Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
Kubernetes设计架构:
Kubernetes主要由以下几个核心组件组成:
- etcd保存了整个集群的状态;
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
kubernetes集群分为一个Master节点和若干Node节点, Master是Kubernetes 的主节点。
Master组件可以在集群中任何节点上运行。但是为了简单起见,通常在一台虚拟机上启动所有Master组件,并且不会在此VM机器上运行用户容器。
集群所有的控制命令都传递给Master组件,在Master节点上运行。kubectl命令在其他Node节点上无法执行,原因是kubectl命令需要使用kubernetes-admin来运行。如需执行请: 将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,然后配置环境变量。
master四个组件的主要功能可以概括为:
1. api server:负责对外提供restful的Kubernetes API服务,其他Master组件都通过调用api server提供的rest接口实现各自的功能,如controller就是通过api server来实时监控各个资源的状态的。
2. etcd:是 Kubernetes 提供的一个高可用的键值数据库,用于保存集群所有的网络配置和资源对象的状态信息,也就是保存了整个集群的状态。数据变更都是通过api server进行的。整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置,分别是:
1)网络插件flannel,其它网络插件也需要用到etcd存储网络的配置信息;
2)kubernetes本身,包括各种资源对象的状态和元信息配置。
3. scheduler:监听新建pod副本信息,并通过调度算法为该pod选择一个最合适的Node节点。会检索到所有符合该pod要求的Node节点,执行pod调度逻辑。调度成功之后,会将pod信息绑定到目标节点上,同时将信息写入到etcd中。一旦绑定,就由Node上的kubelet接手pod的接下来的生命周期管理。如果把scheduler看成一个黑匣子,那么它的输入是pod和由多个Node组成的列表,输出是pod和一个Node的绑定,即将这个pod部署到这个Node上。Kubernetes目前提供了调度算法,但是同样也保留了接口,用户可以根据自己的需求定义自己的调度算法。
4. controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等。每个资源一般都对应有一个控制器,这些controller通过api server实时监控各个资源的状态,controller manager就是负责管理这些控制器的。当有资源因为故障导致状态变化,controller就会尝试将系统由“现有状态”恢复到“期待状态”,保证其下每一个controller所对应的资源始终处于期望状态。比如我们通过api server创建一个pod,当这个pod创建成功后,api server的任务就算完成了。而后面保证pod的状态始终和我们预期的一样的重任就由controller manager去保证了。
controller manager 包括运行管理控制器(kube-controller-manager)和云管理控制器(cloud-controller-manager)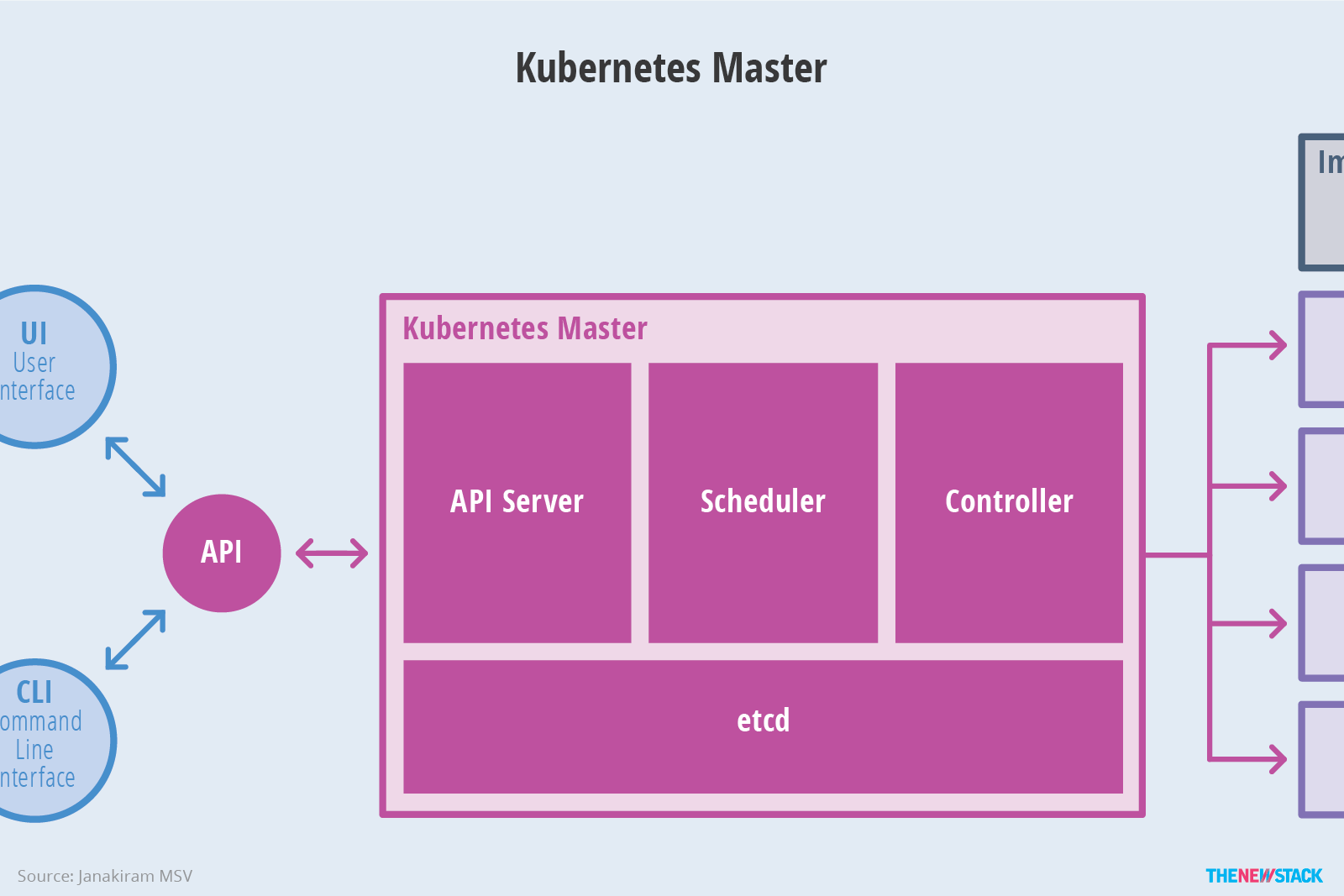
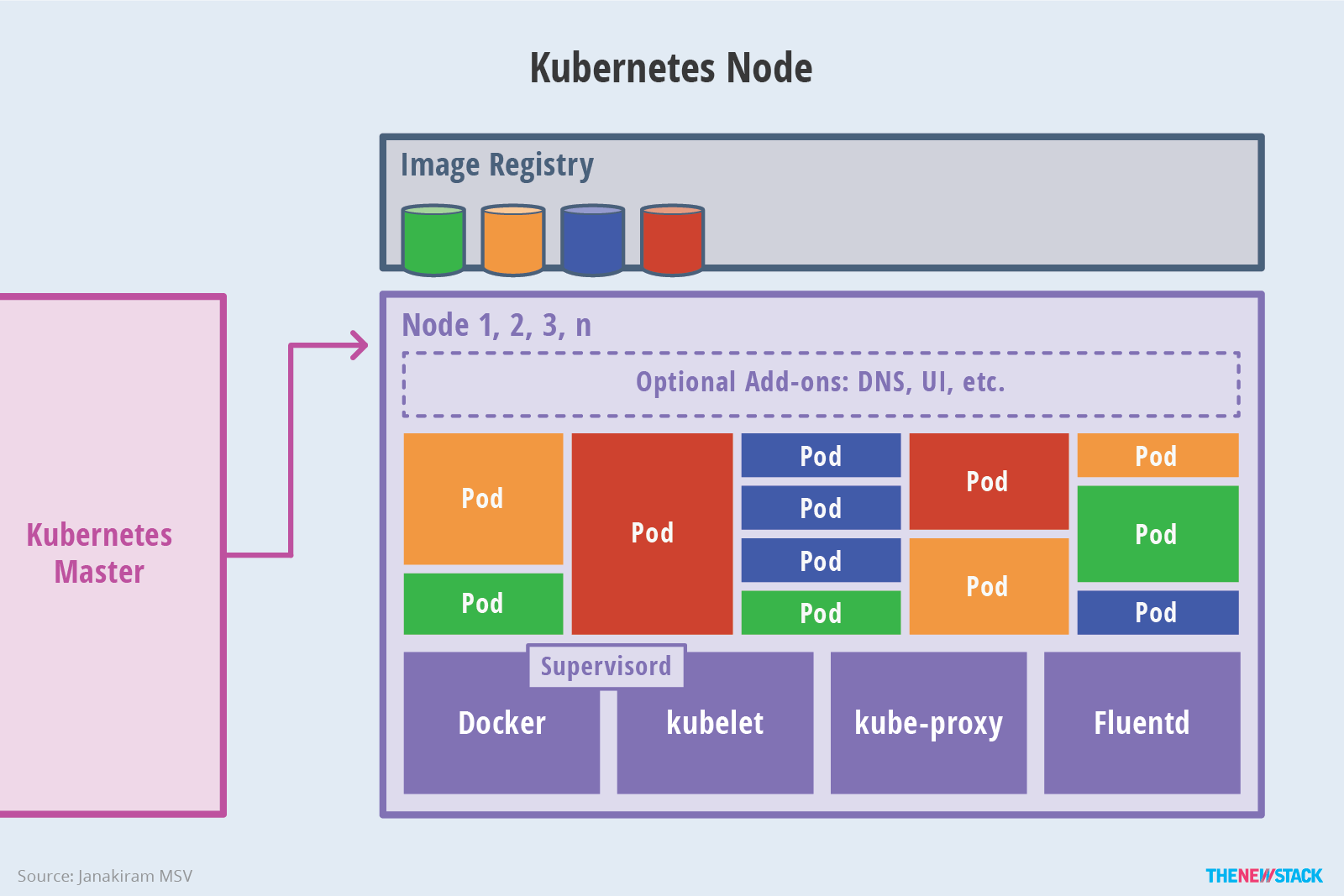
Node主要组件: 包括kubelet、kube-proxy、container runtime
Node上运行着Master分配的pod,当一个Node宕机,其上的pod会被自动转移到其他Node上。每一个Node节点都安装了Node组件,包括kubelet、kube-proxy、container runtime。
1. kubelet 会监视已分配给节点的pod,负责pod的生命周期管理,同时与Master密切协作,维护和管理该Node上面的所有容器,实现集群管理的基本功能。即Node节点通过kubelet与master组件交互,可以理解为kubelet是Master在每个Node节点上面的agent。本质上,它负责使Pod的运行状态与期望的状态一致。
2. kube-proxy 是实现service的通信与负载均衡机制的重要组件,将到service的请求转发到后端的pod上。
3. Container runtime:容器运行环境,目前Kubernetes支持docker和rkt两种容器。
pod创建流程
