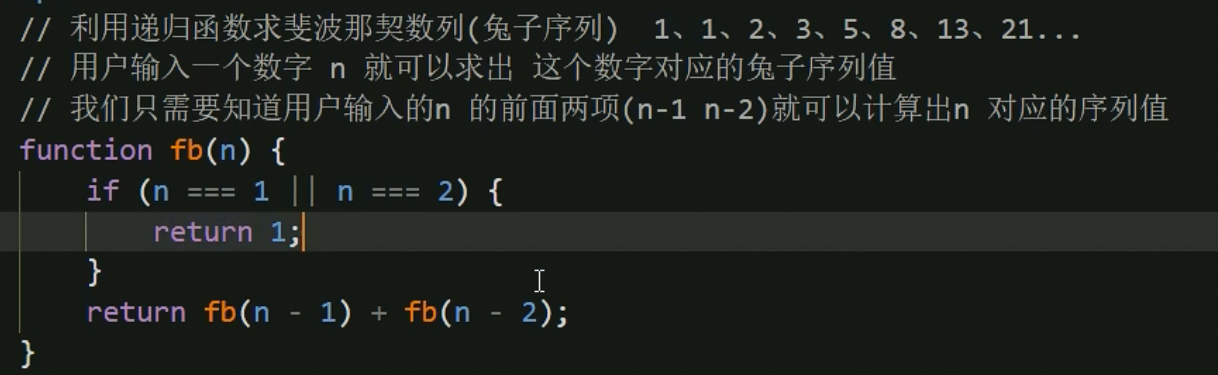
兔子序列当前项的值等于前两项的值加起来
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行“尾调用优化”。
由此可见,“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6也是如此,第一次明确规定,所有ECMAScript的实现,都必须部署“尾调用优化”。这就是说,在ES6中,只要使用尾递归,就不会发生栈溢出,相对节省内存。
ES6的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
func.arguments:返回调用时函数的参数。func.caller:返回调用当前函数的那个函数。
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
把上面的改成尾递归:

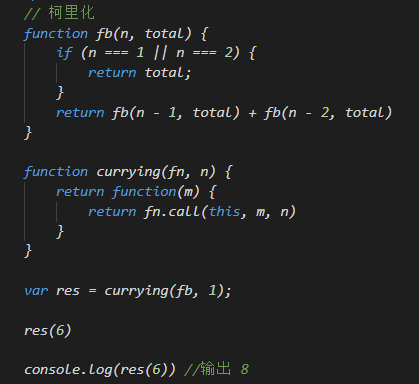
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
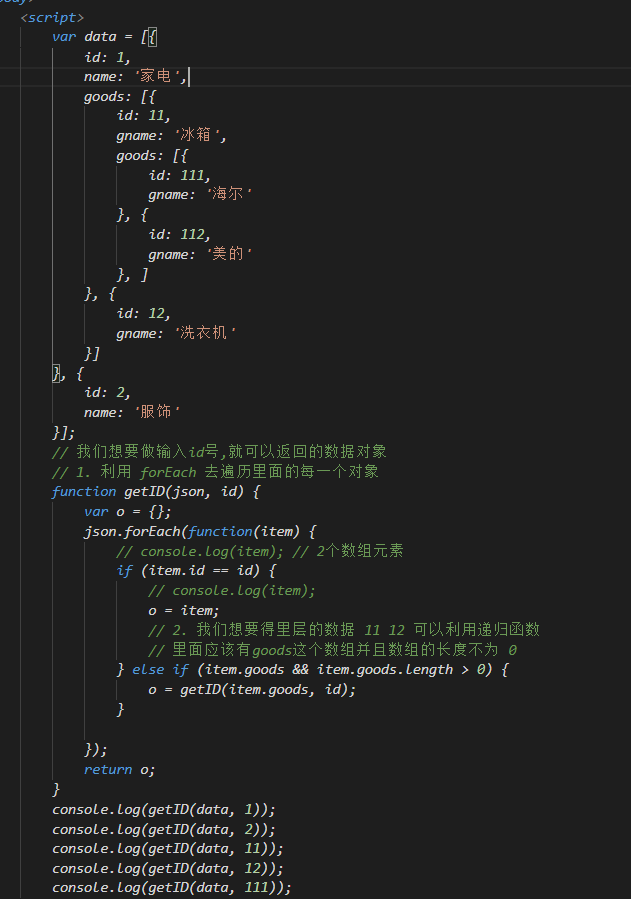
需求:传入id,返回对应的数据对象
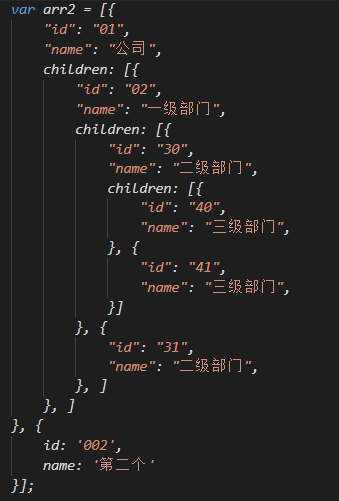
父子关系的数组转换成树形结构数据
数据结构:

封装方法:

树形结构转数组:
树形结构数据:
封装方法:
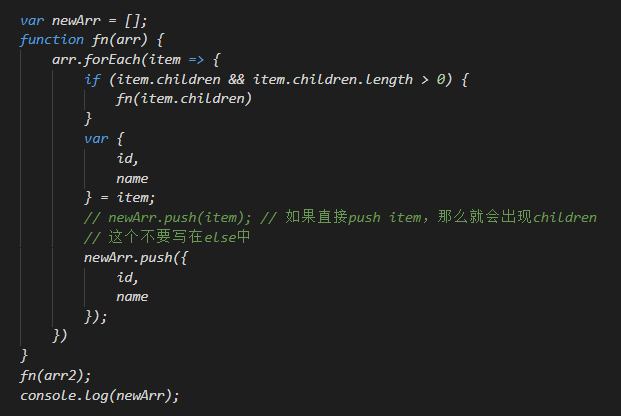
输出:
