Redis是一个基于内存的非关系型的数据库,数据保存在内存中,但是内存中的数据也容易发生丢失。这里Redis就为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。
Redis在以前的版本中是单线程的,而在6.0后对Redis的io模型做了优化,io Thread为多线程的,但是worker Thread仍然是单线程。
在Redis启动的时候就会去加载持久化的文件,如果没有就直接启动,在启动后的某一时刻会继续持久化内存中产生的数据。
接下来我们就来详细了解Redis的两种持久化机制RDB(Redis DataBase)和AOF(Append Only File)。
RDB持久化机制
什么是RDB持久化呢?RDB持久化就是将当前进程的数据以生成快照的形式持久化到磁盘中。对于快照的理解,我们可以理解为将当前线程的数据以拍照的形式保存下来。
RDB持久化的时候会单独fork一个与当前进程一摸一样的子进程来进行持久化,因此RDB持久化有如下特点:
-
开机恢复数据快。
-
写入持久化文件快。
RDB的持久化也是Redis默认的持久化机制,它会把内存中的数据以快照的形式写入默认文件名为dump.rdb中保存。
在安装后的Redis中,Redis的配置都在redis.conf文件中,如下图所示,dbfilename就是配置RDB的持久化文件名。
持久化触发时机
在RDB机制中触发内存中的数据进行持久化,有以下三种方式:
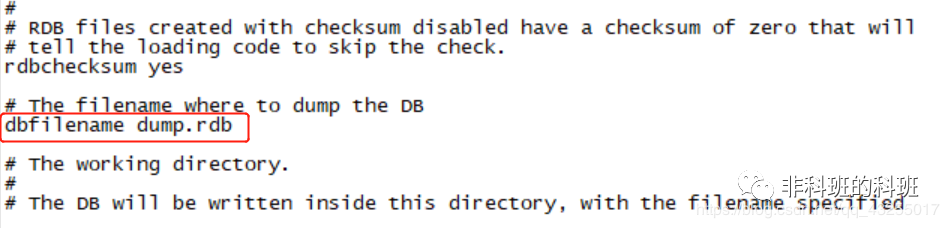
(1)save命令:
save命令不会fork子进程,通过阻塞当前Redis服务器,直到RDB完成为止,所以该命令在生产中一般不会使用。save命令执行原理图如下:
在redis.conf的配置中dir的配置就是RDB持久化后生成rdb二进制文件所在的位置,默认的位置是./,表示当前位置,哪里启动redis,就会在哪里生成持久化文件,如下图所示:

然后我们直接在该位置启动我们的Redis服务,启动的命令如下:
/root/redis-4.0.6/src/redis-server /root/redis-4.0.6/redis.conf
接着通过该命令:ps -aux | grep redis,查看我们的redis服务是否正常启动,若是显示如下图所示,则表示Redis是正常启动的:

正常启动后,直接登陆Redis,可以通过以下命令登陆Redis,如下图所示:

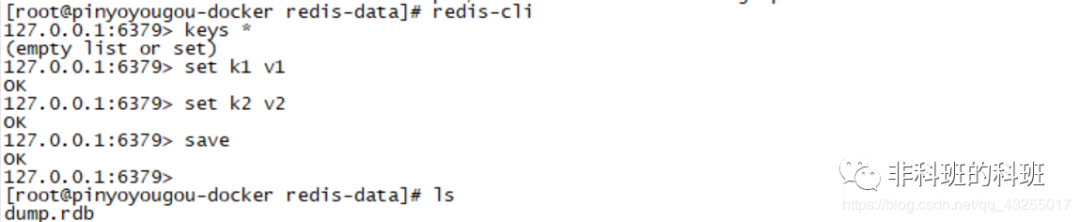
因为当前中Redis是新安装的,数据都是为空,什么都没有,然后通过下图的命令随意向Redis中输入几条命令,最后执行save命令,在该文件夹下就会出现dump.rdb持久化的数据文件。
当然上面说到,在新安装的Redis中默认的RDB数据持久化位置为./文件,一般我们会把它改成服务器自己的特定位置下,原理都是一样的,可以自己进行尝试,这里不再进行演示。
(2)bgsave命令:
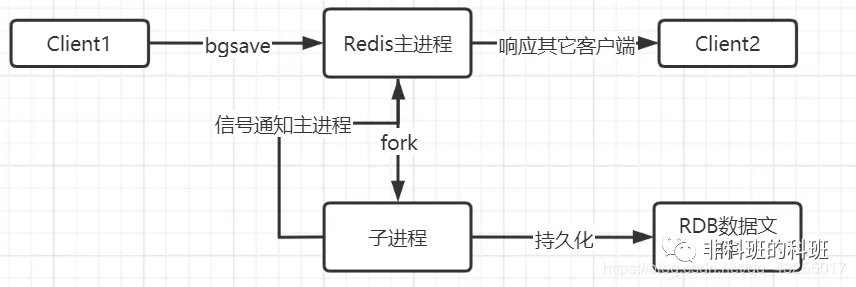
bgsave命令会在后台fork一个与Redis主线程一模一样的子线程,由子线程负责内存中的数据持久化。
这样fork与主线程一样的子线程消耗了内存,但是不会阻塞主线程处理客户端请求,是以空间换时间的方式快照内存中的数据到到文件中。
bgsave命令阻塞只会发生在fork子线程的时候,这段时间发生的非常短,可以忽略不计,如下图是 bgsave执行的流程图:
上面说到redis.conf中的dir配置是配置持久化文件生成的指定的目录,dbfilename是配置生成的文件名,也可以通过命令行使用命令来动态的设置这两个配置,命令如下:
config set dir{newDir}
config set dbfilename{newFileName}
3)自动化
除了上面在命令行使用save和bgsave命令触发持久化,也可以在redis.conf配置文件中,完成配置,如下图所示:

