日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题。
一旦涉及大数据量的需求,如一些商品抢购的情景,或者主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度问题有严重的性能弊端,详细的磁盘读写原理请参考这一片[]。
在这一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
为了克服上述的问题,项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
Redis技术就是NoSQL技术中的一种。Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。
但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透、缓存击穿和缓存雪崩。本篇文章从实际代码操作,来提出解决这三个缓存问题的方案,毕竟Redis的缓存问题是实际面试中高频问点,理论和实操要兼得。
缓存穿透
缓存穿透是指查询一条数据库和缓存都没有的一条数据,就会一直查询数据库,对数据库的访问压力就会增大,缓存穿透的解决方案,有以下两种:
-
缓存空对象:代码维护较简单,但是效果不好。
-
布隆过滤器:代码维护复杂,效果很好。
缓存空对象
缓存空对象是指当一个请求过来缓存中和数据库中都不存在该请求的数据,第一次请求就会跳过缓存进行数据库的访问,并且访问数据库后返回为空,此时也将该空对象进行缓存。
若是再次进行访问该空对象的时候,就会直接击中缓存,而不是再次数据库,缓存空对象实现的原理图如下:

缓存空对象的实现代码如下:
public class UserServiceImpl { @Autowired UserDAO userDAO; @Autowired RedisCache redisCache; public User findUser(Integer id) { Object object = redisCache.get(Integer.toString(id)); // 缓存中存在,直接返回 if(object != null) { // 检验该对象是否为缓存空对象,是则直接返回null if(object instanceof NullValueResultDO) { return null; } return (User)object; } else { // 缓存中不存在,查询数据库 User user = userDAO.getUser(id); // 存入缓存 if(user != null) { redisCache.put(Integer.toString(id),user); } else { // 将空对象存进缓存 redisCache.put(Integer.toString(id), new NullValueResultDO()); } return user; } } }
缓存空对象的实现代码很简单,但是缓存空对象会带来比较大的问题,就是缓存中会存在很多空对象,占用内存的空间,浪费资源,一个解决的
办法就是设置空对象的较短的过期时间,代码如下:
// 在缓存的时候,添加多一个该空对象的过期时间60秒 redisCache.put(Integer.toString(id), new NullValueResultDO(),60);
缓存击穿
缓存击穿是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,瞬间对数据库的访问压力增大。
缓存击穿这里强调的是并发,造成缓存击穿的原因有以下两个:
-
该数据没有人查询过 ,第一次就大并发的访问。(冷门数据)
-
添加到了缓存,reids有设置数据失效的时间 ,这条数据刚好失效,大并发访问(热点数据)
