-osd@{osd-num}
root@ceph-node1:~# systemctl stop ceph-osd@0
root@ceph-node1:~# systemctl status -l ceph-osd@0
● ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; indirect; vendor preset: enabled)
Active: inactive (dead) since Sun 2021-08-15 19:07:15 CST; 9s ago
Process: 24575 ExecStart=/usr/bin/ceph-osd -f --cluster ${CLUSTER} --id 0 --setuser ceph --setgroup ceph (code=exited, status=0/SUCCESS)
Main PID: 24575 (code=exited, status=0/SUCCESS)
3. 移除设备:ceph osd purge {id} --yes-i-really-mean-it
magedu@ceph-deploy:~/ceph-cluster$ ceph osd purge 0 --yes-i-really-mean-it
purged osd.0
4. 验证是否执行成功
magedu@ceph-deploy:~/ceph-cluster$ ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
1 hdd 0.00980 1.00000 10 GiB 5.5 MiB 328 KiB 0 B 5.2 MiB 10 GiB 0.05 1.02 1 up
2 hdd 0.00980 1.00000 10 GiB 5.5 MiB 328 KiB 0 B 5.1 MiB 10 GiB 0.05 1.00 0 up
3 hdd 0.00980 1.00000 10 GiB 5.5 MiB 328 KiB 0 B 5.1 MiB 10 GiB 0.05 1.00 1 up
4 hdd 0.00980 1.00000 10 GiB 5.4 MiB 328 KiB 0 B 5.1 MiB 10 GiB 0.05 0.99 0 up
5 hdd 0.00980 1.00000 10 GiB 5.3 MiB 328 KiB 0 B 5 MiB 10 GiB 0.05 0.98 1 up
TOTAL 50 GiB 27 MiB 1.6 MiB 0 B 26 MiB 50 GiB 0.05
MIN/MAX VAR: 0.98/1.02 STDDEV: 0
5.21 模拟osd 上线
擦除磁盘
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node1 /dev/sdd
添加osd
magedu@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdd
创建rdb
magedu@ceph-deploy:~/ceph-cluster$ ceph osd pool create myrbd1 64 64 #创建存储池,指定 pg 和 pgp 的数量,pgp 是对存在 于 pg 的数据进行组合存储,pgp 通常等于 pg 的值
magedu@ceph-deploy:~/ceph-cluster$ ceph osd pool application enable myrbd1 rbd #对存储池启用 RBD 功能
magedu@ceph-deploy:~/ceph-cluster$ rbd pool init -p myrbd1 #通过 RBD 命令对存储池初始化
magedu@ceph-deploy:~/ceph-cluster$ rbd pool stats myrbd1
Total Images: 0
Total Snapshots: 0
Provisioned Size: 0 B
创建并验证img
magedu@ceph-deploy:~/ceph-cluster$ rbd create myimg1 --size 5G --pool myrbd1
magedu@ceph-deploy:~/ceph-cluster$ rbd create myimg2 --size 3G --pool myrbd1 --image-format 2 --image-feature layering
magedu@ceph-deploy:~/ceph-cluster$ rbd ls --pool myrbd1 #列出指定的 pool 中所有的 img myimg1 myimg2
myimg1
myimg2
magedu@ceph-deploy:~/ceph-cluster$ rbd pool stats myrbd1 #查看对应池的状态
Total Images: 2
Total Snapshots: 0
Provisioned Size: 8 GiB
magedu@ceph-deploy:~/ceph-cluster$ rbd --image myimg1 --pool myrbd1 info #查看指定 rdb 的信息
rbd image 'myimg1':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 152dda69d7fb
block_name_prefix: rbd_data.152dda69d7fb
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #由于我OS的kernel只支持layering,其他都不支持,所以需要把部分不支持的特性disable掉
op_features:
flags:
create_timestamp: Sun Aug 15 20:43:04 2021
access_timestamp: Sun Aug 15 20:43:04 2021
modify_timestamp: Sun Aug 15 20:43:04 2021
5.22 客户端使用块存储
[root@ceph-client ceph]# rbd -p myrbd1 map myimg2 #这个只有layering所以可以直接挂载成功
/dev/rbd0
[root@ceph-client ceph]# rbd -p myrdb1 map myimg1 #这个需要关闭除了layering的其他特性
* 方式1
magedu@ceph-deploy:~/ceph-cluster$ rbd --image myimg1 --pool myrbd1 feature disable exclusive-lock object-map fast-diff deep-flatten
magedu@ceph-deploy:~/ceph-cluster$ rbd --image myimg1 --pool myrbd1 info
* 方式2
修改Ceph配置文件/etc/ceph/ceph.conf,在global section下,增加
rbd_default_features = 1
#再创建rdb镜像。
rbd create ceph-client1-rbd1 --size 10240
[root@ceph-client ~]# lsblk
#mkfs.xfs /dev/rdb0
#mkdir /data
#mount /dev/rdb0 /data/
#cp /etc/passwd /data
#ll /data
[root@ceph-client data]# dd if=/dev/zero of=/data/ceph-test-file bs=1MB count=300
[root@ceph-client ~]# ll -h /data/ceph-test-file
验证数据
[root@ceph-node2 ~]# ceph df
5.23 取消映射块设备
root@ceph-mon1:~# umount /mnt/ceph-vol1#取消挂载
root@ceph-mon1:~# rbd unmap /dev/rbd/myrbd1/myimg2#取消映射
root@ceph-mon1:~# rbd showmapped #查看是否取消成功,如没有任何输出则表示取消映射成功
5.24 删除块设备,执行以下命令
magedu@ceph-deploy:~/ceph-cluster$ rbd ls --pool myrbd1
magedu@ceph-deploy:~/ceph-cluster$ rbd --pool myrbd1 rm myimg1
magedu@ceph-deploy:~/ceph-cluster$ rbd --pool myrbd1 rm myimg2 #需要所以节点都卸载才能删除
Removing image: 100% complete...done.
magedu@ceph-deploy:~/ceph-cluster$ rbd ls --pool myrbd1