在新安装的redis中由默认的以上三个save配置,save 900 1表示900秒内如果至少有1个key值变化,则进行持久化保存数据;
save 300 10则表示300秒内如果至少有10个key值发生变化,则进行持久化,save 60 10000以此类推。
通过以上的分析可以得出以下save和bgsave的对比区别:
-
save是同步持久化数据,而bgsave是异步持久化数据。
-
save不会fork子进程,通过主进程持久化数据,会阻塞处理客户端的请求,而bdsave会fork子进程持久化数据,同时还可以处理客户端请求,高效。 -
save不会消耗内存,而bgsave会消耗内存。
RDB的优缺点
缺点: RDB持久化后的文件是紧凑的二进制文件,适合于备份、全量复制、大规模数据恢复的场景,对数据完整性和一致性要求不高,RDB会丢失最后一次快照的数据。
优点: 开机的恢复数据快,写入持久化文件快。
AOF持久化机制
AOF持久化机制是以日志的形式记录Redis中的每一次的增删改操作,不会记录查询操作,以文本的形式记录,打开记录的日志文件就可以查看操作记录。
AOF是默认不开启的,若是想开启AOF,在如下图的配置修改即可:

只需要把appendonly no修改为appendonly yes即可开启,在AOF中通过appendfilename配置生成的文件名,该文件名默认为appendonly.aof,路径也是通过dir配置的,这个与RDB的一样,具体的配置信息如下图所示:

AOF触发机制
AOF带来的持久化更加安全可靠,默认提供三种触发机制,如下所示:
-
no:表示等操作系统等数据缓存同步到磁盘中(快、持久化没保证)。 -
always:同步持久化,每次发生数据变更时,就会立即记录到磁盘中(慢,安全)。 -
everysec:表示每秒同步一次(默认值,很快,但是会丢失一秒内的数据)。
AOF中每秒同步也是异步完成的,效率是非常高的,由于该机制对日志文件的写入操作是采用append的形式。
因此在写入的过程即使宕机,也不会丢失已经存入日志文件的数据,数据的完整性是非常高的。
在新安装的Redis的配置文件中,AOF的配置如下所示:

