今天基于外包杯项目需要,学习了MATLAB相关的技术,对于图片数字识别的技术,具体不多说了。
今天主要进行spar运行k环境搭建,scala语言的相关使用后续继续学习
首先需要下载spark的包,这里我是根据尚硅谷的视频进行环境配置,所以直接使用尚硅谷给的资料中spark3的包,版本:spark-3.0.0-bin-hadoop3.2
需要注意的hadoop和spark有版本对应,所以下载spark的包时需要注意hadoop的版本,根据hadoop的版本进行选择。我的hadoop版本是3.1.3,使用spark3.0是没问题的。
具体下包去spark官网下载,官方地址为:https://spark.apache.org/downloads.html
之后打开虚拟机,上传之前下载的spark的包,进行环境搭建。
解压缩包:
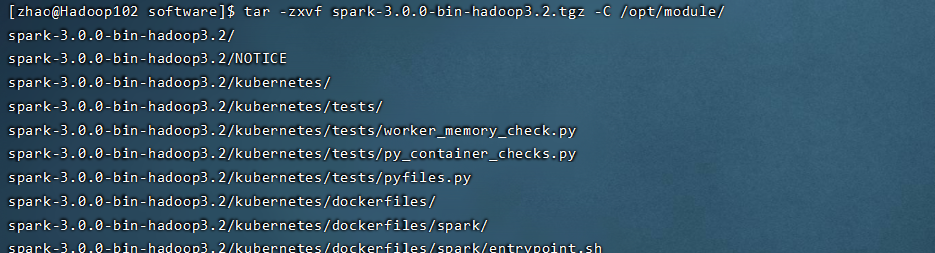
解压成功没问题的话,是可以进入spark的目录下,使用bin/spark-shell进入命令界面的,这里的spark-local是对包进行了改名,使用mv改名即可。
执行一个简单wordcount用例,里面的word.txt需要自己到data下创建一个

运行成功,证明你当前本地环境是没有问题的
搭建

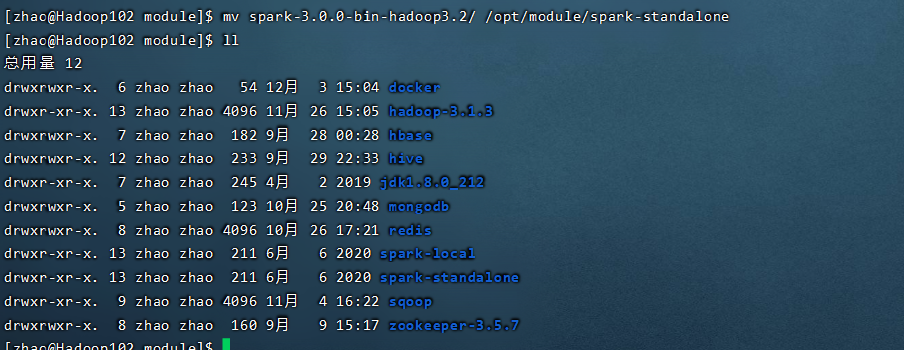
首先解压缩文件,和本地模式区分开,在同样的目录下再次解压spark的包,命名为spark-standalone

之后进入conf目录下修改,
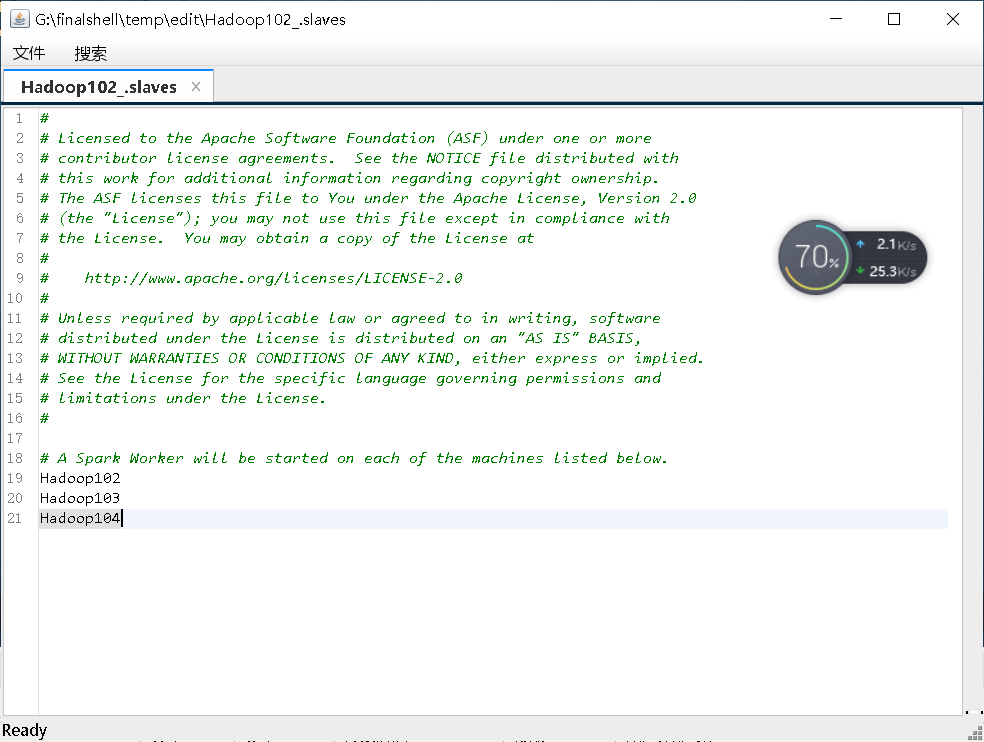
之后分发到其他虚拟机,这里的xsync命令可以去尚硅谷的大海老师讲的hadoop视频去了解,这是自己写的一个脚本

测试集群是否成功:

运行成功即配置成功

之后就不多说了。今天配置了spark的两个模式,之后还有yarn模式和其他的模式,就不细说了,可以到尚硅谷根据视频学习,今天仅仅是记录配置记录,之后的yarn等模式,就不讲了。明天开始学习scala语言的使用,并开始学spark-core。