1 kubelet client 端执行kubelet create pod命令提交post kubelet apiserver请求
2 apiserver 监听接受到请求
2.1 对请求进行、解析、认证、授权、超时处理、审计通过
2.2 pod请求事件进入MUX和route流程,apiserver会根据请求匹配对应pod类型的定义,apiserver会进行一个convert工作,将请求内容转换成super version对象
2.3 apiserver会先进行admission() 准入控制,比如添加标签,添加sidecar容器等和校验个字段合法性
2.4 apiserver将验证通过的api对象转换成用户最初提交的版本,进行序列化操作,并调用etcd api保存apiserver处理pod事件信息,apiserver把pod对象add到调度队列中
3.1schedule调度器会通过监听apiserver add到pod对象队列,
3.2调度器开始尝试调度,筛选出适合调度的节点,并打分选出一个最高分的节点
3.3 调度器会将pod对象与node绑定,调度器将信息同步apiserver保存到etcd中完成调度
4.1 节点kubelet通过watch监听机制,监听与自己相关的pod对象,kubelet会把相关pod信息podcache缓存到节点内存
4.2 kubelet通过检查该pod对象在kubelet内存状态,kubelet就能够判断出是一个新调度pod对象
4.3 kubelet会启动 pod update worker、单独goroutine处理pod对象生成对应的pod status,检查pod所生命的volume、网络是否准备好
4.4 kubelet调用docker api 容器运行时CRI,发起插件pod所定义容器Container Runtime Interface, CRI请求
4.5 docker 容器运行时比如docker响应请求,然后开始创建对应容器
官方文档: https://www.kubernetes.org.cn/k8s
资料文档:https://blog.csdn.net/weixin_38645718/article/details/85931795, https://blog.csdn.net/sq4521/article/details/105912608, https://blog.51cto.com/zjunzz/2549946