目录
1. 新建scrapy项目
scrapy startproject mySpider
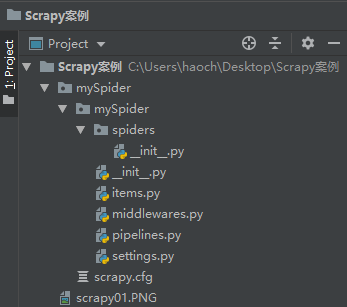
得到了如下的文件

其内部文件结构如下:
2. 爬虫文件:
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
2.1. 查看需要爬取内容存在哪里:
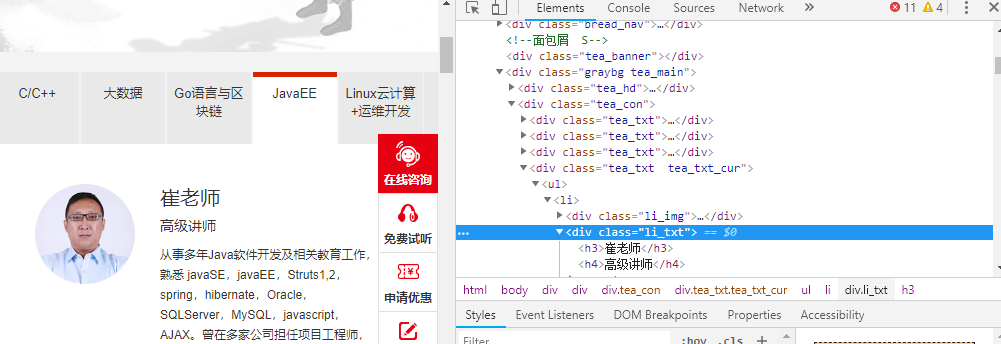
我们可以通过response.xpath提取相关内容
for each in reponse.xpath('//div[@class = "li_txt"]'):
name = each.xpath('./h3/text()')
title = each.xpath('./h4/text()')
info = each.xpath('./p/text()')
2.2. 设置item需要保存的数据变量
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
2.3. 创建爬虫文件
- 在mySpider下的spiders文件夹下创建一个新的爬虫文件命名为
itcastspider.py
import scrapy
from mySpider.items import MyspiderItem
# 创建一个爬虫
class ItcaseSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowed_domains = ['http://www.itcast.cn/']
# 爬虫开始的url
start_urls = ["http://www.itcast.cn/channel/teacher.shtml#ajavaee"]
# setting -> name -> allowed_domains ->start_urls -> request
# request -> scrapy engine -> scheduler -> downloader -> download from inetrnet(自动执行)
# Downloader -> spider ->调用parse方法
def parse(self, response):
# with open("teacher.html", 'wb') as f:
# f.write(response.body) # 读取响应文件内容
# 所有老师列表集合
teacherItem = []
for each in response.xpath('//div[@class = "li_txt"]'):
# 将我们得到的数据封装到一个 `MyspiderItem` 对象
item = MyspiderItem()
# 通过extract()转换为unicode字符串
# 不加extract()就是xpath匹配的对象而已
name = each.xpath('./h3/text()').extract() # xpath返回的都是列表,元素根据匹配规则来(e.g. text())
title = each.xpath('./h4/text()').extract()
info = each.xpath('./p/text()').extract()
item['name'] = name [0]
item['title'] = title[0]
item['info'] = info[0]
teacherItem.append(item)
# 直接返回数据,用于保存类型
return teacherItem
2.4. 保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
2.5. yield的用法
我们可以将上面的return方法换成yield为一个生成迭代器
- yield每一次都传递给一个数据给管道文件
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
- yield传递的管道文件需要重写
import json
class ItcastPipeline(object):
# __init__可选的,初始化文件
def __init__(self):
self.filename = open("yieldmethod.json", "wb")
# 处理Item数据的,必须写的
def process_item(self, item, spider):
jsontext = json.dumps(dict(item), ensure_ascii=False) + "
"
self.filename.write(jsontext.encode("utf-8"))
return item
# 可选的,执行结束时的方法
def close_spider(self,spider):
self.filename.close()
3. 在PyCharm中运行scrapy
3.1. 方法一: 直接走PyCharm中的terminal中执行
3.2. 方法二: 新建start.py并添加到configration中
from scrapy import cmdline
cmdline.execute("scrapy crawl itcast".split())
4. 结果