对于缓存击穿的解决方案就是加锁,具体实现的原理图如下:

当用户出现大并发访问的时候,在查询缓存的时候和查询数据库的过程加锁,只能第一个进来的请求进行执行,当第一个请求把该数据放进缓存中,接下来的访问就会直接集中缓存,防止了缓存击穿。
业界比价普遍的一种做法,即根据key获取value值为空时,锁上,从数据库中load数据后再释放锁。若其它线程获取锁失败,则等待一段时间后重试。这里要注意,分布式环境中要使用分布式锁,单机的话用普通的锁(synchronized、Lock)就够了。
下面以一个获取商品库存的案例进行代码的演示,单机版的锁实现具体实现的代码如下:
// 获取库存数量 public String getProduceNum(String key) { try { synchronized (this) { //加锁 // 缓存中取数据,并存入缓存中 int num= Integer.parseInt(redisTemplate.opsForValue().get(key)); if (num> 0) { //没查一次库存-1 redisTemplate.opsForValue().set(key, (num- 1) + ""); System.out.println("剩余的库存为num:" + (num- 1)); } else { System.out.println("库存为0"); } } } catch (NumberFormatException e) { e.printStackTrace(); } finally { } return "OK"; }
分布式的锁实现具体实现的代码如下:
public String getProduceNum(String key) { // 获取分布式锁 RLock lock = redissonClient.getLock(key); try { // 获取库存数 int num= Integer.parseInt(redisTemplate.opsForValue().get(key)); // 上锁 lock.lock(); if (num> 0) { //减少库存,并存入缓存中 redisTemplate.opsForValue().set(key, (num - 1) + ""); System.out.println("剩余库存为num:" + (num- 1)); } else { System.out.println("库存已经为0"); } } catch (NumberFormatException e) { e.printStackTrace(); } finally { //解锁 lock.unlock(); } return "OK"; }
缓存雪崩
缓存雪崩 是指在某一个时间段,缓存集中过期失效。此刻无数的请求直接绕开缓存,直接请求数据库。
造成缓存雪崩的原因,有以下两种:
-
reids宕机
-
大部分数据失效
比如天猫双11,马上就要到双11零点,很快就会迎来一波抢购,这波商品在23点集中的放入了缓存,假设缓存一个小时,那么到了凌晨24点的时候,这批商品的缓存就都过期了。
而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰,对数据库造成压力,甚至压垮数据库。
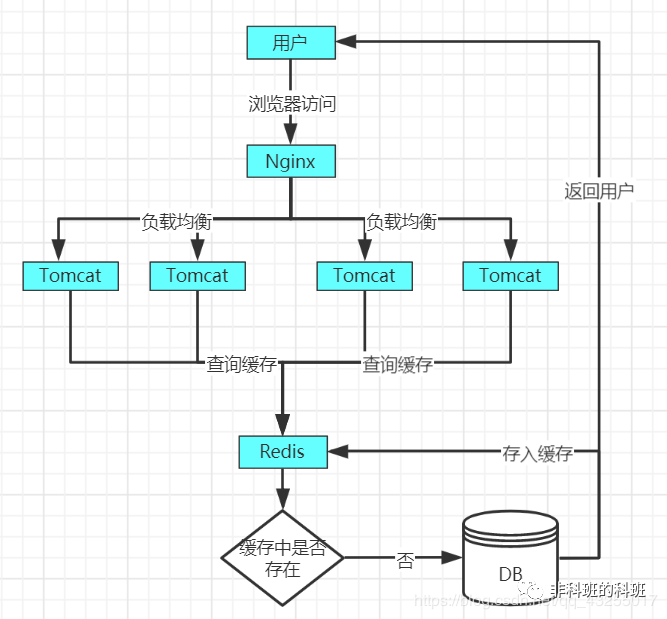
缓存雪崩的原理图如下,当正常的情况下,key没有大量失效的用户访问原理图如下:
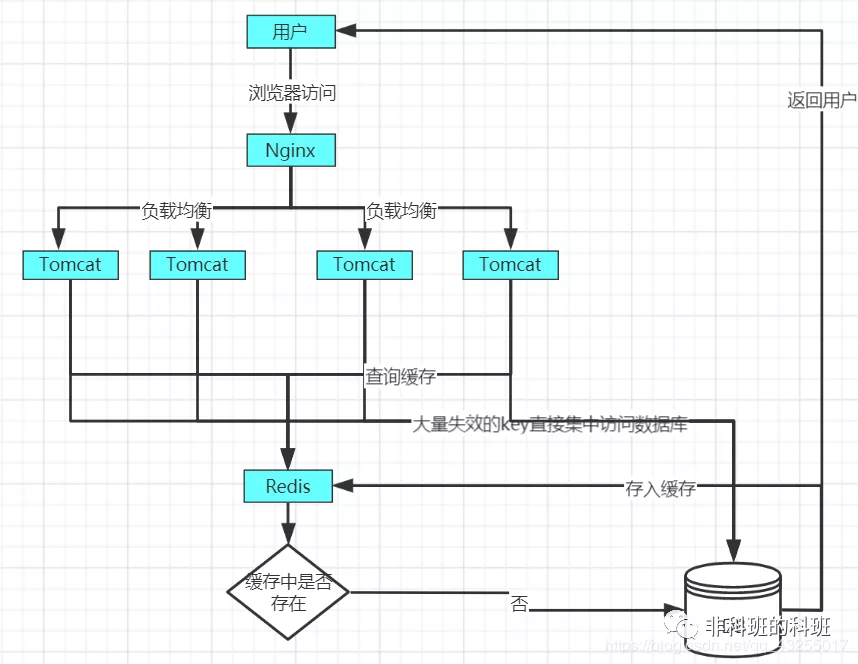
当某一时间点,key大量失效,造成的缓存雪崩的原理图如下:
对于缓存雪崩的解决方案有以下两种:
1.搭建高可用的集群,防止单机的redis宕机。
2.设置不同的过期时间,防止同一时间内大量的key失效。
针对业务系统,永远都是具体情况具体分析,没有最好,只有最合适。于缓存其它问题,缓存满了和数据丢失等问题,我们后面继续深入的学习。