AOF重写机制
但是,在写入所有的操作到日志文件中时,就会出现日志文件很多重复的操作,甚至是无效的操作,导致日志文件越来越大。
所谓的无效的的操作,举个例子,比如某一时刻对一个k++,然后后面的某一时刻k--,这样k的值是保持不变的,那么这两次的操作就是无效的。
如果像这样的无效操作很多,记录的文件臃肿,就浪费了资源空间,所以在Redis中出现了rewrite机制。
redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。
重写AOF的日志文件不是读取旧的日志文件瘦身,而是将内存中的数据用命令的方式重写一个AOF文件,重新保存替换原来旧的日志文件,因此内存中的数据才是最新的。
重写操作也会fork一个子进程来处理重写操作,重写以内存中的数据作为重写的源,避免了操作的冗余性,保证了数据的最新。
在Redis以append的形式将修改的数据写入老的磁盘中 ,同时Redis也会创建一个新的文件用于记录此期间有哪些命令被执行。
下面进行演示一下AOF的操作,首先先打开AOF机制,修改配置文件中的appendonly no为appendonly yes,然后执行如下图的操作:
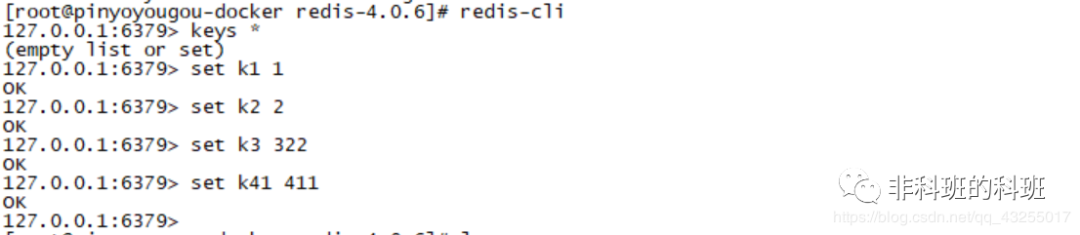
都显示执行成功,ls以下查看此时当前的文件夹终究会出现appendonly.aof
,AOF的数据持久化文件,通过cat命令查看内容:
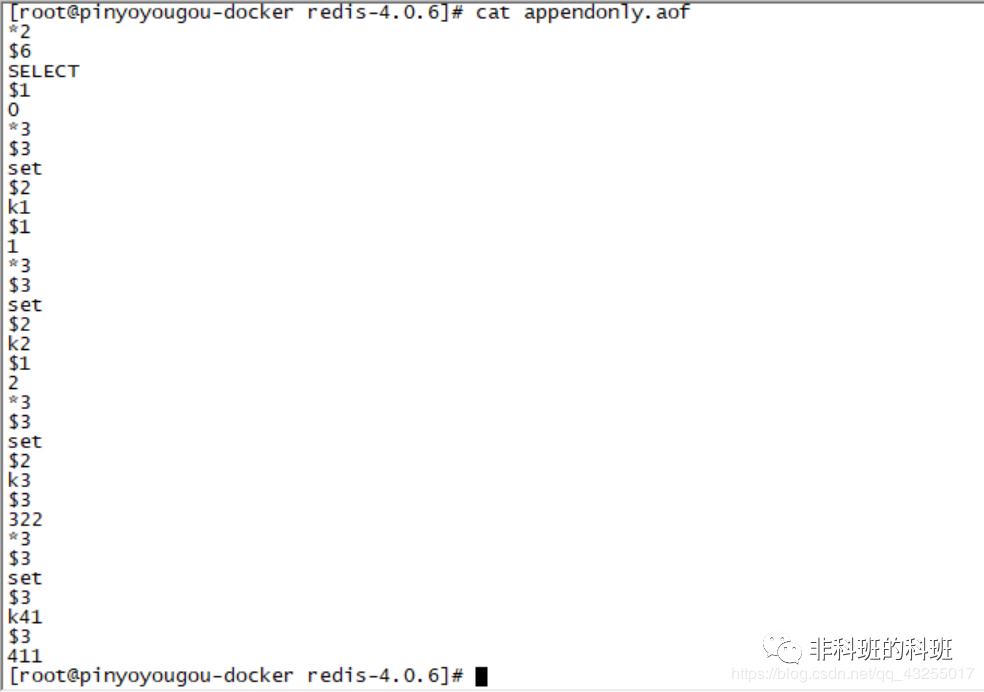
从上面的存储的文件中可以看出,每一个命令是非常有规律的,比如第一次执行key *映射到该配置文件中的命令如下:
*2 //表示该命令两组key 为一组 * 为一组 $6 //表示SELECT有6字符 SELECT $1 //表示下面的0一个字符 0
然后执行set k1 1的命令,此命令映射到文件中的命令如下:
*3 //表示该命令有三组set为一组 k1为一组 1为一组 $3 // 表示set有三个字符 set // 表示执行了set命令 $2 // 表示k1有两个字符 k1 // key值 $1 // 便是value值的字符长度为1 1 // value值
当AOF的日志文件增长到一定大小的时候Redis就能够bgrewriteaof对日志文件进行重写瘦身。当AOF配置文件大于改配置项时自动开启重写(这里指超过原大小的100%)。
该配置可以通过如下的配置项进行配置:

AOF的优缺点
优点: AOF更好保证数据不会被丢失,最多只丢失一秒内的数据,通过fork一个子进程处理持久化操作,保证了主进程不会进程io操作,能高效的处理客户端的请求。
另外重写操作保证了数据的有效性,即使日志文件过大也会进行重写。
AOF的日志文件的记录可读性非常的高,即使某一时刻有人执行flushall清空了所有数据,只需要拿到aof的日志文件,然后把最后一条的flushall给删除掉,就可以恢复数据。
缺点: 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。AOF在运行效率上往往会慢于RDB。
混合持久化
在redis4.0后混合持久化(RDB+AOF)对重写的优化,4.0版本的混合持久化默认是关闭的,可以通过以下的配置开启混合持久化:

混合持久化也是通过bgrewriteaof来完成的,不同的是当开启混合持久化时,fork出的子进程先将共享内存的数据以RDB方式写入aof文件中,然后再将重写缓冲区的增量命令以AOF方式写入文件中。
写入完成后通知主进程统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的AOF文件。简单的说:新的AOF文件前半段是以RDB格式的全量数据后半段是AOF格式的增量数据。
优点: 混合持久化结合RDB持久化和AOF持久化的优点,由于绝大部分的格式是RDB格式,加载速度快,增量数据以AOF方式保存,数据更少的丢失。
RDB和AOF优势和劣势
rdb适合大规模的数据恢复,由于rdb是以快照的形式持久化数据,恢复的数据快,在一定的时间备份一次,而aof的保证数据更加完整,损失的数据只在秒内。
具体哪种更适合生产,在官方的建议中两种持久化机制同时开启,如果两种机制同时开启,优先使用aof持久化机制。
来自:https://mp.weixin.qq.com/s?__biz=MzU1MzE4OTU0OQ==&mid=2247484021&idx=1&sn=4c228c705cfd524db3cf27425fde1ba0&chksm=fbf7ebb7cc8062a138b9baad194548983095806f8f15a82e1a95f18f19999c76d750aa91b93b&scene=21#wechat_redirect