最后也提一下三个词LRU、RDB、AOF,通常我们采用LRU策略处理溢出,Redis的RDB和AOF持久化策略来保证一定情况下的数据安全。
那么今天就带来了一个面试常问的一个问题:「假如你的Redis内存满了怎么办?」 长期的把Redis作为缓存使用,总有一天会存满的时候对吧。
这个面试题不慌呀,在Redis中有配置参数maxmemory可以「设置Redis内存的大小」。
在Redis的配置文件redis.conf文件中,配置maxmemory的大小参数如下所示:

实际生产中肯定不是100mb的大小哈,不要给误导了,这里我只是让大家认识这个参数,一般小的公司都是设置为3G左右的大小。
除了在配置文件中配置生效外,还可以通过命令行参数的形式,进行配置,具体的配置命令行如下所示:
//获取maxmemory配置参数的大小 127.0.0.1:6379> config get maxmemory //设置maxmemory参数为100mb 127.0.0.1:6379> config set maxmemory 100mb
倘若实际的存储中超出了Redis的配置参数的大小时,Redis中有「淘汰策略」,把「需要淘汰的key给淘汰掉,整理出干净的一块内存给新的key值使用」。
接下来我们就详细的聊一聊Redis中的淘汰策略,并且深入的理解每个淘汰策略的原理和应用的场景。
淘汰策略
Redis提供了「6种的淘汰策略」,其中默认的是noeviction,这6种淘汰策略如下:
noeviction(「默认策略」):若是内存的大小达到阀值的时候,所有申请内存的指令都会报错。allkeys-lru:所有key都是使用「LRU算法」进行淘汰。volatile-lru:所有「设置了过期时间的key使用LRU算法」进行淘汰。allkeys-random:所有的key使用「随机淘汰」的方式进行淘汰。volatile-random:所有「设置了过期时间的key使用随机淘汰」的方式进行淘汰。volatile-ttl:所有设置了过期时间的key「根据过期时间进行淘汰,越早过期就越快被淘汰」。
假如在Redis中的数据有「一部分是热点数据,而剩下的数据是冷门数据」,或者「我们不太清楚我们应用的缓存访问分布状况」,这时可以使用allkeys-lru。
假如所有的数据访问的频率大概一样,就可以使用allkeys-random的淘汰策略。
假如要配置具体的淘汰策略,可以在redis.conf配置文件中配置,具体配置如下所示:

这只需要把注释给打开就可以,并且配置指定的策略方式,另一种的配置方式就是命令的方式进行配置,具体的执行命令如下所示:
// 获取maxmemory-policy配置 127.0.0.1:6379> config get maxmemory-policy // 设置maxmemory-policy配置为allkeys-lru 127.0.0.1:6379> config set maxmemory-policy allkeys-lru
在介绍6种的淘汰策略方式的时候,说到了LRU算法,「那么什么是LRU算法呢?」
LRU算法
LRU(Least Recently Used)即表示最近最少使用,也就是在最近的时间内最少被访问的key,算法根据数据的历史访问记录来进行淘汰数据。
它的核心的思想就是:「假如一个key值在最近很少被使用到,那么在将来也很少会被访问」。
实际上Redis实现的LRU并不是真正的LRU算法,也就是名义上我们使用LRU算法淘汰键,但是实际上被淘汰的键并不一定是真正的最久没用的。
Redis使用的是近似的LRU算法,「通过随机采集法淘汰key,每次都会随机选出5个key,然后淘汰里面最近最少使用的key」。
这里的5个key只是默认的个数,具体的个数也可以在配置文件中进行配置,在配置文件中的配置如下图所示:

当近似LRU算法取值越大的时候就会越接近真实的LRU算法,可以这样理解,因为「取值越大那么获取的数据就越全,淘汰中的数据的就越接近最近最少使用的数据」。
那么为了实现根据时间实现LRU算法,Redis必须为每个key中额外的增加一个内存空间用于存储每个key的时间,大小是3字节。
在Redis 3.0中对近似的LRU算法做了一些优化,Redis中会维护大小是16的一个候选池的内存。
当第一次随机选取的采样数据,数据都会被放进候选池中,并且候选池中的数据会根据时间进行排序。
当第二次以后选取的数据,只有「小于候选池内的最小时间」的才会被放进候选池中。
当某一时刻候选池的数据满了,那么时间最大的key就会被挤出候选池。当执行淘汰时,直接从候选池中选取最近访问时间最小的key进行淘汰。
这样做的目的就是选取出最近似符合最近最少被访问的key值,能够正确的淘汰key值,因为随机选取的样本中的最小时间可能不是真正意义上的最小时间。
但是LRU算法有一个弊端:就是假如一个key值在以前都没有被访问到,然而最近一次被访问到了,那么就会认为它是热点数据,不会被淘汰。
然而有些数据以前经常被访问到,只是最近的时间内没有被访问到,这样就导致这些数据很可能被淘汰掉,这样一来就会出现误判而淘汰热点数据。
于是在Redis 4.0的时候除了LRU算法,新加了一种LFU算法,「那么什么是LFU算法算法呢?」
LFU算法
LFU(Least Frequently Used)即表示最近频繁被使用,也就是最近的时间段内,频繁被访问的key,它以最近的时间段的被访问次数的频率作为一种判断标准。
它的核心思想就是:根据key最近被访问的频率进行淘汰,比较少被访问的key优先淘汰,反之则优先保留。
LFU算法反映了一个key的热度情况,不会因为LRU算法的偶尔一次被访问被认为是热点数据。
在LFU算法中支持volatile-lfu策略和allkeys-lfu策略。
以上介绍了Redis的6种淘汰策略,这6种淘汰策略旨在告诉我们怎么做,但是什么时候做?这个还没说,下面我们就来详细的了解Redis什么时候执行淘汰策略。
删除过期键策略
在Redis中有三种删除的操作此策略,分别是:
- 「定时删除」:创建一个定时器,定时的执行对key的删除操作。
- 「惰性删除」:每次只有再访问key的时候,才会检查key的过期时间,若是已经过期了就执行删除。
- 「定期删除」:每隔一段时间,就会检查删除掉过期的key。
「定时删除」对于「内存来说是友好的」,定时清理出干净的空间,但是对于「cpu来说并不是友好的」,程序需要维护一个定时器,这就会占用cpu资源。
「惰性的删除」对于「cpu来说是友好的」,cpu不需要维护其它额外的操作,但是对于「内存来说是不友好的」,因为要是有些key一直没有被访问到,就会一直占用着内存。
定期删除是上面两种方案的折中方案**,每隔一段时间删除过期的key,也就是根据具体的业务,合理的取一个时间定期的删除key**。
通过「最合理控制删除的时间间隔」来删除key,减「少对cpu的资源的占用消耗」,使删除操作合理化。
RDB和AOF 的淘汰处理
在Redis中持久化的方式有两种RDB和AOF,具体这两种详细的持久化介绍,可以参考这一篇文章[面试造飞机系列:面对Redis持久化连环Call,你还顶得住吗?]。
在RDB中是以快照的形式获取内存中某一时间点的数据副本,在创建RDB文件的时候可以通过save和bgsave命令执行创建RDB文件。
「这两个命令都不会把过期的key保存到RDB文件中」,这样也能达到删除过期key的效果。
当在启动Redis载入RDB文件的时候,Master不会把过期的key载入,而Slave会把过期的key载入。
在AOF模式下,Redis提供了Rewite的优化措施,执行的命令分别是REWRITEAOF和BGREWRITEAOF,「这两个命令都不会把过期的key写入到AOF文件中,也能删除过期key」。
摘抄来自:https://mp.weixin.qq.com/s/1HSJ-ZYSZKLVLW6mNVm4fw